
Usas una CPU y una GPU a diario, ya sea en tu PC, o en otros equipos como pueden ser los dispositivos móviles. La NPU es cada vez más frecuente en muchos SoCs, como los de los móviles para acelerar las cargas de inteligencia artificial, y ahora también se están implantando en microprocesadores para ordenadores. Pero… ¿sabes qué es el concepto SWAR? ¿No? Pues afecta a todas esas unidades…
¿Qué es SWAR?

SWAR (SIMD within a register), también conocida como packed SIMD, y a veces aparece en los die shots como «packet FPU», no es más que una técnica para realizar operaciones paralelas en datos contenidos en un registro del procesador. Como sabes ya, SIMD significa instrucción única, múltiples datos, es decir, una forma de realizar operaciones vectoriales, superando el tamaño de palabra de una unidad de procesamiento.
En la taxonomía de Flynn de 1972 categoriza SWAR como «procesamiento en pipeline».
Muchos procesadores modernos de propósito general tienen extensiones SIMD en su ISA. De esta forma pueden implementar un conjunto de registros y unidades de ejecución especiales para poderlas ejecutar. SWAR se refiere al uso de esos registros e instrucciones. Por ejemplo, podemos encontrar una CPU de Intel Core con extensiones SIMD como las MMX, SSE, AVX, etc., siendo todas estas extensiones instrucciones tipo SIMD o vectoriales, ya que al ejecutar una sola instrucción ejecutará una operación aritmeticológica en varios datos (o vector). Mientras el Intel Core es de 64-bit, mientras que unas AVX pueden ser de 128, 256 o 512-bit…
Por tanto, una arquitectura SWAR es aquella que incluye instrucciones explícitamente diseñadas para realizar operaciones paralelas (vectoriales) en datos (operandos) almacenados en unos registros especiales. En algunas ocasiones, la microarquitectura no tiene unidades preparadas para estas instrucciones SIMD, pero puede usar «trucos» o técnicas de compilación para poder procesarlas, como ocurría en el Intel Pentium (P6), que soportaba extensiones MMX.
Siguiendo con el ejemplo del Pentium I y las MMX, en este diseño se agregaron 8 nuevos registros a la arquitectura, conocidos como MM0 a MM7. Estos registros MMn podían albergar las instrucciones SIMD para la FPU x87. Estos registros eran realmente meros alias, y poseían un tamaño de 64-bit, mayor que el tamaño de palabra del Pentium I, que es de 32-bit. Por tanto, en estos registros se podía almacenar tanto un número de 64-bit como dos números enteros de 32-bit, cuatro de 16-bit, u ocho de 8-bit. Sin embargo, en este primer diseño, para evitar tener que modificar el sistema operativo, los programadores tenían que elegir entre trabajar en modo FPU o MMX, pero no los dos a la vez. Además, pasar de un modo a otro era bastante lento… Pese a todo esto, se puede considerar un diseño SWAR.
Historia
En los años 50 se introdujeron las operaciones de datos de subpalabra, es decir, particionar el tamaño de palabra en varios trozos como he explicado en el párrafo anterior. Esto fue idea de Wesley A. Clark. Esto puede considerarse como un precursor muy temprano de SWAR. Pero no sería hasta 1975, cuando en un artículo técnico de Leslie Lamport se habló de SWAR, concretamente en el artículo: «Procesamiento de múltiples bytes con instrucciones de palabra completa«.
Algunos de los primeros diseños de arquitectura en incluir el concepto SWAR fueron las extensiones DEC Alpha MVI, o las HP PA-RISC MAX, MIPS MDMX de Silicon Graphics Incorporated (SGI) y SPARC V9 VIS de Sun Microsystems. Todas ellas diseñadas para acelerar las cargas de trabajo multimedia, especialmente las tareas relacionadas con el vídeo, ya que eran las que más operaciones de este tipo necesitan. No obstante, también pueden servir para ayudar en procesamiento de imágenes, cifrado, procesamiento de rasters, CFD, aplicaciones científicas, etc.
En sus primeras etapas, estas instrucciones solo podían utilizarse a través de código ensamblador (ASM) escrito a mano. En la actualidad esto no es así, y se puede realizar directamente en la compilación, usando las opciones adecuadas del compilador. De hecho, en 1996, el profesor Hank Dietz de la Universidad de Purdue, asignó una serie de proyectos en los que los estudiantes de este curso para que crearan un compilador simple dirigido a MMX. El lenguaje de entrada era un dialecto de subconjunto de MPL de MasPar llamado NEMPL (Not Exactly MPL).
En el caso de los procesadores x86, el concepto SWAR no llegaría hasta la introducción de las extensiones multimedia MMX de Intel en 1996. Desde entonces, los procesadores de escritorio con capacidades de procesamiento paralelo SIMD se volvieron comunes, agregando también estas extensiones a otros rivales como los AMD. Luego llegarían otras, como las SSE de Intel, las 3D Now! de AMD, etc. También han llegado este tipo de extensiones a Arm, como es el caso de las SVE, etc.
Todas estas extensiones tenían diferencias significativas en la precisión de datos y los tipos de instrucciones admitidas, algunas pudiendo trabajar solo con enteros, otras también con coma flotante, pero todas con el objetivo de mejorar las cargas de trabajo de algún tipo.
SWAR y la IA
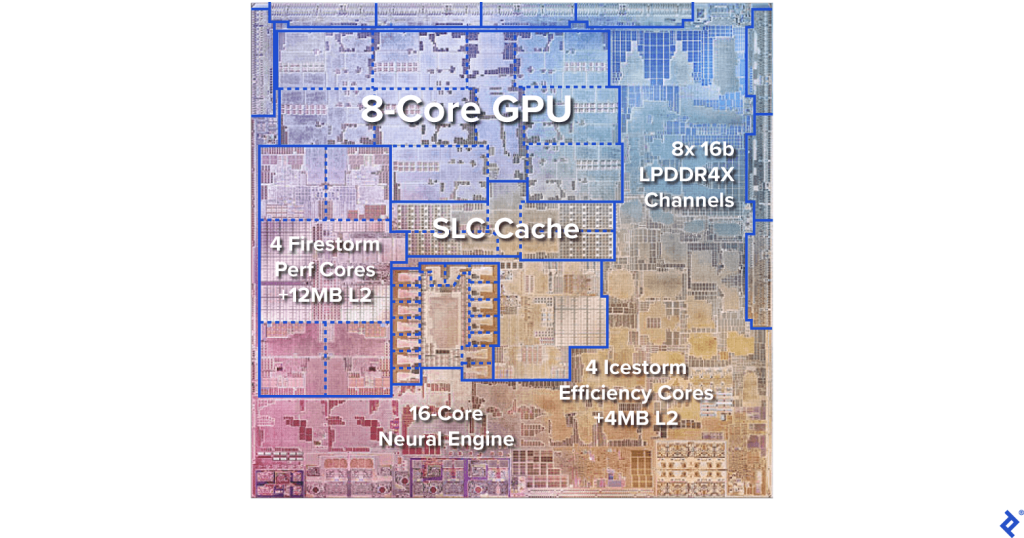
Los algoritmos de inteligencia artificial está cada vez más presentes en la computación de alto rendimiento (HPC), pero también en el día a día de muchos usuarios particulares. Por ejemplo, se suelen usar para mejorar las fotos en las cámaras de dispositivos móviles, para mejorar las imágenes en las Smart TVs, también en ciertas apps cotidianas, etc. Por eso, se han vuelto muy importantes las unidades dedicadas o aceleradores de IA, como es el caso de las NPU que ahora están incluyendo algunos diseños, como AMD Ryzen AI, Intel en sus Meteor Lake, Apple y sus Neural Engine, etc.
Estas cargas de IA suelen operar con datos de baja precisión, pero gran cantidad de ellos. Y en la actualidad, la mayoría de las ALU/FPU trabajan con una precisión de 64-bit. Para acelerar estos algoritmos, es necesario incorporar unidades de ejecución de menor precisión, como 16-bit, 8-bit e incluso 4-bit, en un procesador. Esto, a su vez, puede complicar la estructura del procesador central, por lo que se han separado en unidades aceleradoras o dedicadas como las NPUs. Así es como los ingenieros han evitado este error y han recurrido a la tecnología SIMD para estas unidades o para las GPUs usadas como aceleradores.
Por poner un ejemplo de este sentido, AMD lo hace es sus nuevas GPUs de última generación. Cada una de las unidades de ejecución FPU de 32-bit (FP32 o de precisión simple), que conforma las unidades SIMD de sus GPUs RDNA, es compatible con SIMD sobre registro. Esto significa que pueden subdividirse en cálculos sobre 16-bit (FP16, 8-bit (FP8) o 4-bit (FP4) según sea necesario en cada caso.
Por otro lado, NVIDIA lo hace de forma diferente, y en vez de usar las mismas unidades de cómputo para todo, como AMD, ha creado unas unidades de aceleración para los algoritmos de IA especiales: Tensor Cores. Estos Tensor Cores son como NPUs, y consisten en matrices sistólicas compuestas por FPUs de coma flotante de 16-bit interconectadas en una matriz tridimensional, de ahí su nombre de unidades Tensor. Aunque no son unidades SIMD como tal, cada una de sus FPUs admite SIMD sobre registro (SWAR), lo que les permite realizar el doble de operaciones con precisión de 8 bits y cuádruple de operaciones con precisión de 4 bits. Los Tensor Cores son fundamentales debido a su capacidad para acelerar operaciones muy empleadas en los videojuegos para mejorar la imagen, como la tecnología DLSS, etc.
Por supuesto, cuando las GPUs se usan para HPC, también pueden ser muy interesantes para cargas de trabajo de este tipo, como podría ser para aplicaciones como Chat GPT, etc.