
SVE son unas extensiones para la ISA ARM que han aparecido y de las que se está hablando mucho. De hecho, muchos expertos la ponen de ejemplo frente a AVX-512, ya que no implica todos los problemas que ha tenido Intel con ella. Por eso, aquí te mostraremos cómo trabaja esta extensión y todo lo que tienes que saber sobre ella.
¿Qué es SVE?
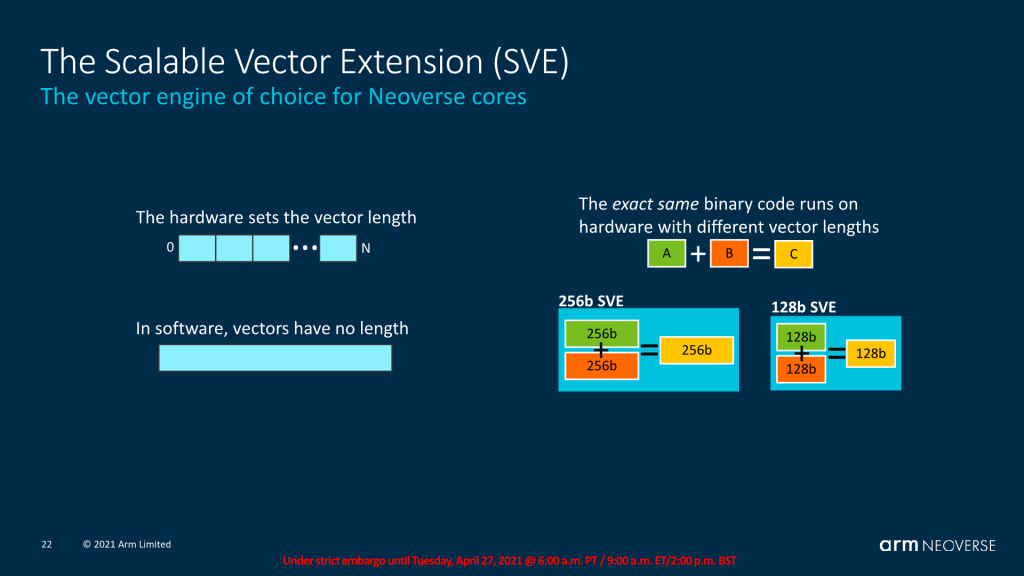
SVE (Scalable Vector Extensions) son unas extensiones de las instrucciones de la ISA ARM de tipo SIMD, es decir, vectoriales (no escalares). Esto significa que con solo una instrucción se puede operar sobre multiples datos a la vez.
Estas SVE fueron introducidas por ARM en 2016, y en 2019 llegaría la segunda generación de éstas, conocida como SVE2. Y no solo se pueden usar en los procesadores Arm Cortex-A y Cortex-X Series, también en otros diseñados por terceros, como puede ser el Fujitsu A64FX de la supercomputadora japonesa Fugaku, que llegó a ocupar el puesto 1 en la lista Top500, o en los Graviton 3 de AWS, y en la generación para servidores Neoverse V1.
De este modo, Arm espera que SVE y SVE2 sean el futuro de las SIMD para ARM y que ganen interés a medida que están disponibles, tanto a nivel de hardware que las implemente como a nivel de software que sea capaz de aprovechar estas extensiones para acelerar las cargas de trabajo.
Además, hay que decir que SVE se diferencia de otras extensiones SIMD en algo muy interesante, y es que aborda el problema al que conmúnmente se enfrentan estas extensiones, el de mantener múltiples rutas de código de vector de ancho fijo. Y lo hace con la posibilidad de usar vectores de longitud variable o escalable. Aquí radica una de sus mayores ventajas.
Esta longitud variable permite que los procesadores compatibles con diferentes capacidades SIMD no necesiten escribir, compilar y mantener múltiples rutas de código de ancho fijo. Por otro lado, para ayudar a su adopción, ARM ha proporcionado gran cantidad de información y guías para la implementación y aprovechamiento de estas SVE/2.
Por el momento, las implementaciones no han sido demasiadas. Pero sin duda van a ser importantes en los próximos años, aunque tampoco hay que perder de vista las extensiones vectoriales que preparan desde RISC-V, como las RVV, que también van a dar mucho que hablar, tanto en computación personal como en HPC.
SVE2

Las SVE2 por el momento están usando longitudes de 128-bit, al menos eso es lo que muestran los núcleos de procesadores que las han admitido. Este es el ancho mínimo para SVE, lo que significa que no verás grandes ventajas de SVE sobre NEON, que también tiene vectores de esa misma longitud.
Sin embargo, como he comentado anteriormente, estas extensiones son escalables, por lo que es fácil ir adoptando vectores más largos en el futuro con nuevas implementaciones de microarquitecturas. Esto significaría mejores importantes respecto a las primeras implementaciones actuales.
De hecho, se creía que Neoverse V2 podría pasar a usar SVE2 de longitud 256-bit, sin embargo, esto no fue así, y vuelve a emplear 128-bit de longitud. Parece que se han «atascado» en esa longitud en los núcleos actuales, para mantener quizás núcleos más pequeños y no tan complejos como si se implementasen longitudes mayores, con unidades de cálculo más complejas y grandes, además de banchos de registros de mayor longitud.
También vemos esa limitación en otros diseños, como el Cortex-X2. Y es que se requiere que todos los núcleos en estas arquitecturas heterogéneas (big.LITTLE) admitan el mismo ancho y tipo de instrucciones. Eso limita mucho la longitud de estas extensiones.
Desafortunadamente, como bien sabes, Arm no ha actualizado los núcleos más pequeños con tanta frecuencia como sus núcleos de mayor rendimiento. Es decir, los núcleos eficientes han estado algo más olvidados, y esto también limita a los núcleos de alto rendimiento por lo dicho en el párrafo anterior.
De momento, ampliar la longitud de SVE no parece una prioridad para Arm, pero estaría bien saber a qué pueden llegar estas extensiones en ARMv9 con SVE2 en su longitud máxima. Te en cuenta que puede escalar desde un mínimo de 128-bit hasta un máximo de 2048-bit, en saltos de 128-bit.
Es necesario destacar que tener SVE de longitudes largas, como 256-bit o más, no es algo inteligente para usar en dispositivos móviles o empotrados, donde se prima el consumo al rendimiento. Pero sí que es vital para acelerar otras cargas de trabajo pesadas, como las científicas en HPC. Ampliar las longitudes de SVE en dispositivos de bajo consumo sería cometer el mismo error que cometió Intel en su día con las AVX-512 para productos para el lado del cliente y no solo para servidores.
Sin embargo, aunque Arm no de el paso para habilitar vectores más allá de los 128-bit por el momento en sus núcleos de consumo en un corto plazo, es posible que otros diseñadores sí lo hagan, como el caso de Qualcomm/Nuvia, Annapurna Labs (AWS/Amazon) y Apple para sus propios chips de alto rendimiento. O casos como el sucesor del Fujitsu A64FX, denominado Monaka.
Como sabrás, Apple ya anunció que su SoC A15 Bionic no era compatible aún con ARMv9 y SVE2, y tampoco en sus primeros M-Series, así que habrá que esperar un poco más a nuevos lanzamientos. Lo que sí sabemos es que Apple ha agregado de forma silenciosa y sin dar información al respecto, su propio conjunto de instrucciones denominadas Apple AMX, en vez de SME. Esto ha sembrado dudas de si realmente están interesados en SVE o seguirán agregando sus propias instrucciones.
En definitiva, por el momento la adopción de SVE/SVE2 es lenta, y veremos si en el futuro vemos ampliaciones de éstas…
Simplicidad al máximo

Hay que destacar por otro lado otra cosa importante de SVE, y es que mientras que los vectores crecen en longitud de forma escalable, las instrucciones de esta SIMD se mantienen en 32-bit de longitud fija en AArch64.
Esto no es algo banal, ya que al tener una longitud fija de instrucciones, esto simplifica mucho el diseño del Front-End de la microarquitectura de la CPU. Es algo que no vemos en otros diseños complejos, donde se manejan distintas longitudes, complicando toda esta parte y haciendo que ocupe mayor superficie en el silicio.
Por otro lado, otra de las cosas que Arm ha querido que SVE herede de la filosofía RISC es que todo sea más simple. Por ejemplo, ha agregado operaciones de recopilación/dispersión, lo que ayuda a vectorizar una serie de problemas que, de lo contrario, requerir una gran cantidad de reorganización repetitiva.
También puede ayudar a aliviar los problemas con la falta de un buen swizzling en el registro, ya que los datos se pueden mezclar hacia/desde la memoria, sin embargo, esto tiene sus inconvenientes:
- Limitado a tamaños de elementos de 32/64 bits (tenga en cuenta que las variantes de 8/16 bits solo admiten la extensión de signo/cero a 32/64 bits)
- Rendimiento deficiente debido al cuello de botella de la LSU del procesador (y probablemente se ejecute como múltiples µops), ya que es efectivamente una operación escalar en términos de rendimiento. En otras palabras, el rendimiento disminuye linealmente a medida que aumenta el ancho del vector.
- Todavía requiere generación de índice como
TBL.
Arm rechaza los anchos de registros no-binarios
Al igual que han aparecido las memorias RAM con capacidades no binarias, como las de 24, 48 o 96 GB, que no siguen la potencia del 2, también se ha estado hablando sobre la implementación de registros no binarios, es decir, que no tengan tamaños potencia de dos. Concretamente sobre los registros de 1664-bit de ancho.
Sin embargo, Arm ha rechazado este tipo de implementaciones. SVE permite cualquier ancho de vector que sea un múltiplo de 128 bits hasta 2048 bits, sin más restricciones, como he comentado anteriormente. Esto significa que un sistema con vectores de 1664 bits cumpliría con las especificaciones de SVE, y permitiría gran flexibilidad en el lado del hardware.
Desafortunadamente, SVE no solo no es totalmente independiente del ancho, sino que viene con una serie de advertencias, particularmente al tratar con anchos que no son de potencia de 2. Es por eso que los anchos que hemos visto en las implementaciones actuales se corresponde con estas advertencias, como es el caso de Neoverse V1 que usa anchos de 128-bit o 256-bit en versiones posteriores, o los 256-bit de Graviton 3, y los 512-bit de los Fujitsu A64FX. Por tanto, creo que no veremos en el futuro cosas como un SVE de 384-bit o de 640-bit, etc., aunque Arm no lo prohíba de forma explícita.
SVE: pequeño y rápido vs grande y lento

Como bien sabes, siempre ha existido esa batalla entre RISC vs CISC, entre lo simple y rápido y lo pesado y lento. En el lado de los x86, la primera implementación de AVX512 tenía una peculiaridad interesante: la frecuencia del procesador puede acelerarse al ejecutar código pesado de 512-bit. Como el programador puede seleccionar el ancho del vector, esto permitió que el código se enfocara en la latencia (manteniendo vectores más cortos) o en el rendimiento (usando vectores más largos).
En cambio, SVE no permite que el programador seleccione fácilmente el ancho del vector, lo que significa que esta opción no está disponible. Esto podría limitar las implementaciones de hardware para seleccionar anchos que tengan un impacto limitado en la frecuencia/latencia. La guía de optimización de Neoverse V1, por ejemplo, no proporciona información sobre el rendimiento cuando el ancho de SVE está restringido a 128 bits, por lo que aún está por verse si un procesador funcionaría de manera diferente según el ancho de vector, particularmente con instrucciones que pueden no escalar tan bien con la longitud del vector (por ejemplo, reunir/dispersar).
Curiosamente, ARM presenta un «modo de transmisión» como parte de SME (Scalable Matrix Extensions), que le permite tener un ancho de vector más largo en relación con SVE, y puede ser una solución…
También puedo hacer un comentario sobre la extensión SIMD de la competencia x86. La comparación general entre NEON y SSE se salda con una superioridad en cuanto a ortogonalidad (menos espacios extraños en el conjunto de instrucciones) en el lado de Arm. Sin embargo, tiene menos instrucciones capaces de realizar tareas más pesadas como en el lado de x86.
Por otro lado, si comparamos SVE2 con AVX-512, vemos que se está cerrando la brecha. AVX-512 tapa muchos de los agujeros que tenía SSE (y sus versiones derivadas), mientras que SVE2 agrega operaciones más complejas (como el histograma y la permutación de bits), e incluso introduce nuevos detalles.
Por lo general, AVX-512 puede parecer más dividido, debido a todas sus extensiones, pero x86 tiene la ventaja de que hay pocas implementaciones y baja variabilidad, lo que hace que esta fragmentación percibida sea casi ilusoria en la práctica (actualmente, Skylake-X e Ice Lake son los principales objetivos de compatibilidad, con la llegada también de los AMD Zen 4 recientemente; aunque el programador debe ser consciente de esto).
La diferencia clave entre los dos es que AVX-512 le permite al programador especificar el ancho del vector (entre 128/256/512-bit) pero requiere hardware para admitir todos esos anchos, mientras que SVE2 permite que el hardware dicte el ancho (128-2048 bit) a expensas de que el programador tenga menos control sobre el mismo.
En términos de soporte de hardware, se espera que todas las futuras CPU diseñadas por Arm (y posiblemente también las microarquitecturas diseñadas por terceros) sean compatibles con SVE2 en todos los productos de perfil A (Cortex-A Series), aunque muchos posiblemente se limiten a vectores de 128 bits, mientras que AVX-512 es algo desconocido, ya que Intel ha tenido sus dudas al respecto como ya sabrás. Sin embargo, AVX-512 actualmente tiene la ventaja de estar disponible para los consumidores, con unos años de ventaja…
Actualizar NEON a SVE2
Además de agregar la predicación, y otras muchas instrucciones, y de ser de longitud variable con posibilidad de ser superior a NEON, la otra SIMD de Arm, es evidente que realizar el cambio de NEON a código optimizado para SVE es un gran paso adelante.
Pero esto puede suponer una tarea bastante considerable para los desarrolladores de software, que tendrían que adaptar el código fuente y volver a compilar los binarios. Sin embargo, existen bibliotecas que pueden ayudar con esto, como sse2neon que ayuda a traducir SSE a NEON, pero que lo hicieran entre NEON y SVE, aunque el ancho variable podría resultar más desafiante en este sentido.
Recursos de desarrollo
Hay que destacar que si estás interesado en programar haciendo uso de estas instrucciones o quieres conocer algo más sobre ellas, tienes gran cantidad de documentación en la página web oficial de ARM. También tienes gran cantidad de documentación sobre SVE y el soporte en Linux, para obtener más detalles de la ABI de este sistema.
En cuanto a compiladores, tenemos que las últimas versiones tanto de GNU GCC como de Clang/LLVM son compatibles con SVE2 a través de intrínescos. También existe el propio compilador de Arm denominado armclang, que también puede manejar estas instrucciones sin problema.
Por el momento, parece que el soporte es solo para compiladores para lenguajes de programación C y C++, que son los lenguajes que más se usan para aplicaciones científicas o de alto rendimiento que son las que pueden beneficiarse de las SVE. Pero es probable que alguno haya en la actualidad, aunque se me escape…
Para probar el código, si no tienes un hardware que soporte SVE de forma nativa, también tienes la opción de usar instancias en la nube como las Graviton 3 de AWS, u otras basadas en Arm que te puedan permitir trabajar de forma nativa. Si no, también puedes usar emuladores, que existen para este fin. De hecho, la propia Arm tiene su propio Emulador de Instrucciones ARM, que no es de código abierto, y solo se puede correr en algunos hosts AArch64 con Linux, por lo que tendrás que usar SBC (Single Board Computer) para ello.
Si usas Linux, seguro que ya estás familiarizado con qemu, un emulador de plataformas. Pues bien, con él también podrás hacer uso de ciertas plataformas ARM en las que podrás trabajar.
Soporte del sistema operativo
Como sabes, ARM no está disponible en todos los sistemas operativos, aunque sí tiene soporte para la mayoría de los más importantes. Entre ellos, algunos no soportan SVE, por lo que si buscas compatibilidad, lo que debes hacer es optar por estos que te listo:
- GNU/Linux: es compatible con SVE a partir del kernel 4.15 y SVE2 con 5.2 en adelante. Es el kernel con mejor soporte para estas instrucciones y para la propia ISA ARM. Recuerda que tanto en dispositivos móviles como en HPC, el dominante es Linux, por lo que tanto para Android como para los sistemas de servidores y supercomputación, Linux debe estar al día al respecto.
- FreeBSD: aún no es compatible, pero es probable que estén trabajando en ello para un futuro. Este sistema ya corre en plataformas Arm, pero falta que agreguen el soporte SVE/2.
- Windows: no aparece como una característica del procesador soportada por este sistema de Microsoft por el momento. Veremos si en un futuro lo hace, ya que Microsoft y Qualcomm colaboran para crear chips Arm de alto rendimiento para sus portátiles Surface, como debes saber.
- macOS: probablemente solo sea compatible una vez que un chip de Apple lo admita. Así que, en futuros lanzamientos de los chips A-Series y M-Series, habrá que estar atentos para ver si tienen soporte SVE y entonces los desarrolladores de Apple lo implementarán en su sistema operativo y compilador.
- iOS: probablemente similar al anterior, sin embargo, mientras es más probable que aparezca en SoCs M-Series, lo es menos en los A-Series destinados para iOS y versiones derivadas como iPadOS o watchOS, ya que en este tipo de dispositivos de bajo consumo donde prima la eficiencia no es tan interesante el uso de estas instrucciones.
- Android: no está documentado en el NDK , sin embargo, se puede usar
getauxvalla llamada de Linux (o analizar /proc/cpuinfo como lo hace la biblioteca cpu_features de Google ), por lo que es compatible siempre que la versión del kernel sea lo suficientemente nueva. Parece que SVE puede ser compatible con Android 10 si se ejecuta con el kernel Linux 4.19, mientras que SVE2 puede ser compatible con Android 11 cuando se ejecuta Linux 5.4.
Entre los sistemas operativos más populares, parece que solo Linux/Android son los que tienen mejor soporte por el momento…
Conclusión
A los programadores de SIMD a menudo les ha molestado tener que lidiar con múltiples conjuntos de instrucciones SIMD en la misma plataforma (MMX/SSE y sus versiones/AVX/AVX512). SVE tiene como objetivo abordar este problema (a expensas de la introducción de otro conjunto de instrucciones, como es la propia SVE/2) con un enfoque diferente, al tiempo que brinda una mayor flexibilidad a los diseñadores de microarquitecturas de CPU y nuevas capacidades a los programadores. Por el momento, parece que SVE lo logra en gran medida con un equilibrio razonable, a pesar de todos los compromisos que esto implica.
Para que esto sea posible, SVE tiene que operar a un nivel más alto de abstracción en relación con otros conjuntos tipo SIMD de longitud fija, que trabajan a un nivel más bajo de abstracción.
Dependiendo de la aplicación, escribir código para SVE2 puede generar nuevos desafíos. En particular, la adaptación de problemas de ancho fijo y la combinación de datos alrededor de vectores puede volverse mucho más difícil cuando se desconoce la longitud. Si bien SVE2 debería proporcionar suficientes herramientas para hacer el trabajo, su soporte para las operaciones de intercambio de datos sigue dejando mucho que desear por el momento. Por otro lado, SVE2 comparte muchas funciones con NEON, lo que simplifica enormemente la adopción del código NEON existente en SVE2.
Desafortunadamente, esa escalabilidad o flexibilidad también se vuelve en contra de la SVE, ya que a falta del control de la longitud del vector por parte del programador, dejando eso del lado del hardware, podrían darse fallos o casos en los que el código no funcione. Por tanto, se hace más necesaria la comprobación en emuladores o plataformas nativas.
Finalmente, el principal punto de ventaja de SVE2 sobre NEON, la capacidad de tener vectores de más de 128 bits en ARM, no se está explotando, como he comentado al principio, ya que pocos son los diseños que han usado vectores de más de 128-bit, desaprovechando ese margen hasta las 2048-bit que tiene. Como tal, y además de la adopción lenta de software/SO, podría pasar un tiempo antes de que podamos ver el verdadero alcance de lo que SVE es capaz de hacer…