
Como debes saber, la CPU procesa el software para que todo funcione en un sistema informático. Los programas se componen de instrucciones y datos, las instrucciones indican qué operación hay que realizar sobre los datos para obtener el resultado esperado. Y así es como se ejecuta todo. Pues bien, una de las unidades más importantes de la CPU es la ALU o la FPU, que es la que se encarga de las operaciones matemáticas. Y, en los actuales procesadores, como los Intel, se han incluido unidades funcionales capaces de ejecutar instrucciones vectoriales con longitudes de datos de hasta 512-bit, como son las AVX-512 que trataremos aquí.
Estas extensiones pretenden acelerar el procesamiento de ciertas cargas de trabajo, especialmente las científicas, que necesitan de un gran número de operaciones de este tipo. En cambio, cuando apareció AVX-512, no todo fueron buenas críticas para Intel, también hubo muchos que no les gustó nada esta incorporación, e incluso se toparon con ciertos problemas como veremos…
Quizás también te interese conocer:
¿Cómo funciona una ALU?
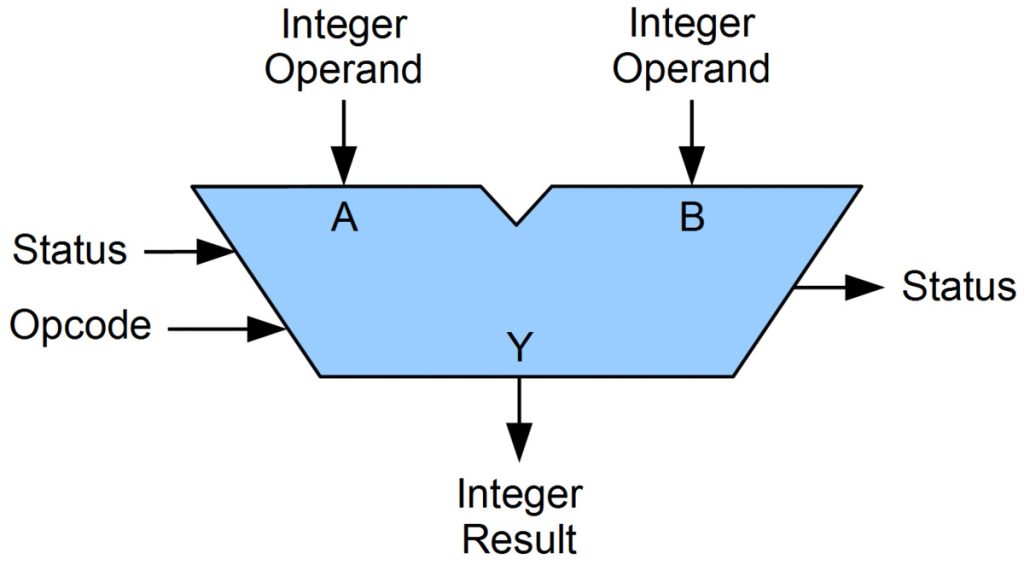
Antes de conocer más sobre el conjunto de instrucciones AVX-512, primero es esencial entender cómo funciona una ALU (Arithmetic-Logic Unit), es decir, una unidad de procesamiento aritmético y lógico.
Es decir, en esta unidad se realizan cálculos que incluyen operaciones como sumas, multiplicaciones, divisiones, etc. Para realizar estas tareas, la ALU utiliza circuitos digitales específicos controlados por la unidad de control de la CPU, que cuando capta una instrucción que hay que procesar desde la memoria, y la decodifica, envía un código Opcode a la ALU indicándole qué es lo que tiene que hacer con dos datos que estarán cargados en los registros. Por ejemplo, una instrucción ADD sumaría, una SUB restaría, MUL multiplicaría, DIV divide, etc.
Además, esta ALU, al igual que el resto de unidades de la CPU, trabajarán al ritmo marcado por la frecuencia de reloj. Por ejemplo, si es de 5 Ghz, entonces realizarán 5.000 millones de operaciones por segundo, por simplificarlo mucho.
Dicho esto, a medida que aumenta la velocidad del reloj de la CPU, aumenta la cantidad de calor generado por la CPU. Por tanto, ir escalando la frecuencia más y más no es la única solución para ganar rendimiento. Por eso, los diseñadores de CPUs tienen que buscar alternativas para ganar rendimiento, como puede ser el paralelismo a nivel de núcleo, renombre de registros, predicción y especulación, ejecución fuera de orden, sistemas superescalares, etc. Y entre las medidas para aumentar la potencia de cálculo también se encuentran el uso de instrucciones denominadas SIMD, es decir, vectoriales, capaces de operar sobre conjuntos de datos mayores.
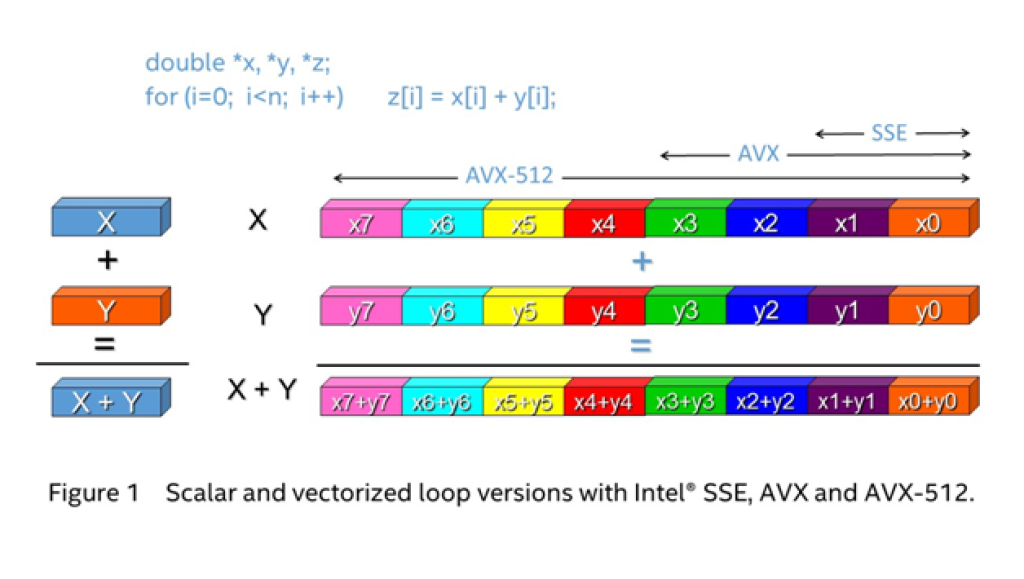
Un ejemplo de estas instrucciones es AVX-512, que mientras que el resto de unidades trabajan con datos de 64-bit, en las unidades especiales para estas extensiones se opera con datos de 512-bit de longitud, es decir, podrían manejar 8x veces el tamaño de palabra normal de una sola vez. Para hacer esto, se necesitan ALUs (enteros) o FPUs (si es en coma flotante) más grandes y complejas, lo que termina traduciéndose en mayor superficie del chip, por tanto mayor coste, y también otras complicaciones…
¿Cómo llegan los datos a la ALU?
Pues bien, ahora que tienes una comprensión básica de lo que es una ALU y su funcionamiento, además de para qué se usan las AVX-512 a nivel básico, lo siguiente es aprender cómo llegan los datos a la ALU, ya que esto también te ayudará a comprender acerca de estas extensiones.
Para llegar a la ALU, los datos deben moverse a través de diferentes sistemas de almacenamiento. Este viaje de datos se basa en la jerarquía de memoria del sistema informático. Una breve descripción de esta jerarquía sería:
- Memoria secundaria: se trata de los medios de almacenamiento masivo, es decir, de las unidades de disco duro HDD o SSD, entre otras unidades que también pueda haber conectadas al sistema de E/S, como pueden ser los medios ópticos, etc. En ellos se almacena gran cantidad de información, pero son memorias más lentas con respecto a la velocidad de la CPU. Por tanto, acceder a estos medios implica una penalización, una mayor latencia. Por eso, para evitar esas penalizaciones, lo que se hace es cargar estos datos a una memoria primaria que veremos en el siguiente punto. Por ejemplo, para que tengas una idea más clara, imagina que tienes Word instalado en tu disco duro y deseas ejecutarlo, ese software estará compuesto de una serie de ejecutables o binarios que contendrán las instrucciones y los datos necesarios para que la CPU los ejecute. También podría ocurrir que el software que deseas ejecutar no esté en un disco duro, como por ejemplo cuando instalas un sistema operativo desde un pendrive o desde un DVD. Allí también se encontrarán los binarios ejecutables con dichas instrucciones y datos.
- Memoria primaria: el sistema de almacenamiento primario consiste en una memoria de acceso aleatorio (RAM o Random Access Memory). Este sistema de almacenamiento es más rápido que el sistema de almacenamiento secundario, pero no puede almacenar tanta información y tampoco lo puede hacer de forma permanente, ya que es una memoria volátil, que almacena la información mientras esté siendo alimentada. Es decir, cada vez que apagas el ordenador no se borran los programas que tienes instalados, pero sí se borra el contenido de esta RAM. Como he dicho, cuando se carga el proceso o programa en la memoria RAM lo que se está haciendo realmente es pasar las instrucciones y datos del binario ejecutable de la unidad secundaria a esta primaria en la que la CPU puede acceder de forma más rápida.
- Memoria caché: la memoria caché está incrustada dentro la CPU y es el sistema de memoria más rápido, pero también es de muy pequeña capacidad y también es volátil. Este sistema de memoria se divide generalmente en tres partes: L1, L2 y L3 . Cualquier dato que deba ser procesado por la ALU se mueve del disco duro a la RAM y luego a la memoria caché. Dicho esto, la ALU no puede acceder a los datos directamente desde la memoria caché. Por eso necesita de otra memoria aún más reducida en capacidad y más rápida que es el siguiente punto…
- Registros de la CPU: el registro de la CPU en una memoria muy simple compuesta por elementos biestables muy rápidos. Según la arquitectura de la CPU, los registros pueden cambiar de tamaño. Por ejemplo, pueden ser de 8-bit, 16-bit, 32-bit, 64-bit, etc. Además, su número puede ser variable, y todos ellos componen la ventana o archivo de registro de la CPU. Pues bien, es en estos registros donde las unidades de cálculo, como la ALU o la FPU, pueden tener acceso a los datos que se cargan en ellos. De modo que, cuando se trae una instrucción desde la RAM hacia la CPU en el ciclo fetch, la instrucción será decodificada o interpretada por la unidad de control, que determinará qué implica ejecutar esa instrucción. Por ejemplo, ADD r1, r2, r3 podría sumar el dato del registro r2+r3 y almacenar el resultado en r1. De esta forma, la unidad de control enviará ese opcode a la ALU diciendo que debe sumar los valores y la localización de los datos, en este caso los registros necesarios. De esta forma, la ALU accede a los datos y realizará la operación de suma. Así es como trabaja esta jerarquía.
Además, como debes saber, los datos e instrucciones que se suelen usar con mayor frecuencia son almacenados en la caché, para así acceder a ellos de forma más rápida en caso de que en un futuro volviesen a ser necesarios. Como puedes estar pensando, cada nivel de caché es más rápido:
- L1: es el primer nivel, el más rápido de todos, con más baja latencia. Esto quiere decir que para acceder a ella se desperdician menos ciclos de reloj. Además, esta memoria suele estar dividida, en una L1D o L1 para datos, y una L1I o L1 para instrucciones. Es decir, instrucciones y datos no se mezclan.
- L2: es el siguiente nivel de caché, y es más grande en capacidad que la L1, pero algo más lenta, por lo que se necesitan más ciclos para acceder a ella. Aquí, tanto datos como instrucciones estarán mezclados, ya que es unificada.
- L3: este nivel es de mayor capacidad que la L2, pero aún más lenta que la L2. Y al igual que la L2, está también unificada, almacenando tanto datos como instrucciones. Si la L3 es el último nivel, se le conoce también como LLC (Last Level Cache), aunque en otros sistemas podría haber otros niveles, como una L4, etc.
Como puedes imaginar, cuando la CPU debe buscar algún dato o instrucción, para aumentar el rendimiento, primero buscará en la L1, ya que es la que menos ciclos de reloj penaliza para su acceso. Si no está allí se buscará después en la L2, la siguiente más rápida. Y si tampoco se encuentra allí se buscará en la L3. En caso de tampoco estar en la L3, entonces se buscará en la RAM y así…
¿Qué es AVX-512 y cómo funciona?
El conjunto de instrucciones AVX-512 es la segunda iteración de AVX y llegó a los procesadores Intel en 2013. AVX son las siglas correspondientes a Advanced Vector Extensions, y fue introducida por primera vez en los Xeon Phi (Knights Landing) de Intel y luego llegó al servidor de Intel con los Xeon basados en Skylake-X.
Además, el conjunto de instrucciones AVX-512 llegó también a los equipos del consumidor, es decir, a los PCs, con la arquitectura Cannon Lake y luego fue compatible con las arquitecturas Ice Lake y Tiger Lake. Quizás un paso de los más criticados que jamás debería haberse producido, por un lado porque no había software suficiente que pudiera aprovechar estas instrucciones, y por otro porque agregaba complejidad a estas unidades.
Como se explicó anteriormente, la ALU/FPU solo puede acceder a los datos presentes en el registro de una CPU. El conjunto de instrucciones AVX aumenta el tamaño de estos registros. Debido a este aumento, se pueden procesar varios datos con una sola instrucción, aumentando el rendimiento.
El objetivo principal de este conjunto de instrucciones era acelerar las tareas relacionadas con la compresión de datos, el procesamiento de imágenes y los cálculos criptográficos. Al ofrecer el doble de potencia de cálculo en comparación con AVX-256, el conjunto de instrucciones AVX-512 ofrecÍA mejoras sustanciales en el rendimiento. Sin embargo, no se duplicó el rendimiento en estas CPUs de Intel, como muchos pueden estar pensando.
¿Por qué Intel pone fin a AVX-512?

Como se explicó anteriormente, el conjunto de instrucciones AVX-512 ofrece varias ventajas en cálculos computacionales, pero no todo fue bienvenido. Es cierto que bibliotecas populares como TensorFlow usan el conjunto de instrucciones para proporcionar cálculos más rápidos en las CPU que admiten el conjunto de instrucciones.
AMD adoptó por primera vez las AVX-512 en los microprocesadores basados en Zen 4. Un cambio total entre ambas compañías…
Entonces, ¿por qué Intel deshabilita AVX-512 en sus procesadores Alder Lake recientes? Bueno, lo cierto es que no se han eliminado del todo. Por ejemplo, en los Alder Lake tenemos que se componen por una arqutiectura multinúcleo heterogénea, con núcleos de alto rendimiento P-Cores y de alta eficiencia E-Cores.
Mientras los P-Cores se basan en la microarquitectura Golden Cove, y sí que tienen posibilidad para ejecutar estas instrucciones, en los núcleos E-Cores basados en la microarquitectura Gracemont, no se permite ejecutar estas instrucciones. El planificador de estos núcleos rechazará dichas instrucciones para mantener estos núcleos más pequeños y eficientes energéticamente.
En cambio, las CPUs Alder Lake en adelante, no son compatibles con el conjunto de instrucciones AVX-512, puesto que de lo contrario habría núcleos E-Cores que no podrían ejecutar ciertos programas. Sin embargo, sí que se pueden usar en otras CPUs donde Intel no ha mezclado físicamente estos núcleos, como en el caso de los Xeon para HPC y servidores, e incluso en algunos equipos donde se permite desactivar los E-cores desde el BIOS/UEFI.
¿Se necesita AVX-512 en una CPU de consumo?

El conjunto de instrucciones AVX-512 aumenta el tamaño del registro de una CPU para mejorar su rendimiento. Este aumento en el rendimiento permite que las CPU procesen números más rápido, lo que permite a los usuarios ejecutar algoritmos de compresión de video/audio a velocidades más rápidas.
Dicho esto, este aumento en el rendimiento solo se puede observar cuando la instrucción definidas en un programa están optimizadas para ejecutarse en el conjunto de instrucciones AVX-512. De lo contrario serán totalmente inútiles, y dada la poca adopción que ha tenido AVX-512, esto sucede en pocas situaciones.
Por esta razón, las arquitecturas de conjuntos de instrucciones como AVX-512 son más adecuadas para las cargas de trabajo del servidor y HPC, pero no para el consumidor medio. Por esto, no tiene demasiado sentido hacerlo así.
¿Entonces por qué AMD las ha integrado ahora? En su día lo hizo bien manteniéndose al margen para no tener los mismos problemas que tuvo Intel en su momento. Pero ahora han tomado una dirección opuesta, y también las han adoptado. Y eso puede deberse a que las microaquitecturas diseñadas por AMD, como la Zen 4, se usan tanto para los Ryzen como para los Threadripper y EPYC, y tal vez han creado una misma para todos los chips como hizo Intel en su momento. Y es que, de esta forma, AMD también puede trabajar ahora con AVX-512 en servidores, estaciones de trabajo y HPC para competir con los Xeon.
¿Por qué Intel las ha retirado de Alder Lake?

El soporte de Intel para las instrucciones AVX-512 con sus procesadores Alder Lake ha sido un asunto turbio. La compañía afirmó inicialmente que la función no funcionaría en sus nuevos procesadores de 12.ª generación en adelante. Pero luego dio marcha atrás cuando los proveedores de placas base encontraron varias soluciones para habilitar estas instrucciones desde el firmware.
De este modo, se puede habilitar o deshabilitar esta opción desde el BIOS/UEFI de la placa base, para así poder dar la posibilidad a los usuarios de emplear AVX-512 o no, en función de sus necesidades de carga de trabajo.
Sin embargo, parece que Intel está vendiendo algunas unidades no-K, es decir, de las que no están desbloqueadas para overclocking, con AVX-512 deshabilitado por defecto. Y, aunque parece que no está eliminado a nivel de hardware de estos productos, sí que este bloqueo evitaría que los usuarios hiciesen uso de ellas.
Pero parece que Intel ha estado jugando al rato y al ratón, ya que finalmente parece que desde la empresa americana han optado por deshabilitar físicamente el soporte AVX-512 en sus chips para consumidores a nivel de silicio, por lo que no se podrá hacer nada para usar estas instrucciones, y todo en pos de aumentar la eficiencia energética.
Es decir, en resumen, los bandazos que ha dado Intel han sido:
- Comentó a la prensa que AVX-512 no sería compatible con los nuevos procesadores híbridos.
- Antes de su lanzamiento apareció una guía de optimización donde se mostraba el uso de esta función.
- Intel volvió a negar que estuvieran admitidas esas instrucciones, quizás por todas las críticas recibidas en el pasado. Y entonces eliminó las referencias de esta guía.
- Cuando se lanzó Alder Lake se descubrió que las instrucciones funcionaban en algunas placas base con el firmware adecuado. Algo que hicieron los fabricantes de placas en contra de la voluntad de Intel.
- Intel se mantuvo callado en un principio, aunque a la prensa taiwanesa le diría que el soporte de AVX-512 estaba presente, aunque no por defecto, por lo que si alguien quería bajo su propia responsabilidad usarlas, podría, al igual que se asumen los riesgos de un overclocking…
- El pasado año, Intel da la noticia de que desactiva finalmente las AVX-512 con una nueva actualización del firmware o microcódigo.
- Esa misma semana aparecen BIOS/UEFI que deshabilitaban la opción AVX-512.
- MSI encontró la forma de eludir este bloqueo a AVX-512 de Intel, y permitió realizar cambios en su BIOS/UEFI de forma fácil.
- Intel no estaba contento con esto y finalmente decidió desactivar el conjunto de instrucciones por hardware, para que no se pudiese inmutar de ninguna forma. Por tanto, en los primeros Alder Lake estará disponible físicamente y en los Alder Lake más nuevos en adelante no lo estará.
Por tanto, si quieres AVX-512 habilitado, entonces tienes que comprar los Intel Xeon, que por supuesto son más caros.
Durante todo este culebrón, ahora llega AMD y da soporte AVX-512 en todos sus chips Zen 4, incluso en los de los consumidores. Así que, si quieres un procesador para tu PC que cuente con AVX-512, lo mejor es un Ryzen 7000 (Zen 4) en estos momentos…
¿Qué es VNNI?

Y, para rematar, no me gustaría terminar sin hablar de las AVX-512 VNNI, es decir, una extensión especialmente diseñada para acelerar los algoritmos de redes neuronales convolucionales. Las siglas VNNI se corresponden con Vector Neural Network Instructions.
Estas instrucciones amplían las extensiones AVX-512 iniciales, con cuatro nuevas instrucciones para acelerar los bucles de redes neuronales. Estas instrucciones son:
VPDPBUSD: esta instrucción puede multiplicar los bytes individuales (8 bits = 1 byte) del primer operando fuente por los bytes correspondientes del segundo operando fuente, produciendo resultados de palabra de 16 bits que se suman y acumulan en una palabra doble (32-bit) del operando de destino.VPDPBUSDS: igual que el anterior excepto en el desbordamiento de la suma intermedia que se satura a 0x7FFF_FFFF/0x8000_0000 para números positivos/negativos.VPDPWSSD: en esta otra instrucción se puede multiplicar las palabras individuales (16 bits) del primer operando fuente por la palabra correspondiente del segundo operando fuente, produciendo resultados de palabras intermedias que se suman y acumulan en una palabra doble (32 bits) del operando de destino.VPDPWSSDS: como puedes imaginar, es igual que el anterior excepto en el desbordamiento de la suma intermedia que se satura a 0x7FFF_FFFF/0x8000_0000 para números positivos/negativos.
La principal motivación detrás de la extensión AVX512 VNNI es la observación de que muchos bucles de redes neuronales convolucionales estrechos requieren la multiplicación repetida de dos valores de 16 bits o dos valores de 8 bits y acumulan el resultado en un acumulador de 32 bits. Esto es posible usando dos instrucciones, VPMADDWD que se usan para multiplicar dos pares de 16 bits y sumarlos seguidos de uno VPADDD que suma el valor acumulado.