Para comprender bien el funcionamiento de un PC, tienes que conocer los tipos de arquitecturas de ordenador que existen. Un tema bastante desconocido, pero apasionante. En este artículo nos vamos a sumergir profundamente en él, para que puedas conocer todos los detalles.
¿Qué es un ordenador?
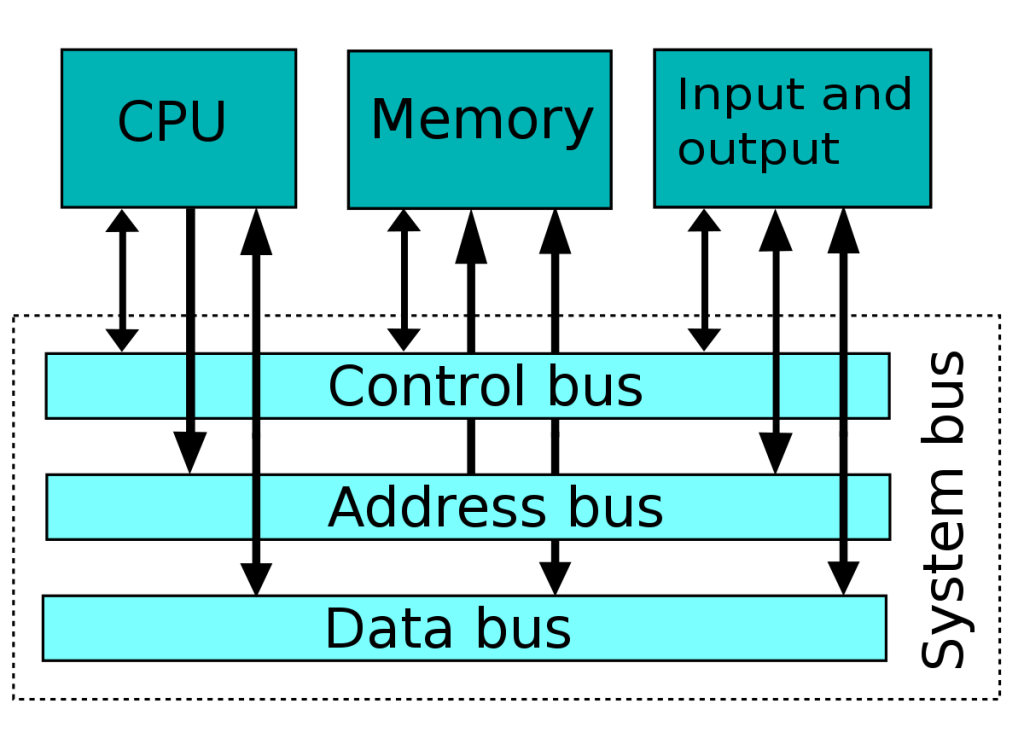
Antes de comenzar a descifrar los entresijos de las arquitecturas, primero es importante saber qué es un ordenador. Por definición, un ordenador es básicamente un conjunto compuesto por:
- Unidad Central de Procesamiento (CPU): también conocida como microprocesador, la CPU es el corazón del sistema. Su función es ejecutar las instrucciones de la ISA (Arquitectura de Conjunto de Instrucciones) y procesar los datos utilizados por el software para llevar a cabo tareas, incluyendo la ejecución de programas y el manejo del sistema operativo.
- Bus: el bus se refiere a los componentes que conectan diferentes partes del ordenador. Incluye variantes como el bus de datos, el bus de direcciones y el bus de control, cada uno con un papel específico en la transmisión y coordinación de información dentro del sistema.
- Memoria Principal: esta es generalmente la memoria RAM, donde se almacenan temporalmente los programas que se ejecutarán. Contiene los datos e instrucciones necesarios para procesos y que la CPU solicitará según lo requiera.
- Entrada y Salida (E/S): los ordenadores necesitan un método para recibir y enviar información. Los puertos de entrada y salida son esenciales para este propósito. Proporcionan los medios para interactuar con el sistema, permitiendo la comunicación con el usuario.
Ver también las partes de una CPU y su función
¿Qué es una arquitectura de ordenador?

Las arquitecturas de ordenador (macroarquitectura) son básicamente la organización lógica de los componentes de hardware en ordenadores. Esto engloba un conjunto de conceptos que definen cómo se detallan las características del hardware del ordenador y cómo interactúan entre sí. También se le conoce como arquitectura de CPU o diseño de sistema informático. La configuración de un ordenador, en términos arquitectónicos, establece su rendimiento, comportamiento y sus limitaciones.
El concepto de arquitectura asume distintos significados según el ámbito en el que se aplique. En el contexto de sistemas informáticos, generalmente se refiere a la lógica que subyace en un dispositivo de cómputo. Esta lógica abarca los fundamentos que guían la construcción de procesadores o chips, así como sus unidades y modos de operación. A lo largo de este artículo, resolveremos tus dudas acerca de la estructura de sistemas informáticos, abarcando su definición, ejemplos, beneficios y limitaciones, entre otros aspectos.
La arquitectura de ordenador resulta crucial debido a que establece cómo operará un ordenador y para qué propósitos puede emplearse. Concreta aspectos como el rendimiento, el consumo energético, el tamaño y el coste asociado a la máquina.
La estructura puede constituirse a partir de una combinación de hardware y software, o bien ser conformada exclusivamente por uno de estos elementos. La estructura de hardware se refiere a la materialización de la lógica subyacente en un ordenador, en tanto que la estructura de software se traduce en la materialización de las funcionalidades de un ordenador. Sin embargo, es importante resaltar que la estructura de software depende en gran medida de la estructura de hardware.
Cabe aclarar que los términos arquitectura de ordenador y arquitectura de software no son intercambiables y tienen significados fundamentalmente distintos. Mientras que la estructura de sistemas informáticos atañe a la lógica que rige un dispositivo físico, la estructura de software se relaciona con la lógica que guía las funcionalidades del dispositivo.
En definitiva, a partir de la estructura de sistemas informáticos se plantea el diseño y la construcción de estas máquinas. Por lo tanto, es crucial discernir entre los diferentes componentes que la componen, así como los tipos de estructuras disponibles, ya que estos factores definirán el tipo de ordenador resultante, sus habilidades y su funcionalidad, entre otros aspectos.
¿Qué es una ISA?
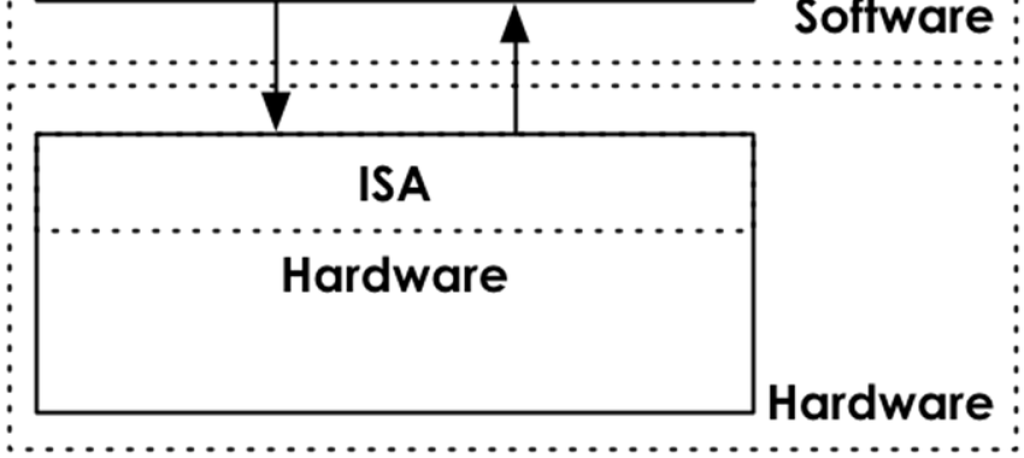
Es frecuente confundir arquitectura con ISA y con microarquitectura. En muchas ocasiones no se sabe muy bien cuál es la diferencia. Por eso, también vamos a repasar qué son estos otros conceptos y cómo podemos diferenciarlos. Y, lo que es más importante, cómo están relacionados.
Una ISA (Instruction Set Architecture) es una descripción detallada del conjunto de instrucciones que una arquitectura de ordenador específica puede ejecutar. En otras palabras, es el conjunto de instrucciones básicas que un procesador puede entender y ejecutar. Define cómo los programas y las instrucciones se comunican con la unidad central de procesamiento (CPU) y cómo se realizan las operaciones en el nivel más bajo de la arquitectura.
La ISA define las operaciones que el procesador puede realizar, los tipos de datos que puede manejar, los modos de direccionamiento para acceder a memoria y registros, y cómo se ejecutan las instrucciones. En resumen, es la interfaz entre el software y el hardware de un sistema informático.
Existen diferentes ISAs según la arquitectura del procesador, como RISC-V, x86 (utilizada por procesadores Intel y AMD), IA-64, ARM, SPARC, POWER ISA, MIPS, entre otras muchas. Cada ISA tiene su propio conjunto único de instrucciones y características, lo que influye en el rendimiento, la eficiencia y las capacidades de un procesador y, en última instancia, de un ordenador completo.
Quizás también te interese conocer si un único procesador puede ejecutar varias ISAs diferentes
Lenguaje ensamblador (ASM) y código máquina
Íntimamente relacionados con la ISA están el lenguaje ensamblador y el código máquina son conceptos relacionados con la programación de bajo nivel de una CPU:
- Lenguaje ensamblador: es un lenguaje de programación de bajo nivel que se encuentra entre el lenguaje de máquina y los lenguajes de programación de alto nivel. Está diseñado para ser más legible y comprensible por los humanos que el código máquina, pero todavía representa directamente las instrucciones y operaciones que la CPU puede entender. En lugar de utilizar códigos binarios y hexadecimales como el código máquina, el lenguaje ensamblador emplea mnemónicos y abreviaturas para cada una de las instrucciones de la ISA soportada, registros, tipos de datos, etc. El lenguaje ensamblador permite a los programadores escribir programas de una manera más clara y estructurada que el código máquina, pero aún así está muy cerca del nivel de hardware y requiere un conocimiento detallado de la arquitectura del procesador en uso.
- Código Máquina: es el lenguaje nativo del hardware. Consiste en secuencias de números binarios (0s y 1s) que representan las instrucciones que la CPU puede ejecutar directamente. Cada operación, como suma, resta o transferencia de datos, tiene su propia codificación en código máquina. El código máquina es el único lenguaje que la CPU puede ejecutar directamente, ya que es la forma en que comprende las operaciones y acciones. Sin embargo, debido a su naturaleza de ceros y unos, es difícil de leer y entender para los humanos. Es por eso que se desarrollaron el lenguaje ensamblador y los lenguajes de programación de alto nivel, para proporcionar interfaces más amigables para los programadores.
Es decir, la ISA está representada en forma de lenguaje de programación con el lenguaje ensamblador o ASM. Mientras qu éste debe traducirse a código máquina, o binario, para que pueda ser cargado en la memoria y ser procesado por la CPU.
¿Qué es una microarquitectura?
La microarquitectura de la CPU, también conocida como µarch, representa la implementación específica de la ISA (Instruction Set Architecture) en un procesador. La forma en que las instrucciones se ejecutan y qué tipos de instrucciones o datos son admitidos dependen de esta implementación. La microarquitectura engloba diversas áreas de la CPU y las tecnologías que puede emplear. Por ejemplo:
- Tipo de unidad de control y microcódigo: en el pasado, algunos procesadores utilizaban unidades de control cableadas, más rápidas y eficientes. Sin embargo, la mayoría de los procesadores actuales usan unidades más complejas y programables. Esto afecta la cantidad de instrucciones que la CPU puede interpretar, incluida la aceptación de la ISA completa o solo algunas instrucciones (con o sin extensiones). El microcódigo, que puede actualizarse, es parte de esta unidad.
- Memoria caché: la microarquitectura influye en el tamaño, tipo y jerarquía de la memoria caché. Esto tiene como objetivo agilizar el acceso a la memoria y reducir el impacto de la latencia en la memoria principal o el sistema E/S. Decisiones sobre la memoria caché incluyen aspectos como el nivel de caché último (LLC), la cantidad de niveles de caché, las unidades de traducción de direcciones (TLB), tipos de memoria, capacidad, organización dividida o unificada, frecuencia de reloj, entre otros.
- Pipeline: la mayoría de las CPUs modernas utilizan el concepto de canalización, dividiendo la ejecución en varias etapas. Esto permite procesar múltiples instrucciones en paralelo. La profundidad de la pipeline influye en esta capacidad.
- Unidades de ejecución: decide la cantidad y el tipo de unidades funcionales para ejecutar instrucciones, como ALUs, FPUs, AGUs, MULs, MACs, etc. Estas unidades pueden estar diseñadas para datos enteros o en coma flotante, y esto diferencia a procesadores escalares de superescalares.
- Ejecución especulativa: muchos procesadores modernos utilizan la ejecución especulativa, que permite ejecutar instrucciones antes de conocer el resultado de una bifurcación. Se emplean técnicas de predicción y unidades de predicción para maximizar la tasa de aciertos y minimizar las penalizaciones por fallos.
- Orden de ejecución: las CPUs pueden tener ejecución en orden o fuera de orden. Esta última es más común en CPUs de alto rendimiento. Permite procesar instrucciones con datos disponibles, aunque no sigan el orden secuencial del programa.
- Renombre de registros: en microprocesadores de alto rendimiento, se puede emplear el renombre de registros, donde se abstrae la relación entre registros lógicos y físicos. Esto permite eliminar algunas dependencias de datos.
- Multiprocesamiento y multihilo: puede ser diseñada para admitir múltiples núcleos en un solo chip (multicore) o múltiples chips en un sistema (multiprocesamiento). También se pueden implementar técnicas de multihilo, como SMT, para aumentar el rendimiento en la ejecución de instrucciones.
Como puedes comprobar, la microarquitectura de una CPU tiene un impacto significativo en su rendimiento y características. Las decisiones tomadas en estas áreas influyen en cómo se ejecutan las instrucciones y cómo se aprovechan las capacidades de la CPU. Cada microarquitectura puede estar adaptada a una ISA específica, y varias implementaciones pueden existir para la misma ISA, cada una con sus propias características y optimizaciones.
Compatibilidad
Como mencioné previamente, la microarquitectura de una CPU representa una implementación específica de una ISA, lo que implica que para una misma ISA podría haber diversas implementaciones distintas. En el caso de la ISA AMD64 o EM64T, comúnmente denominada x86-64, existen múltiples microarquitecturas desarrolladas por diversas empresas, como AMD, Intel, Zhaoxin (VIA Technologies), Hygon Dhyana (licencia Zen1 de AMD), entre otras. Incluso dentro de una misma empresa, se pueden suceder generación tras generación de microarquitecturas en busca de mejoras de rendimiento y características.
Por ejemplo, en el ámbito de AMD y su ISA AMD64, se encuentran microarquitecturas como Zen, K10, K8, Zen 4, cada una con sus particularidades.
Naturalmente, también existen microarquitecturas que no son compatibles con ciertas ISAs, y en su lugar, están asociadas a otras ISAs distintas. Por ejemplo, un chip diseñado para la ISA ARM (A64), como el Apple A15 Bionic con microarquitectura Avalanche+Blizzard, no podría ejecutar binarios compilados para x86 ni para otras ISAs distintas. Esto hace que ejecutar software destinado a una ISA diferente en una máquina con una ISA incompatible sea un desafío, a menos que se utilicen emuladores como QEMU o Rosetta 2.
Incluso un microprocesador que pertenece a la misma ISA no asegura ser completamente compatible con todas las instrucciones disponibles (puede estar diseñado para un subconjunto) o con las extensiones que podrían existir. Por ejemplo, no todos los procesadores son compatibles con la extensión de instrucciones AVX512. Esto demuestra que el rendimiento de un software compilado para una misma arquitectura puede variar entre diferentes CPUs. Por ejemplo, un programa compilado para funcionar en una Raspberry Pi (ARM) no funcionaría en un Apple M1 (ARM), y viceversa.
Cuando se compila software, generalmente se opta por una aproximación genérica sin optimizaciones específicas para una microarquitectura en particular. Esto asegura la compatibilidad con la mayor cantidad de procesadores posible. Aunque un chip de AMD, por ejemplo, carezca de ciertas instrucciones o extensiones, aún podrá ejecutar el software de manera competente, aunque quizás requiera más instrucciones para hacerlo. Sin embargo, una compilación optimizada específicamente para una microarquitectura particular puede mejorar significativamente el rendimiento, al aprovechar todas las instrucciones disponibles.
Conclusión y diferencias
Es crucial evitar confundir entre sí la microarquitectura de una CPU, la arquitectura o ISA (Instruction Set Architecture), y el sistema en su totalidad o macroarquitectura. A pesar de que estos términos pueden parecer similares, presentan distinciones fundamentales entre ellos:
- Macroarquitectura o diseño del sistema: engloba el diseño integral de todo el sistema informático, no limitándose únicamente a la CPU, sino abarcando otros componentes esenciales como el bus, el controlador de memoria, la memoria principal, unidades de procesamiento adicionales que colaboran con la CPU, controladores, sistema de Acceso Directo a Memoria (DMA), puertos de Entrada y Salida (E/S) para periféricos, y otros elementos que constituyen la placa base.
- ISA: hace referencia a las instrucciones que la CPU es capaz de comprender y ejecutar. Además, define aspectos como el tamaño de palabra, la cantidad de registros disponibles, los modos de direccionamiento de memoria y el formato de los datos manipulables. Está estrechamente vinculado al lenguaje ensamblador, dado que los mnemónicos empleados en las instrucciones son también utilizados en este lenguaje de bajo nivel (por ejemplo: ADD, SUB, MUL, …).
- Microarquitectura u organización: consiste en una implementación específica de una ISA. Esto implica la representación concreta de las vías de datos, las unidades de ejecución, los registros bancarios, los buses y otros componentes. Esta microarquitectura se traduce en un diseño lógico y posteriormente en un diseño físico o electrónico, que se materializa en el circuito integrado de la CPU.
Además, existe otro concepto conocido como UISA o μISA, que se refiere a Microcode Instruction Set Architecture (Arquitectura de Conjunto de Instrucciones de Microcódigo), aunque profundizar en este concepto excede el alcance de esta explicación.
Tipos de arquitecturas de ordenador
Ahora vamos a ver los tipos de arquitecturas de ordenador desde diferentes perspectivas:
Según su macroarquitectura
Entre los tipos de macorarquitecturas, o arquitecturas de ordenador, tenemos los siguientes:
Dataflow o flujo de datos
En el paradigma de la arquitectura de flujo de datos, los datos fluyen a través de diversas etapas de cálculo. Aquí, los resultados generados por un cálculo son empleados como entradas para otros cálculos. Esta estructura paralela se caracteriza por la transferencia de datos entre las distintas etapas de procesamiento. Los cálculos se efectúan en simultáneo utilizando una red de procesadores, una interconexión y algún tipo de almacenamiento.
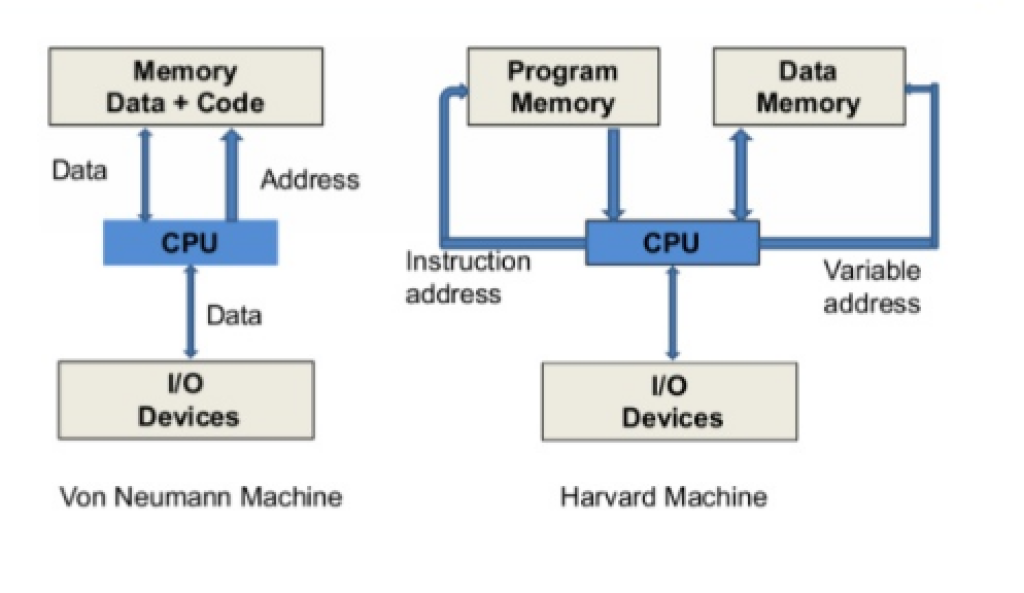
von Neumann
La arquitectura von Neumann se rige por un enfoque secuencial en el cual los cálculos se ejecutan en un orden lineal. Las operaciones se llevan a cabo de manera secuencial y se basan en una unidad central de procesamiento (CPU), una memoria y dispositivos de entrada-salida. La CPU se equipa con registros de instrucciones y datos. La memoria, que almacena instrucciones y datos durante el proceso, actúa como dispositivo de almacenamiento. Los dispositivos de entrada-salida, que incluyen elementos como teclados, pantallas e impresoras, se emplean para interactuar con el entorno exterior.
Harvard
La arquitectura Harvard es una variante adaptada de la arquitectura von Neumann. Esta modalidad dispone de dos memorias separadas: una para albergar las instrucciones del programa y otra destinada a los datos.
Harvard modified
La arquitectura Harvard modificada fusiona características de la arquitectura de flujo de datos y la arquitectura Harvard. Bajo este esquema, coexisten una memoria de programa y una memoria de datos que interactúan en la ejecución de los cálculos.
Según la ISA y la densidad de instrucciones
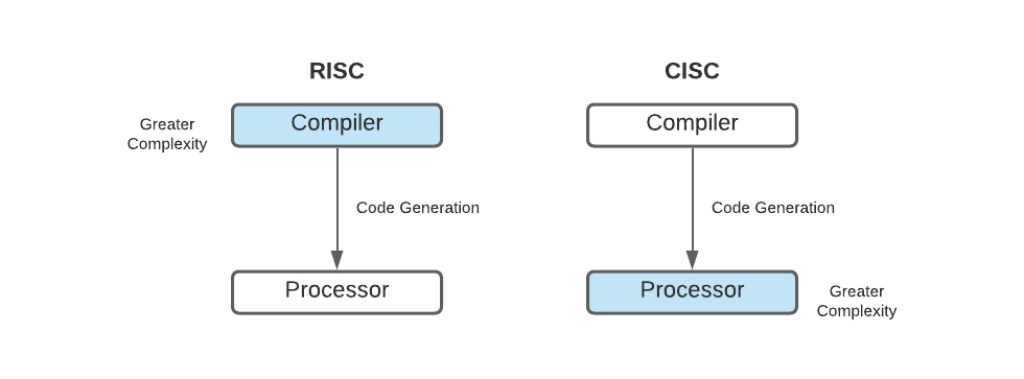
Si atendemos al tipo de ISA que tenemos, especialmente a la densidad de instrucciones y a cómo son estas instrucciones, podemos diferenciar entre arquitecturas:
CISC (Complex Instruction Set Computer)
Dentro del espectro de las arquitecturas, encontramos el modelo CISC, caracterizado por su conjunto extenso de instrucciones que abarcan operaciones complejas y variadas en la memoria, acompañadas de diversos modos de direccionamiento. Esta concepción conlleva a una unidad de procesamiento intrincada de construir, equipada con unidades de control basadas en microcódigo y un número reducido de bancos de registros de propósito general. Se destaca por su alta abstracción entre software y hardware, tiempos de programación eficientes y programas compactos. Ejemplos de esta índole son las arquitecturas IBM z/Architecture, x86 (IA-16, IA-32) y Motorola 68k.
RISC (Reduced Instruction Set Computer)
En el otro extremo se ubica el paradigma RISC, que opta por un repertorio de instrucciones homogéneas y sencillas, con un alcance reducido. Esta aproximación favorece tiempos de desarrollo más cortos, incrementa las perspectivas de escalabilidad de rendimiento y presenta unidades más eficaces con múltiples bancos de registros generales y una cantidad limitada de modos de direccionamiento. Aunque presenta la complejidad añadida de la compilación, propicia programas más amplios, ofrece baja abstracción entre software y hardware, y requiere mayor tiempo de programación. Ejemplos notables de esta categoría son las arquitecturas IBM POWER, SPARC, Arm y RISC-V.
Híbrido (RISC-like)
En el panorama actual, las diferencias entre RISC y CISC se han disipado. Por ejemplo, los procesadores de Intel y AMD adoptan instrucciones CISC que son luego traducidas en microoperaciones más simples y cercanas a RISC. Un enfoque similar fue empleado por AMD al construir su procesador K5 basado en la arquitectura RISC 29k, con una traducción de instrucciones x86. También, los RISC «puros» como Arm han incorporado algunas características de CISC, como extensiones numerosas de instrucciones. Algo parecido hizo Intel en su Pentium Pro en adelante. Actualmente, tanto Intel como AMD siguen con este diseño híbrido en sus nuevos procesadores, empleando microops al estilo RISC para descomponer sus instrucciones CISC x86. Es decir, se necesita un sistema de traducción en el front-end del procesador…
VLIW (Very Long Instruction Word)
Aunque algunos autores lo consideran fuera de este conjunto de arquitecturas, es pertinente incluirlo aquí. VLIW se configura con instrucciones muy extensas pero de cantidad limitada. Esto simplifica el hardware, pero dificulta el software, ya que requiere un compilador complejo. Los procesadores Crusoe y Efficeon de Transmeta ilustran esta arquitectura, en la cual Linus Torvalds, en sus inicios en Silicon Valley, trabajó para desarrollar Code Morphing, un software que traduce instrucciones x86 a VLIW y hace que este procesador sea compatible con los de Intel y AMD.
MISC (Minimal Instruction Set Computer)
Otra variante consiste en MISC, con un número escaso de instrucciones. A diferencia de otras, aquí se suele utilizar una pila para almacenar operandos en lugar de registros, simplificando el diseño. Un caso ilustrativo es el Transputer de INMOS.
ZISC (Zero Instruction Set Computer)
Esta propuesta inusual se caracteriza por carecer de instrucciones tradicionales. Sin embargo, pocas arquitecturas ZISC han tenido éxito, y un ejemplo del pasado es el ZISC35 de IBM.
SISC (Specific Instruction Set Computer)
El modelo SISC presenta un conjunto de instrucciones sumamente reducido y optimizado para una tarea específica.
VISC (Virtual Instruction Set Computer)
VISC, una arquitectura atípica introducida por Soft Machines, implementa núcleos virtuales sobre la infraestructura de hardware.
DISC (Dynamic Instruction Set Computer)
La arquitectura DISC permite la modificación dinámica del conjunto de instrucciones según las necesidades del programa. Esto demanda el uso de FPGAs reprogramables y trata a las instrucciones como módulos.
NISC (No Instruction Set Computer)
NISC se empleada para crear dispositivos altamente eficientes y aceleradores de hardware.
EDGE (Explicit Data Graph Execution)
Con la meta de solventar los cuellos de botella y mejorar a las CISC, EDGE alberga un conjunto sustancial de instrucciones individuales en un grupo denominado hiperbloque, ejecutado paralelamente de manera sencilla. Esta estructura se ha empleado en unidades como los TRIPS.
OISC (One Instruction Set Computer) o URISC (Ultimate RISC)
Una OISC solo emplea una instrucción, sin limitar la variedad de software ejecutable. Aunque se usa con fines educativos, no se conoce ninguna implementación actual.
Quantum o cuántico
Un procesador cuántico es un tipo de dispositivo de procesamiento que utiliza los principios de la mecánica cuántica para realizar cálculos y resolver problemas de manera excepcionalmente rápida en comparación con los ordenadores clásicos. Aprovecha los qubits, que son unidades de información cuántica, para representar y manipular datos en estados superpuestos y entrelazados, lo que permite realizar múltiples cálculos simultáneamente. Debido a esta capacidad de procesamiento paralelo y a fenómenos cuánticos como la superposición y la interferencia cuántica, los procesadores cuánticos tienen el potencial de resolver ciertos tipos de problemas complejos, como la factorización de números grandes y la simulación de sistemas cuánticos, mucho más eficientemente que los ordenadores convencionales. Sin embargo, los desafíos técnicos para crear y mantener qubits estables y coherentes limitan la escala y el rendimiento de los procesadores cuánticos en la actualidad.
Según el tamaño de palabra

En relación al número de bits (tamaño de palabra) con los que un ordenador puede interactuar, se observa una variedad de diseños que van desde 1-bit, 2-bit, 4-bit, 8-bit, 16-bit, 32-bit, 64-bit, hasta 128-bit, 256-bit, 512-bit, entre otros. En muchos casos, los diseños actuales son híbridos, combinando diversas capacidades. Por ejemplo, los chips AMD64/EM64T presentan compatibilidad retrógrada, permitiendo la ejecución de software de 64-bit, 32-bit y 16-bit. Además, incorporan extensiones de 128-bit, 256-bit, y más.
Este enfoque puede referirse al tamaño de los datos que las unidades funcionales pueden manejar o al tamaño de la dirección de memoria, determinando la cantidad de memoria accesible. Un ejemplo sería que con 32-bit se puede abordar hasta 232 direcciones de memoria, mientras que con 64-bit se expande a 264 direcciones de memoria únicas.
Para comprender mejor la evolución histórica, aquí se presentan ejemplos notables de diversos tamaños:
- 1-bit: encarnado en el Motorola MC14500B.
- 4-bit: encuentra representación en el Intel 4004 y el HP Saturn, por ejemplo.
- 8-bit: se puede observar en procesadores como el Zilog Z80, Intel 8008 y Atmel AVR.
- 16-bit: presente en el Intel 8086, DEC PDP-11, Zilog Z8000, entre otros.
- 32-bit: identificado en procesadores como Pentium, Pentium II, Pentium III, Pentium 4, K5, K6, Athlon, Athlon XP, y más.
- 64-bit: en procesadores como Athlon64, Phenom, Sempron, Turion64, Ryzen, EPYC, Intel Core, Intel Xeon, Opteron, además de las variantes basadas en Arm AArch64, SPARCv9, IBM POWER, MIPS64, y otros.
- 128-bit: algunos procesadores de Intel y AMD incorporan extensiones de instrucciones en este tamaño.
- 256-bit: similar al caso anterior, con diseños como el Transmeta Efficeon empleando esta longitud.
- 512-bit: semejante a los casos previos, incluyendo extensiones como las SIMD AVX-512 de Intel (recientemente también incorporadas en AMD Zen 4). Aunque la unidad es de 64-bit, estas extensiones permiten que ciertas unidades funcionales, como las FPUs dedicadas a instrucciones largas, puedan operar con estos tamaños. Esto se logra mediante la utilización de varios registros enlazados, lo que habilita el funcionamiento como unidades vectoriales operando sobre múltiples datos.
- Bit slicing: es una técnica para construir un procesador a partir de módulos de procesadores de menor ancho de bits, con el propósito de aumentar la longitud de palabra, teóricamente para crear una unidad central de procesamiento (CPU) de n bits arbitrarios. Cada uno de estos módulos componentes procesa un campo de bits o «rebanada» de un operando. Los componentes de procesamiento agrupados tendrían la capacidad de procesar la longitud completa de palabra elegida en un diseño de software dado. El bit slicing prácticamente dejó de utilizarse debido a la llegada de los microprocesadores. Recientemente se ha utilizado en unidades aritmético-lógicas (ALUs) para computadoras cuánticas y como técnica de software, por ejemplo, para la criptografía en CPUs x86.
En la actualidad, con las cargas de trabajo para IA (Inteligencia Artificial), los datos con formatos como FP8, FP16, etc., están cobrando mayor importancia, ya que estas cargas de trabajo operan con estos pequeños datos en vez de con datos de longitudes grandes.
Hay que decir que actualmente muchos procesadores pueden trabajar en varios modos. Por ejemplo, los x86 se conocen por su retrocompatibilidad, pudiendo trabajar en modo 16-bit, 32-bit y 64-bit actualmente. Además, dentro también suelen tener FPUs especiales o ALUs especiales para trabajar de forma vectorial, es decir, con instrucciones tipo SIMD que pueden ser de 128-bit, 256-bit, o 512-bit. Lo mismo ocurre con otros procesadores como los ARM, etc., por tanto, en la actualidad no es tan sencillo catalogar un procesador según este criterio, ya que puede operar con varios tamaños…
Según la taxonomía de Flynn
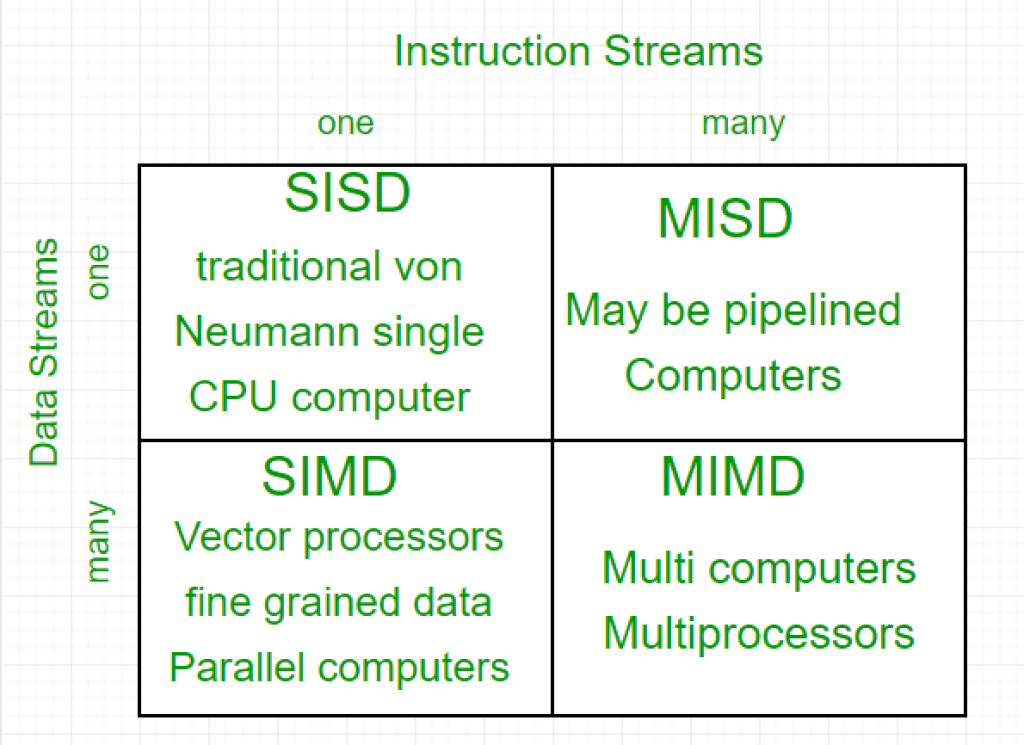
Dentro de las clasificaciones de arquitectura basadas en el paralelismo, es relevante mencionar cómo se estructuran las unidades de procesamiento según la taxonomía de Flynn:
SISD (Single Instruction, Single Data)
Este tipo de arquitectura utiliza una sola instrucción y un único conjunto de datos en un momento dado, careciendo de cualquier forma de paralelismo. Aunque es la más elemental, también es la menos eficiente en términos de rendimiento. Aunque fue más común en el pasado, actualmente su uso es limitado.
SIMD (Single Instruction, Multiple Data)
uí, se emplea una única instrucción para operar sobre múltiples conjuntos de datos. Esta arquitectura es prominente en procesadores vectoriales, GPUs y muchas CPUs modernas, entre otros.
MISD (Multiple Instructions, Single Data)
Suelen encontrarse en unidades Tensor y otros procesadores especializados. En este caso, diversas instrucciones se aplican a un solo conjunto de datos.
MIMD (Multiple Instructions, Multiple Data)
En este escenario, varios flujos de instrucciones operan sobre múltiples flujos de datos. Representa la forma más avanzada de paralelismo, siendo usada en máquinas de Alto Rendimiento (HPC). Ejemplos incluyen el chip SW26010 de Sunway y el IBM Cell, entre otros.
Según la homogeneidad
Según la homogeneidad de sus unidades de procesamiento, podemos tener sistemas homogéneos, como la mayoría de los convencionales, o heterogéneos, como se está convirtiendo en una tendencia en la actualidad.
Arquitectura Homogénea
En este tipo de arquitectura tenemos unidades homogéneas en cuanto a procesamiento. Por ejemplo, un microprocesador o CPU es una unidad homogénea, donde todos sus núcleos de procesamiento son idénticos y trabajan bajo una misma ISA. Esto tiene sus ventajas, como tener un software más sencillo para ejecutarse de forma uniforme en estas unidades, en cambio, también tiene sus limitaciones en cuanto a rendimiento y eficiencia energética.
Arquitectura Heterogénea
En estos sistemas tenemos arquitecturas variadas, heterogéneas. Es decir, las unidades de cómputo para propósito general no son iguales. Ya sea porque tenemos un microprocesador con núcleos diferentes, como es el caso de los ARM y su big.LITTLE o los últimos Intel con sus P-core y E-core, o porque se esté usando otros aceleradores de propósito general como puede ser una GPGPU, aceleradores específicos como las unidades neuronales, etc.
Con ello se consigue mejoras en el rendimiento y en la eficiencia, además de poder acelerar cargas específicas. En cambio, también tiene sus complicaciones, como la programación del software, que se vuelve más compleja para poder aprovechar estas unidades heterogéneas.
Algunos ejemplos de unidades que pueden estar presentes en un SoC o ASIC heterogéneo son coprocesadores, GPU, DSP, PPU, VPU, TPU, Network processor, Secure cryptoprocessor, Baseband processor, etc.
Según el recuento de núcleos

También podemos diferenciar entre las arquitecturas con un solo core o núcleo y las que tienen varios de ellos. En este sentido podemos decir que existen:
- Single-Core: como su nombre lo indica, tiene un solo núcleo de procesamiento en el chip. Esto significa que solo puede ejecutar una tarea o instrucción a la vez. Aunque puede ejecutar instrucciones a alta velocidad, no puede manejar múltiples tareas en paralelo. Estos procesadores eran comunes en los ordenadores más antiguas y en dispositivos más simples.
- Multi-Core: tiene múltiples núcleos de procesamiento en un solo chip. Cada núcleo es un núcleo de procesador independiente que puede ejecutar sus propias instrucciones y tareas. Esto permite que el procesador multi-core maneje múltiples tareas simultáneamente, ya que cada núcleo puede trabajar en una tarea diferente. Los procesadores multi-core son comunes en los ordenadores de hoy en día y permiten un mejor rendimiento en tareas que pueden aprovechar el paralelismo. Por ejemplo, podemos encontrar DualCore, QuadCore, OctaCore, etc., dicho de otro modo, podrían ir desde los 2 núcleos hasta los 16 o más.
- Procesador Manycore: es una versión avanzada de los procesadores multi-core, con un número aún mayor de núcleos (suelen denominarse tiles, y generalmente son núcleos pequeños y eficientes, como los ARM) en un solo chip. La distinción entre procesadores multi-core y manycore es un tanto borrosa y varía según el contexto. Sin embargo, en general, se considera manycore a un chip con un gran número de núcleos, a menudo en el rango de decenas o incluso cientos de núcleos. Estos procesadores se utilizan en aplicaciones que requieren un alto grado de paralelismo, como la simulación, el procesamiento de imágenes, la inteligencia artificial y la computación de alto rendimiento. En este caso hablamos de unidades que pueden tener centenares o miles de núcleos…
No confundir esto con el multiprocesamiento (MP) es la utilización de dos o más unidades centrales de procesamiento (CPUs) dentro de un único sistema informático. El término también se refiere a la capacidad de un sistema para admitir más de un procesador o la habilidad de asignar tareas entre ellos. Es decir, sistemas con dos o más sockets por placa base…
A veces no es tan sencillo como simplemente replicar cada núcleo en el silicio, ya que estos sistemas con más de un núcleo necesitan cambios arquitectónicos importantes, como la creación de un bus o malla para interconectar estas unidades, así como nuevas formas de compartir la caché, mantener la coherencia, etc.
Según el nivel de paralelismo
Finalmente, existen otros enfoques de arquitectura que se orientan según el grado de paralelismo:
Escalar
Se trata de una CPU simple, sin redundancias en las unidades funcionales. Así eran la mayoría de procesadores antes de los 90, cuando comenzaron a florecer los superescalares.
Segmentada (pipeline)
En esta perspectiva, la pipeline de la unidad de procesamiento fragmenta el proceso de ejecución en secciones independientes que pueden funcionar simultáneamente. Esto permite que las instrucciones no tengan que completar todas las etapas antes de que otra pueda iniciar.
Superescalar
Esta arquitectura persigue intensificar el paralelismo a nivel de instrucción al multiplicar las unidades de ejecución, como la ALU y la FPU. Esto posibilita la ejecución simultánea de múltiples instrucciones.
Multihilo
Las arquitecturas de multihilo incorporan técnicas para manejar más de un hilo o flujo de instrucciones. Ejemplos incluyen el SMT 2-way, 4-way, 8-way, etc. Esto habilita el procesamiento simultáneo de dos hilos. También puede adoptar una modalidad temporal, donde el procesador alterna entre hilos para procesarlos en intervalos.
OoOE
La Ejecución Fuera de Orden (OoOE u Out Of Order Execution) es otro paradigma o algoritmo de arquitectura que busca acelerar la ejecución. En lugar de seguir la secuencia del programa para ejecutar instrucciones, estas se procesan desordenadamente según la disponibilidad de datos. Luego, se reorganizan en un búfer para obtener el resultado correcto. Por ejemplo, los procesadores más antiguos operaban en orden secuencial. Intel también creó un diseño más reciente basado en este enfoque, como el Atom, que evolucionó hacia modelos más avanzados. Actualmente, muchos procesadores de alto rendimiento se adhieren a este esquema.
Ejecución perezosa (Lazy)
La ejecución perezosa es lo opuesto a la ejecución ansiosa y no implica especulación. La incorporación de la ejecución especulativa en implementaciones del lenguaje de programación Haskell, un lenguaje perezoso, es un tema actual de investigación.
Ejecución especulativa
La ejecución especulativa es una técnica de optimización en la que un sistema informático realiza una tarea que puede que no sea necesaria. Se realiza el trabajo antes de saber si realmente es necesario, con el fin de evitar un retraso que ocurriría si se hiciera el trabajo después de saber que es necesario. Si resulta que el trabajo no era necesario después de todo, la mayoría de los cambios realizados por el trabajo se deshacen y los resultados se ignoran.
El objetivo es proporcionar más concurrencia si hay recursos adicionales disponibles. Esta aproximación se emplea en varias áreas, incluida la predicción de bifurcaciones en procesadores en pipelínea, la predicción de valores para explotar la localidad de valores, la prelectura de memoria y archivos, y el control de concurrencia optimista en sistemas de bases de datos.
Los microprocesadores segmentados modernos utilizan la ejecución especulativa para reducir el costo de las instrucciones de bifurcación condicional mediante esquemas que predicen (branch prediction) el camino de ejecución de un programa basándose en el historial de ejecuciones de bifurcaciones. Con el fin de mejorar el rendimiento y la utilización de los recursos informáticos, las instrucciones pueden programarse en un momento en que aún no se ha determinado que sea necesario ejecutarlas, antes de una bifurcación.
Por supuesto, la ejecución especulativa, cuando el predictor acierta, permite tener los resultados procesados con mayor velocidad, ya que se ejecutan al instante. En cambio, cuando tiene un fallo en la predicción, implicará vaciar el cauce de la pipeline y volver a empezar a procesar con la rama o camino correcto. Por tanto, un fallo también implica pérdida de ciclos de reloj… Es por ello que cada vez se está tratando de mejorar más la capacidad de acierto de estas unidades, incluso usando redes neuronales.
Además, ese no es el único problema, también tenemos lo que se conoce como «transient execution CPU vulnerability». Las vulnerabilidades de ejecución transitoria en la CPU son vulnerabilidades en un sistema informático en las que se aprovecha una optimización de ejecución especulativa implementada en un microprocesador para filtrar datos secretos a una parte no autorizada. El ejemplo clásico es Spectre, que dio nombre a la categoría de ataques de canal lateral (side-channel attacks) conocidos como ataques de caché, pero desde enero de 2018 se han identificado muchas vulnerabilidades de ataques de caché diferentes.
En la práctica, la mayoría de los microprocesadores contemporáneos adoptan una combinación de estos enfoques y tecnologías. Por ejemplo, un AMD Ryzen posee elementos de SMT, OoOE, superescalar, pipeline, es de 64-bit y admite extensiones de 128-bit y 256-bit. Además, presenta una arquitectura híbrida que combina principios RISC con la traducción de instrucciones CISC. También puede operar en modo SIMD, entre otras características.
Cellular
La arquitectura celular es un tipo de arquitectura de ordenadores destacada en la computación paralela. Las arquitecturas celulares son relativamente nuevas, siendo el microprocesador Cell de STI (Sony Toshiba IBM) el primero en llegar al mercado. La Cellular lleva el diseño de la arquitectura multinúcleo a su conclusión lógica, al brindar al programador la capacidad de ejecutar numerosos hilos concurrentes dentro de un solo procesador. Cada ‘célula’ es un nodo de cálculo que contiene unidades de hilos, memoria y comunicación. La mejora de la velocidad se logra al explotar el paralelismo a nivel de hilos inherente en muchas aplicaciones.
El procesador Cell, que utiliza una arquitectura celular y contiene 9 núcleos, se utiliza en la PlayStation 3, 1 núcleo PowerPC principal y 8 coprocesadores. Otra arquitectura celular destacada es Cyclops64, una arquitectura masivamente paralela actualmente en desarrollo por IBM.
Las arquitecturas celulares siguen el paradigma de programación de bajo nivel, lo que expone al programador gran parte del hardware subyacente. Esto permite al programador optimizar en gran medida su código para la plataforma, pero al mismo tiempo dificulta el desarrollo de software.
Conclusión
Existen aún más tipos de arquitecturas, por ejemplo catalogadas según Tse-yun Feng, etc. Sin embargo, aquí tienes las más importantes que debes conocer. En cuanto a la pregunta de cuál es mejor o cuál peor, lo cierto es que depende de muchos factores. Además, los modernos sistemas suelen ser mezcla de varios de estos paradigmas, es decir, un procesador AMD, por ejemplo, tiene una arquitectura RISC-like de 64-bit, con extensiones de hasta 512-bit (AVX-512), y a su vez está canalizado (pipeline), es superescalar, con ejecución fuera de orden, y es multihilo…