
Los futuros AMD Ryzen 8000 Series, así como los EPYC de nueva generación para HPC, estarán potenciados por la microarquitectura Zen 5 que AMD lleva diseñando desde hace tiempo. Esta arquitectura parece ser más que una evolución, una revolución. Y según algunas filtraciones e información que se ha mostrado, aquí te desgranamos todos los secretos:
La filtración
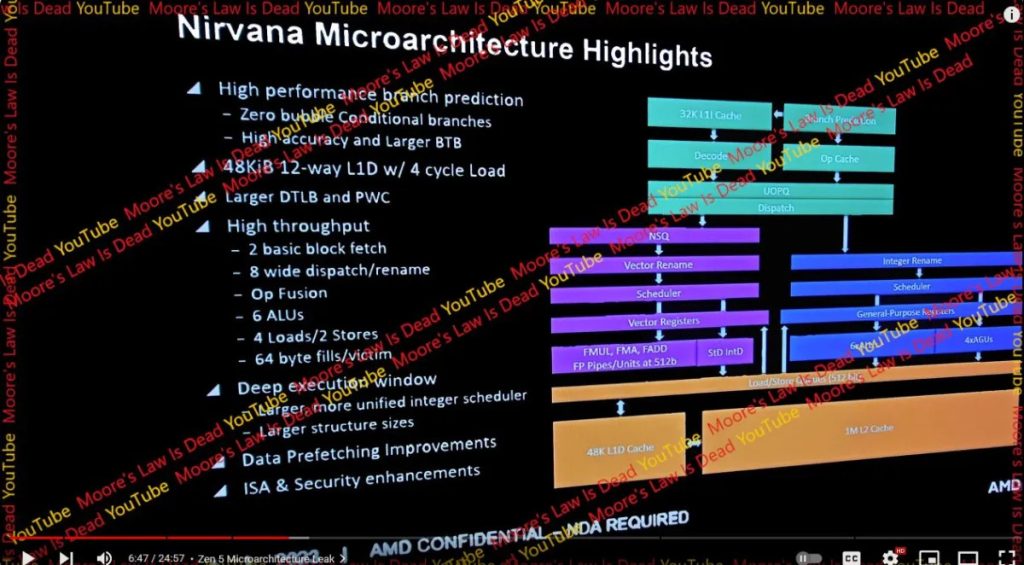
En un canal de YouTube, un youtuber denominado Moore’s Law is Dead, ha mostrado lo que podría ser una captura de una diapositiva sobre la nueva microarquitectura Zen 5 de AMD. Aunque no se sabe muy bien si será o no cierta, lo que sí es cierto es que muestra cosas muy interesantes que iré desgranando, para hacernos una idea de lo que nos espera si finalmente se confirma.
Zen 5 (codename Nirvana), el nombre de esta nueva microarquitectura, será la que vaya en cada uno de los núcleos en los CCD, que recibirán a su vez el nombre clave Eldora. Además, estos CCDs darán vida a los Ryzen 8000 Series «Granite Ridge» y EPYC «Turin» de próxima generación y que deberían aparecer en 2024. Además, gracias al roadmap u hoja de ruta de AMD, también hemos podido saber que Zen 5 se fabricará usando tecnología de 4nm inicialmente y luego se pasará a versiones mejoradas en 3nm. Habrá por supuesto una versión Ryzen 8000X3D con 3D V-Cache, y también núcleos Zen 5c de tamaño reducido para multinúcleo heterogéneo.
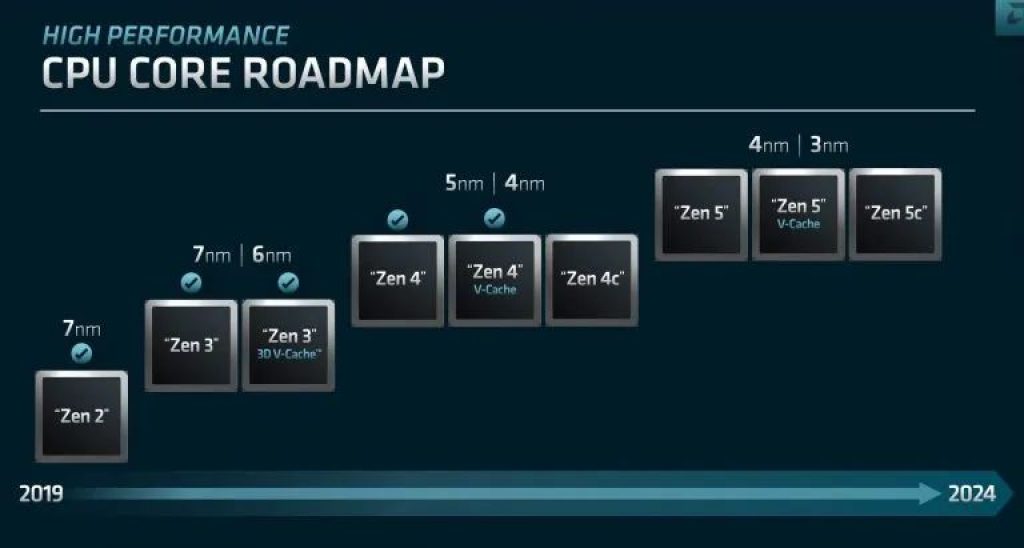
Como sabes, Zen 1 fue una microarquitectura totalmente nueva. Luego llegaría Zen+, basada en la primera y con algunos cambios, y así sucesivamente. En cambio, Zen 5 no estará basada en Zen 4, sino que será una microarquitectura diseñada desde cero, por lo que cabe esperar cambios muy profundos.


Morpheus, el nombre clave para Zen 6, ofrecería un incremento del 10% en el IPC respecto a Zen 5, pero en este caso sería un rediseño o mejora basada en Zen 5. Es decir, que se espera que el salto de rendimiento de Zen 4 a Zen 5 sea superior, tal vez del 15% o más.
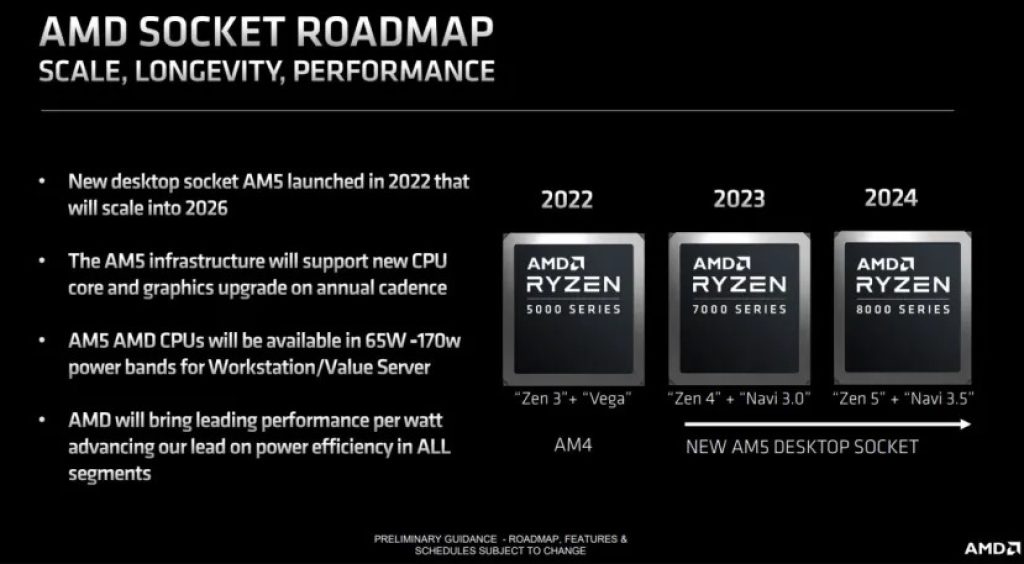
También se puede apreciar que usará el mismo socket AM5, esto era algo esperado, mismo socket que Zen 4. Sin embargo, en vez de integrar una GPU Navi 3.0 basada en RDNA3, en las nuevas APUs Zen 5 se dará un paso adelante, integrando GPUs basadas en la arquitectura Navi 3.5.
Sin embargo, no he hablado de la primera diapositiva, quizás la más interesante. Y es que merece irla desglosando punto a punto, ya que es muy interesante…
Front-End
Veamos lo referente al Front-End de esta microarquitectura Zen 5 según estas supuestas filtraciones:
Branch prediction
Como sabes, en las nuevas microarquitecturas se implementan predictores de ramas para predecir el camino que se tomará cuando se ejecuta una instrucción de salto condicional o no condicionales. En vez de esperar a que se sepa qué camino tomar, como hacían los antiguos microprocesadores, ahora, para adelantar trabajo y mejorar el rendimiento, se predice el camino y se comienza a ejecutar antes de conocer si realmente será ese el camino tomado. En caso de fallo de predicción se tendrá que vaciar la pipeline y ejecutar las instrucciones del otro camino. Pero en caso de acierto, ya estará ejecutado. Por eso, siempre se intenta aumentar la tasa de aciertos. Como puedes imaginar, estos branch prdictions son los que dirigen la pipeline de las CPUs actuales. Por tanto, su tasa de aciertos y eficiencia afectan enormemente al rendimiento. Un predictor lento puede retrasar la pipeline y desperdiciar tiempo y energía inútil.
Pues bien, según la diapositiva filtrada, Zen 5 tendría:
- Cero burbujas (zero bubble): una burbuja introducida en la pipeline quiere decir que si se retrasa en manejar una rama, la pipeline queda vacía, como cuando una tubería que transporta agua tiene burbujas. Algo parecido sucede en un procesador, solo que en este caso sería un flujo de instrucciones. Pues bien, AMD ya consigue cero burbujas desde Zen 1, algo que continuará en Zen 5, pero con la mejora de poderlo hacer en más ramas. Es cierto que Intel ya lo conseguía desde Haswell, pero AMD ha tenido problemas para mejorar su Front-End hasta la llegada de Zen, momento en el que AMD se ha puesto más a la par en este sentido.
- Alta precisión de aciertos: por otro lado, también se ha mejorado la predicción, mejorando la tasa de aciertos en el predictor, lo que resultará en menos fallos y menos casos en los que se necesite vaciar la pipeline y empezar a ejecutar las instrucciones del camino correcto.
- BTB o Branch Target Buffer (buffer para almacenar objetivos de ramas) más grande: por supuesto, también se ha ampliado esta memoria caché para poder almacenar los objetivos de las ramas o bifurcaciones. Con cada generación Zen se ha venido aumentando el BTB y no hay nada que haga pensar que no será así en Zen 5. No obstante, tras Zen 4, aún sigue un pasito por detrás de Intel en este sentido. ¿Cambiará en Zen 5? Veremos. Pero por ahora, el L3 BTB de los Golden Cove de Intel tienen un 50% más de capacidad que el L2 BTB (no tiene L3) del Zen 4, además de que Zen 4 tiene mayor latencia, lo que es perjudicial para algunas cargas de trabajo, como los videojuegos. Pero Zen 5 podría llegar para cambiar esto.
Unidad fetch
Antes de nada, decir que el fetch es la unidad que busca las instrucciones y las trae para que sean procesadas. También debes saber que un bloque básico es un bloque de código que tiene un punto de entrada y un punto de salida. Sin embargo, cuando hablamos de 2 bloques a la vez, como en este caso, puede significar que el fetch de este Zen 5 podría buscar a través de ramas tomadas y convertirlas en no tomadas, desde la perspectiva de la búsqueda, lo que se traduce en traer dos bloques básicos en un solo ciclo.
Algo que Intel y Arm ya hacen, ayudando a mejorar el ancho de banda para mejorar el IPC. Para ello, AMD necesitaría implementar un micro-BTB o bufer de bucle como hace Intel y el mundo Arm. Pero esto no es sencillo, y requeriría una L1 de instrucciones de doble puerto y una caché de micro-ops junto al BTB grande capaz de entregar dos objetivos de rama por ciclo. Y no solo eso, también alguna lógica adicional para poder fusionar los dos bloques de búsqueda en un bufer.
Load/Store
Una arquitectura Load/Store (L/S) o de carga y almacenamiento, es un modelo típico de los RISC, y capaz de dividir las instrucciones en dos categorías: las de acceso a memoria (en memoria principal y registros) y las de operaciones para la unidad de ejecución (solo ocurren entre registros). Los CISC usan un modelo diferente, de memoria-registro, pero recordemos que Intel y AMD han adoptado una arquitectura tipo RISC, aunque x86 sea CISC, usando un traductor de las instrucciones CISC a microoperaciones más simples al estilo RISC.
Con cada nueva generación de microarquitectura suele haber modificaciones en el subsistema de memoria para reducir la latencia. Según la diapositiva del Zen 5, tenemos los siguientes cambios:
- Caché L1D: parece que la nueva Zen 5 traería una memoria caché L1 de datos de 48 KB, de tipo asociativo y 12-way (crecerá el DTLB en consecuencia). Esto es mejor en comparación con la de 32 KB y 8-way de Zen 4. Cuando se hacen estos aumentos, no todo son ventajas, y lo vimos en el Intel Sunny Cove, cuya latencia pasó de 4 a 5 ciclos de reloj. Sin embargo, si la diapositiva es cierta, AMD podría haber conseguido este incremento manteniendo 4 ciclos de penalización o latencia. Al aumentar la caché con la misma latencia, se consigue una mayor tasa de aciertos (hits) de caché, lo que evitará tener que acudir a la memoria RAM a por datos, lo que significa mayor latencia, es decir, más ciclos de reloj de penalización.
- TLB: el Translation Lookaside Buffer es un elemento esencial para los sistemas que usan memoria virtual, que deben traducir las direcciones de memoria a direcciones físicas, donde se aloja lo que se está buscando en algún lugar de la memoria principal o secundaria. El TLB almacenará en un buffer de memoria traducciones realizadas recientemente y que podrían volverse a usar, lo que reduce la latencia en ciclos. En Zen 5, si tenemos en cuenta que se necesitan 4 accesos a la memoria caché por cada ciclo, se necesitaría un DTLB de 72×4=288, aunque no está claro de que el aumento será tan grande. Podría ser más bien de 128 entradas y 16-way. Es posible que el DTLB de nivel 2 también aumente, como ya pasó con Zen 4 respecto a Zen 3. Ahora falta saber si el ITLB, el TLB para instrucciones, también tendrá algún camio…
- PWC (Page Walk Cache): parece que Zen 5 también traerá un PWC más grande. Como sabes, los nuevos microprocesadores, pueden almacenar estructuras de paginación de niveles superiores de memoria para reducir la latencia cuando los TLBs no pueden contener el conjunto de trabajo completo de un programa. Con un PWC se puede almacenar el recorrido de paginas para así cubrir un mayor espacio de direcciones, lo cual reduce la cantidad de accesos que genera un TLB.
8-Wide Dispatch/Rename
Por supuesto, otra de las cosas que importan en un Front-End de alto rendimiento es el ancho, el throughput de instrucciones. En el pasado hemos visto cómo Zen aumentaba el ancho de instrucciones a 8 (8-wide), pero la unidad de retiro solo poseía un ancho de 6 microoperaciones. En cambio, en el Zen 5 tanto el renombre y el despacho se amplian a 8 microoperaciones, es decir, tiene un ancho de 8-wide por ciclo de reloj. Esto significa que puede manejar más instrucciones por ciclo.
Fusión de micro-ops
Una CPU podría mejorar el rendimiento y aprovechar mejor los buffers internos si se fusionan instrucciones adyacentes en micro-operaciones únicas. Intel y AMD han estado fusionando, lo mismo sucede en Arm. Volviendo a AMD, vimos cómo en Zen 3 mejoró la fusión al conseguir que las instrucciones ALU simples, como ADD, AND, XOR, SUB, etc., se fusionen con una rama posterior, así como CMP y TEST. De este modo, Zen 3 podría realizar una operación matemática, verificar el resultado según una condición y realizar una bifurcación o rama basada en ello. Zen 4 añadió también la fusión NOP y la XOR+DIV/CDQ+IDIV.
Se espera que Zen 5 amplíe los casos de fusión, aunque en las diapositivas no aparece. Veremos si esto es finalmente posible.
Back-End
En el Back-End tenemos las unidades de ejecución, es decir, las ALUs, FPUs, etc., que se encargan de ejecutar las operaciones implícitas en las instrucciones que han traído, decodificado y traducido a microoperaciones en el Front-End. Y en esta otra parte también hay cambios muy interesantes para Zen 5:
Scheduler
Como sabrás, las CPUs de alto rendimiento usan un esquema de ejecución fuera de orden, u Out-Of-Order Execution (OoOE) para mejorar el rendimiento y paralelismo a nivel de instrucción. Esto quiere decir que, aunque los programas son secuencias de instrucciones, no se ejecutan en orden como otros procesadores, sino que se van ejecutando en función de las dependencias, y finalmente se ordenan en el orden secuencial para que la ejecución del programa no se vea alterada.
Pues bien, el planificador de una CPU, o scheduler, es una unidad que se encarga de comprobar qué registros están siendo escritos y verificar si las instrucciones pendientes necesitan esos datos de entrada u operandos. Por otro lado, también deben seleccionar las instrucciones que tienen sus datos u operandos listos y darles prioridad a las que no tienen dichos operandos listos (y habría que ir a buscarlos a memoria, con el consiguiente aumento de ciclos). Una vez va seleccionando aquellas instrucciones rápidas, sin dependencias, las envía a las entradas de las unidades de ejecución.
Los planificadores pequeños tienen la ventaja de ser más fáciles de hacerlos rápidos, pero se llenan rápidamente, lo que termina penalizando el rendimiento. Por eso, siempre se intentan hacer más grandes y rápidos. Además, tenemos planificador distribuido, con planificadores privados en cada puerto; o planificador unificado, con un solo planificador para varios puertos. Sin embargo, el unificado debe ser capaz de seleccionar suficientes instrucciones en cada ciclo como para mantener alimentados los puertos de ejecución y no desperdiciar ninguna unidad de ejecución, o las menos posibles.
Los puertos o entradas de las unidades de ejecución son las salidas del planificador, que alimenta unidades como la AGU, ALU, etc.
AMD, Intel y Arm están usando un enfoque híbrido en sus últimos diseños. De esta manera consiguen lo mejor de ambos mundos. Zen 5 seguirá un esquema de planificador unificado, con más entradas totales y con mejor eficiencia.
Unidades de ejecución
Si las filtraciones son ciertas, la nueva Zen 5 tendría:
- 6 ALUs: encargadas de realizar operaciones aritmeticológicas en paralelo, es decir, es un sistema superescalar capaz de procesar 6 operaciones a la vez. Esto se traduciría en un aumento del procesamiento escalar de instrucciones comunes en un 50% por ciclo. Aunque esto podría tener un impacto no demasiado alto, como podría parecer. Y es que lo importante es que el scheduler mantenga todas estas unidades alimentadas para que estén
- trabajando constantemente y evitar la mayor parte de tiempos muertos o idle.
- 4 Load/ 2 Store: por otro lado, también viene con capacidad para realizar 4 cargas y 2 almacenamientos por cada ciclo. Esto podría ayudar en escenarios específicos, aunque no sabemos muy bien cuánto podrá afectar a otros casos más genéricos.
- 4 AGUs: estas unidades, Address Generation Unit (también se llama ACU o Address Computation Unit), para el manejo de memoria (calcula direcciones de memoria principal usada por la CPU para los accesos) se encontrarán en un número de cuatro.
Esto en cuanto al cauce de enteros, pero también tenemos el de coma flotante, con una FPU especial de 512-bit de longitud para operaciones vectoriales, como las SIMD (SSE, AVX,…). En el que se puede apreciar en la imagen:
- FMUL: se trata de una FPU capaz de realizar de forma eficiente la multiplicación de dos operandos y obtener el resultado.
- FADD: similar al anterior, pero en este caso son sumas de coma flotante en vez de multiplicaciones.
- FMA: es la operación Fused Multiply–Add, como su propio nombre indica, se encarga de una operación fusionada, multiplicando y sumando a la vez, en un solo paso.
ROB
Una CPU OoOE, como la que siguen el algoritmo de Tomasulo, como la mayoría de las modernas, tiene estructuras para realizar un seguimiento del estado de las instrucciones hasta que sus resultados se vuelvan definitivos. El tamaño de estas estructuras tiende a aumentar con cada generación de CPU. La diapositiva filtrada sugiere que Zen 5 también lo hará, pero no entra en detalles específicos.
Según el benchmark Cinebench, algunos problemas de rendimiento en Zen 4 se deben a su tamaño del buffer de reordenamiento (ROB o Re-Order Buffer). Quizás en AMD han tomado nota de esto y hagan una mejora en Zen 5 para la alegría de los gamers.
Es decir, en Zen 5 casi con certeza verá un aumento también, pero no sabemos en qué medida. Junto con un aumento en la capacidad del búfer de reordenamiento, AMD deberá mejorar otras estructuras para evitar que se llenen antes que el búfer de reordenamiento, de lo contrario no sería lógico. Por ejemplo, la cola de almacenamiento (queue) podría utilizar más entradas y es un candidato principal para la optimización. Sin embargo, aumentar el tamaño de la cola de almacenamiento será difícil porque debe contener datos de almacenamiento pendientes. Para Zen 4, eso puede llegar a ser de hasta 32 bytes por almacenamiento.
Por otro lado, la diapositiva habla sobre almacenamiento en caché. «Fills» se refiere a llenado de caché, y «victim» se refiere a las líneas expulsadas de una caché para hacer espacio para los datos que se están llenando. Como la inmensa mayoría de las CPUs recientes, es de esperar que Zen 5 también conserve los 64-bytes, es decir, que los datos entrarán en bloques de 64 B y saldrán también en 64 B…
Data-Prefectch
Un mejor almacenamiento en caché y una mayor capacidad de reordenamiento ayudan a abordar el problema de latencia de memoria. El prefetching contrarresta la latencia de memoria al intentar obtener datos que el programa necesitará antes de que una instrucción los solicite.
En Zen 4, AMD tiene prefetchers a nivel de L1D y L2. Es posible que Zen 5 mantenga los mismos métodos de prefetching pero que sean más eficientes, permitiendo aprovechar más el ancho de banda ofrecido por las nuevas memorias DDR5.
FPU especial para SIMD AVX-512
Intel, como bien sabes, incluyó unidades FPU de 512-bit de ancho y registros especiales para las extensiones de instrucciones SIMD que trabajan de forma vectorial, como son las AVX-512. Esto supuso serios problemas en sus procesadores para el escritorio, ya que carecía de sentido en ese momento y agregaba un gran tamaño al die para albergar estas unidades tan grandes, y un mayor consumo. Algo que le valió las críticas de muchos expertos del sector, incluso del mismo Linus Torvalds, que dejó de usar Intel para pasar a AMD Threadripper.
AMD fue cauta, y no agregó las AVX-512 hasta Zen 4. Por otro lado, Intel parece haberlas desactivado en sus últimas generaciones, y solo están presentes en los Xeon para HPC. En el caso de AMD, incluir AVX-512 no parece haber generado tantos problemas como al caso de Intel. Además, AMD hizo algo ingenioso, y es que no dividía las instrucciones AVX en dos micro-operaciones, para ejecutar de 256 en 256 bits, sino que solo usa una micro-operación por instrucción.
Como puedes apreciar en la imagen, se aprecia FP Pipe/Units 512b, y algunos expertos aseguran que Zen 5 podría llegar con capacidad de ejecutar vectores de coma flotante de 2×512-bit. Pero parece que con los 4nm de TSMC eso sería demasiado optimista, con un área demasiado grande y mayor consumo, lo que no merecería la pena teniendo en cuenta las pocas cargas de trabajo que realmente usan estos vectores tan largos.
Pero, como vimos en el roadmap, Zen 5 se implementará también en 3nm, por lo que es probable que veamos dos diseños con variaciones en el FP, como una versión para escritorio y portátiles con 1×512 y otra más potente para HPC de 2×512 para EPYC, lo que sería brutal. Con un tamaño de fabricación más reducido, el impacto de área y consumo no serían tan grandes.
¿Suficiente para batir al Intel Core Ultra de 14ª Generación (Meteor Lake)? Solo el tiempo dirá…