
Los modernos procesadores han comenzado a implementar SMT para poder manejar más de un hilo o thread de forma simultánea. En este tutorial te explicaremos todo lo que tienes que conocer acerca de estos elementos de los programas o procesos y cómo se gestionan.
¿Qué es un hilo o thread?
En informática, un hilo o thread es una secuencia de instrucciones que puede ejecutarse de forma independiente dentro de un proceso. Un proceso puede contener uno o varios hilos, y cada hilo tiene su propio flujo de ejecución, estado y conjunto de registros. Los hilos comparten recursos como la memoria y los archivos abiertos dentro del proceso en el que se encuentran.
Los hilos permiten una ejecución concurrente y paralela de tareas dentro de un proceso, lo que puede mejorar el rendimiento y la capacidad de respuesta de las aplicaciones. Múltiples hilos pueden ejecutarse en paralelo en múltiples núcleos de un procesador o en un solo núcleo mediante la técnica de conmutación de hilos.
Los hilos pueden comunicarse y sincronizarse entre sí mediante mecanismos de sincronización, como semáforos, mutex (exclusión mutua) o variables de condición. Esto permite la coordinación y la cooperación entre hilos para compartir datos o realizar tareas de manera sincronizada.
Los hilos se utilizan ampliamente en aplicaciones multitarea y en sistemas operativos para realizar tareas concurrentes, como la gestión de solicitudes de red, el procesamiento paralelo de datos, la interfaz de usuario interactiva y la ejecución de operaciones en segundo plano. Sin embargo, el uso incorrecto de hilos puede dar lugar a problemas de concurrencia, como condiciones de carrera y bloqueos, que requieren una correcta sincronización y gestión para evitar comportamientos no deseados.
Un ejemplo de código en C simple con creación de threads o hilos sería:
#include <stdio.h>
#include <pthread.h>
#define NUM_THREADS 5
// Función que será ejecutada por cada hilo
void* imprimirMensaje(void* threadId) {
int id = *((int*)threadId);
printf("¡Hola desde el hilo %d!\n", id);
pthread_exit(NULL);
}
int main() {
pthread_t threads[NUM_THREADS];
int threadIds[NUM_THREADS];
// Crear los hilos
for (int i = 0; i < NUM_THREADS; i++) {
threadIds[i] = i;
int resultado = pthread_create(&threads[i], NULL, imprimirMensaje, (void*)&threadIds[i]);
if (resultado) {
printf("Error al crear el hilo %d. Código de error: %d\n", i, resultado);
return -1;
}
}
// Esperar a que los hilos terminen
for (int i = 0; i < NUM_THREADS; i++) {
pthread_join(threads[i], NULL);
}
printf("Todos los hilos han terminado. Programa finalizado.\n");
return 0;
}
En este ejemplo, se crean e inician varios hilos usando la función pthread_create(). Cada hilo ejecuta la función imprimirMensaje(), que simplemente imprime un mensaje en la consola con el identificador del hilo. Luego, se espera a que todos los hilos finalicen usando pthread_join() antes de que el programa principal termine.
Recuerda compilar el código con la opción -pthread para enlazar correctamente con la biblioteca pthreads. Por ejemplo: gcc programa.c -o programa -pthread.
Este código ilustra cómo crear y ejecutar múltiples hilos simultáneamente en un programa en C. Cada hilo se ejecuta de manera independiente, lo que permite una ejecución concurrente y paralela de tareas dentro del programa.
¿Qué es multithreading?
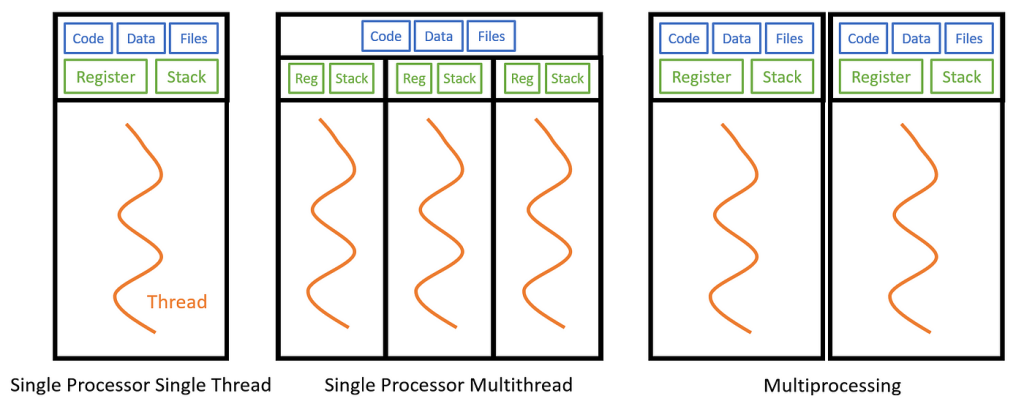
El multithreading se refieren a la capacidad de una unidad central de procesamiento (CPU) o un solo núcleo en un procesador multinúcleo para ejecutar múltiples subprocesos simultáneamente, con el respaldo del sistema operativo. Esta capacidad difiere del enfoque de multiprocesamiento. En un entorno de subprocesos múltiples, los subprocesos comparten los recursos de uno o varios núcleos, que incluyen unidades de cómputo, cachés de la CPU y la memoria de traducción de direcciones (TLB).
Por ejemplo, un proceso con dos subprocesos de ejecución puede ejecutarse en un solo procesador. El subproceso 1 se ejecuta primero, luego inicia el subproceso 2 y espera una respuesta. Una vez que el subproceso 2 ha finalizado, indica al subproceso 1 que reanude su ejecución hasta su finalización, y luego termina.
Cuando los sistemas de multiprocesamiento incluyen múltiples unidades de procesamiento completas en uno o más núcleos, el objetivo del multiproceso es aumentar la utilización de un solo núcleo mediante el uso de paralelismo tanto a nivel de subprocesos como a nivel de instrucciones. Dado que estas dos técnicas son complementarias, se combinan en la mayoría de las arquitecturas de sistemas modernos que utilizan CPUs con múltiples subprocesos y múltiples núcleos.
El paradigma de subprocesos múltiples se ha vuelto más popular a medida que los esfuerzos por aprovechar aún más el paralelismo a nivel de instrucciones se han estancado desde finales de la década de 1990. Esto ha permitido que el concepto de computación de rendimiento vuelva a surgir del campo más especializado del procesamiento de transacciones. Aunque es difícil acelerar aún más un solo hilo o programa, la mayoría de los sistemas informáticos son multitarea, ejecutando múltiples hilos o programas a la vez. Por lo tanto, las técnicas que mejoran el rendimiento de todas las tareas resultan en mejoras generales en el rendimiento.
Un área de investigación crucial se centra en el planificador de hilos, cuya tarea consiste en seleccionar rápidamente qué hilo de ejecución debe ser ejecutado a continuación a partir de una lista de hilos listos para su ejecución, así como mantener y administrar las listas de hilos listos y detenidos. Un subtema relevante se relaciona con los diferentes esquemas de prioridad de hilos que el planificador puede utilizar. El planificador de hilos puede implementarse completamente en software, completamente en hardware, o como una combinación de ambos.
Otra área de investigación importante es determinar qué eventos deben causar un cambio de hilo, como errores de caché, comunicación entre hilos, finalización de DMA, entre otros.
Si el esquema de hilos múltiples replica todo el estado visible del software, incluyendo los registros de control privilegiados y las TLB (Translation Lookaside Buffer), se permite la creación de máquinas virtuales para cada hilo. Esto posibilita que cada hilo ejecute su propio sistema operativo en el mismo procesador. Por otro lado, si solo se guarda el estado del modo de usuario, se requiere menos hardware, lo que permitiría tener más hilos activos simultáneamente en la misma área de matriz o con un menor costo.
Ventajas del multithreading
La utilización de múltiples subprocesos ofrece ventajas significativas. Si un subproceso experimenta errores de caché, los otros subprocesos pueden continuar utilizando los recursos informáticos sin utilizar, lo que lleva a una ejecución más rápida en general. Esto se debe a que estos recursos habrían estado inactivos si solo se hubiera ejecutado un subproceso. Además, si un subproceso no puede utilizar todos los recursos informáticos de la CPU debido a dependencias de instrucciones, ejecutar otro subproceso puede evitar que esos recursos queden inactivos.
Desventajas del multithreading
Sin embargo, también existen desventajas en el uso de múltiples subprocesos. Los subprocesos pueden interferir entre sí al compartir recursos de hardware, como cachés o búferes de búsqueda de traducción (TLB). Esto puede resultar en tiempos de ejecución más largos para un solo subproceso e incluso degradación del rendimiento, incluso cuando solo se ejecuta un subproceso. Esto se debe a la necesidad de frecuencias más bajas o etapas de canalización adicionales para acomodar el hardware de conmutación de subprocesos.
La eficiencia general puede variar dependiendo de diversos factores. Por ejemplo, la tecnología Hyper-Threading de Intel afirma una mejora de hasta un 30%. Sin embargo, programas sintéticos que realizan operaciones dependientes de coma flotante pueden obtener una mejora de velocidad del 100% al ejecutarse en paralelo. Por otro lado, los programas optimizados en lenguaje ensamblador que utilizan extensiones MMX o AltiVec y realizan búsquedas previas de datos pueden no experimentar pérdidas de caché o recursos informáticos inactivos. Por lo tanto, estos programas no se benefician del hardware de múltiples subprocesos y, de hecho, pueden experimentar un rendimiento degradado debido a la competencia por los recursos compartidos.
Desde el punto de vista del software, el soporte de hardware para múltiples subprocesos es más visible y requiere cambios más significativos tanto en los programas de aplicación como en los sistemas operativos en comparación con el multiprocesamiento. Las técnicas de hardware utilizadas para admitir múltiples subprocesos a menudo se ejecutan en paralelo con técnicas de software utilizadas para la multitarea informática. La programación de subprocesos también es un desafío importante en el contexto de los múltiples subprocesos.
Multithreading a nivel de programación: cómo se crean los hilos
Antes ya puse un ejemplo de código fuente en C de uso de threads o hilos en programación, aquí dejo otro ejemplo sencillo de cómo crear y matar hilos:
En C, puedes utilizar la biblioteca
pthread.hpara crear, matar y gestionar hilos. Aquí tienes algunos ejemplos de cómo hacerlo. Para más información, también te recomiendo leer cómo funciona un programa y partes.
- Crear un hilo:
#include <stdio.h>
#include <pthread.h>
void* miFuncion(void* arg) {
// Código del hilo
return NULL;
}
int main() {
pthread_t hilo;
pthread_create(&hilo, NULL, miFuncion, NULL);
// El hilo ha sido creado y está en ejecución
pthread_join(hilo, NULL); // Espera a que el hilo termine
return 0;
}
- Matar un hilo:
#include <stdio.h>
#include <pthread.h>
void* miFuncion(void* arg) {
while (1) {
// Código del hilo
if (condicion_para_terminar) {
pthread_exit(NULL); // Termina el hilo
}
}
return NULL;
}
int main() {
pthread_t hilo;
pthread_create(&hilo, NULL, miFuncion, NULL);
// El hilo ha sido creado y está en ejecución
pthread_cancel(hilo); // Mata el hilo
pthread_join(hilo, NULL); // Espera a que el hilo termine
return 0;
}
- Gestionar hilos con variables compartidas:
#include <stdio.h>
#include <pthread.h>
int variable_compartida = 0;
void* miFuncion(void* arg) {
int valor_local = *(int*)arg;
variable_compartida += valor_local; // Modifica la variable compartida
return NULL;
}
int main() {
pthread_t hilo1, hilo2;
int valor1 = 1, valor2 = 2;
pthread_create(&hilo1, NULL, miFuncion, &valor1);
pthread_create(&hilo2, NULL, miFuncion, &valor2);
// Los hilos han sido creados y están en ejecución
pthread_join(hilo1, NULL); // Espera a que el hilo1 termine
pthread_join(hilo2, NULL); // Espera a que el hilo2 termine
printf("Valor final de la variable compartida: %d\n", variable_compartida);
return 0;
}
Estos ejemplos ilustran cómo crear hilos usando pthread_create(), cómo terminarlos usando pthread_exit() o pthread_cancel(), y cómo gestionar variables compartidas entre hilos. Recuerda incluir la biblioteca pthread.h y enlazar el programa con la opción -pthread al compilar para utilizar las funciones y tipos relacionados con los hilos.
Multithreding vs otros paradigmas similares
El multithreading se distingue del multitasking y el multiprocessing. Sin embargo, el multitasking y el multiprocessing están relacionados con el multithreading de las siguientes formas:
- El multitasking es la capacidad de una computadora para ejecutar dos o más programas concurrentemente. El multithreading hace posible el multitasking al dividir los programas en subprocesos más pequeños que pueden ejecutarse de manera independiente. Cada subproceso contiene los elementos de programación necesarios para ejecutar el programa principal, y la computadora ejecuta los subprocesos uno a la vez.
- El multiprocessing utiliza más de una CPU para acelerar el procesamiento general y admite el multitasking.
Cuando se trata de multithreading frente a procesamiento paralelo y procesadores multinúcleo:
- El procesamiento paralelo implica el uso de dos o más CPUs para manejar partes separadas de una tarea. En un sistema de procesamiento paralelo, varias tareas pueden ejecutarse simultáneamente. Esto es diferente al uso de una sola CPU, donde solo se ejecuta un subproceso a la vez y las tareas que componen un subproceso se programan secuencialmente.
- Los MP o Multiprocessors en una placa base de CPU tienen múltiples unidades de procesamiento o núcleos independientes. A diferencia de las CPUs de un solo núcleo, que tienen una sola unidad de procesamiento. Los procesadores multinúcleo ofrecen mayor velocidad y capacidad de respuesta en comparación con los procesadores de un solo núcleo.
- Los procesadores multinúcleo pueden ejecutar simultáneamente tantos subprocesos como núcleos de CPU disponibles. Esto significa que diferentes partes de una tarea se pueden completar más rápidamente. En un sistema de un solo núcleo, los subprocesos de una aplicación multiproceso no se ejecutan en paralelo, sino que comparten un solo núcleo de procesador.
¿Qué es el Super-Threading?
El subprocesamiento temporal, o Super-Threading, es una de las dos formas principales de implementar el multithreading en el hardware del procesador. La otra forma es el SMT del que hablaré en el siguiente apartado. La diferencia clave entre estas dos formas radica en el número máximo de subprocesos que se pueden ejecutar simultáneamente en una etapa de canalización en un ciclo determinado. En el subprocesamiento temporal, este número es uno, mientras que en el subprocesamiento simultáneo es mayor a uno.
Tanto en el multihilo temporal como en el simultáneo, el hardware debe almacenar un conjunto completo de estados para cada subproceso concurrente implementado. Además, el hardware debe crear la ilusión de que cada subproceso tiene los recursos del procesador exclusivamente para sí mismo. En ambos casos, se deben utilizar algoritmos de equidad para evitar que un subproceso domine el tiempo de ejecución y/o los recursos del procesador.
En comparación con el SMT, el multihilo temporal tiene la ventaja de generar menos calor por parte del procesador. Sin embargo, solo se permite la ejecución de un subproceso a la vez.
Tipos de Super-Threading
El multithreading se refiere a la capacidad de un sistema para ejecutar múltiples hilos o subprocesos de manera concurrente. Dependiendo de cómo se divide y administra el trabajo entre los hilos, se pueden distinguir dos enfoques diferentes:
- Grano fino: también conocido como multithreading a nivel de hilo o threading a nivel de instrucción, implica la ejecución de hilos pequeños y rápidos que se alternan con frecuencia. En este enfoque, el sistema operativo puede tomar decisiones de cambio de contexto a nivel de instrucción, permitiendo una mayor utilización de los recursos de la CPU. Esto se logra dividiendo la ejecución de cada hilo en instrucciones más pequeñas y alternando su ejecución en ciclos de reloj individuales. El multithreading de grano fino es beneficioso en escenarios en los que las instrucciones pueden ser intercaladas fácilmente, lo que permite una mayor utilización de los recursos de la CPU y una ejecución más eficiente.
- Grano grueso: también conocido como multithreading a nivel de tarea o threading a nivel de usuario, implica la ejecución de hilos más grandes y con mayor duración. En lugar de alternar entre instrucciones individuales, el sistema operativo alterna la ejecución entre tareas o subprocesos completos. Cada hilo se ejecuta durante un período de tiempo más largo antes de que se realice el cambio de contexto. El multithreading de grano grueso es beneficioso en situaciones en las que las tareas son más grandes y no se pueden intercalar fácilmente, permitiendo una mayor división del trabajo y una mejor asignación de recursos.
La elección entre el multithreading de grano fino y grueso depende del tipo de aplicaciones y tareas que se ejecuten, así como de las características y capacidades del hardware y el sistema operativo en uso. Ambos enfoques tienen ventajas y desventajas, y su implementación óptima puede variar según los requisitos y características específicas del sistema.
¿Qué es el SMT?
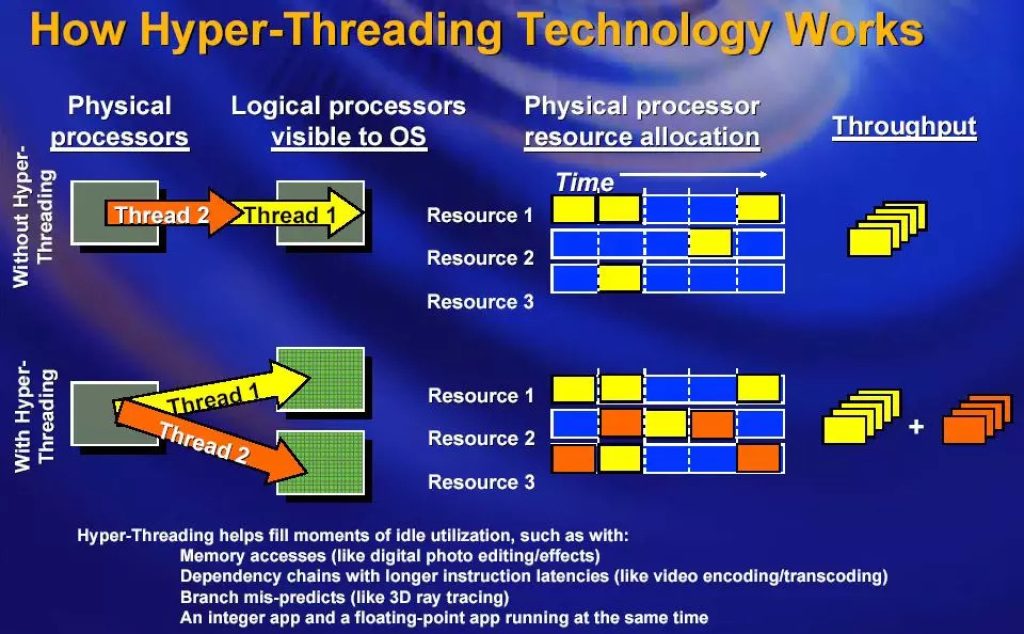
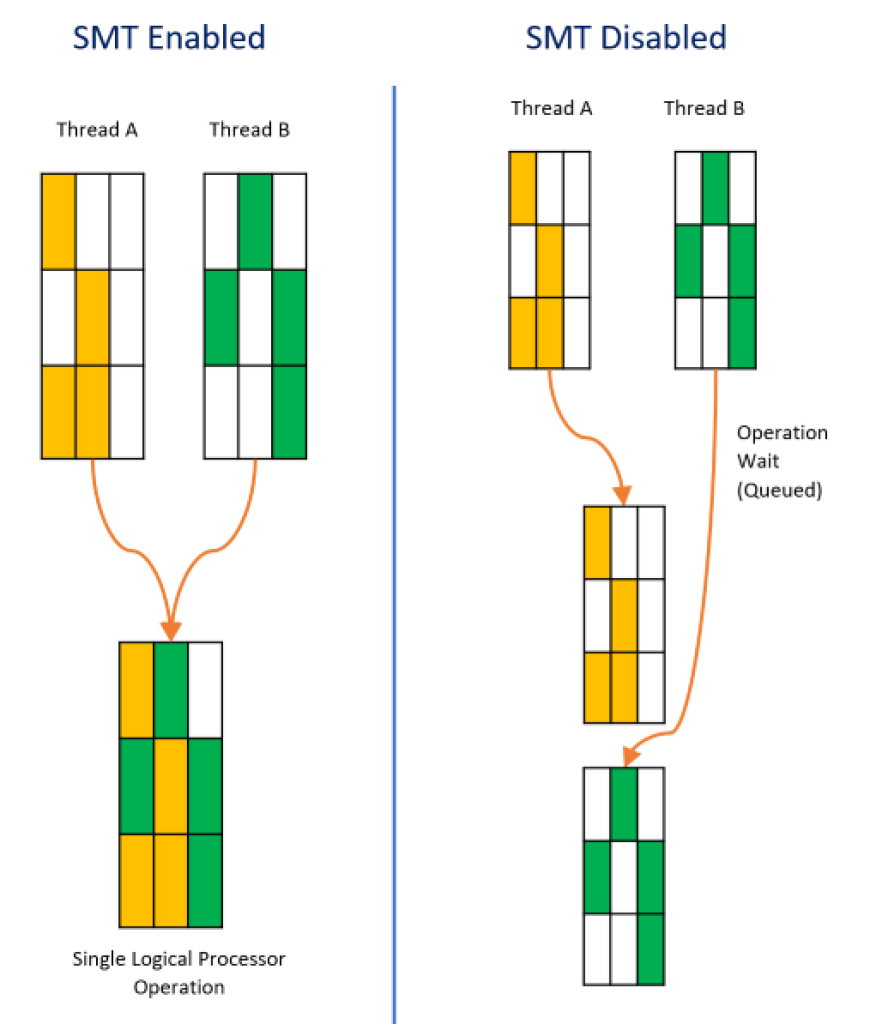
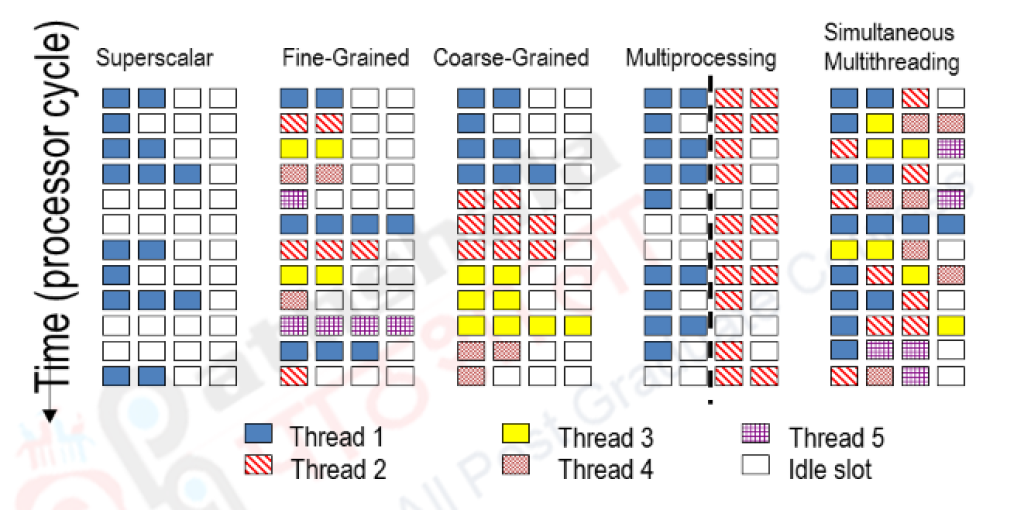
El Simultaneous MultiThreading (SMT) es una técnica utilizada para mejorar la eficiencia de las CPU superescalares que cuentan con subprocesos múltiples de hardware. SMT permite que varios subprocesos de ejecución independientes utilicen de manera más eficiente los recursos proporcionados por las arquitecturas modernas de procesadores.
Sabías que una de las primeras implementaciones de SMT fue en DEC (Digital Equipment Corp) para sus procesadores Alpha EV8, aunque finalmente no se llegó a completar el proyecto una vez adquirido por Compaq. Luego vino Intel HT o HyperThreading, así como el SMT presente en otras CPUs conocidas como las IBM POWER5 en adelante, las IBM z13 en adelante, Sun Microsystems UltraSPARC T2 en adelante, AMD Zen, etc. Además, debes saber que existe SMT 2-way (o SMT2), como el de AMD o Intel, pero también puede haberlo 4-way (o SMT4), 8-way (SMT8), etc. Es decir, en un 2-way, cada núcleo físico puede desdoblarse como si fuesen dos núcleos lógicos para ejecutar los dos hilos en paralelo. En un 4-way, cada núcelo físico se podría encargar de hasta 4 hilos simultáneamente, y así sucesivamente…
El término SMT puede resultar ambiguo, ya que no solo implica la ejecución simultánea de múltiples hilos en un núcleo de CPU, sino también la ejecución simultánea de múltiples tareas, cada una con sus propias tablas de páginas, segmentos de estado de tareas, anillos de protección, permisos de E/S, etc. Aunque estos subprocesos se ejecutan en el mismo núcleo, están completamente separados entre sí. El subprocesamiento múltiple es similar al concepto de multitarea preventiva, pero se implementa a nivel de ejecución de subprocesos en los procesadores superescalares modernos.
En SMT, las instrucciones de varios hilos pueden ejecutarse simultáneamente en una etapa de canalización determinada, sin realizar cambios significativos en la arquitectura básica del procesador. Las principales adiciones necesarias son la capacidad de obtener instrucciones de múltiples subprocesos en un ciclo y un archivo de registros más grande para contener los datos de los subprocesos. El número de subprocesos simultáneos es determinado por los diseñadores de los chips, siendo común tener dos subprocesos simultáneos por núcleo de CPU, aunque algunos procesadores pueden admitir hasta ocho subprocesos simultáneos por núcleo.
Si bien el SMT puede aumentar los conflictos sobre los recursos compartidos, medir su eficacia puede resultar desafiante y puede haber diferentes opiniones al respecto. Sin embargo, se ha demostrado que el SMT es altamente eficiente. En sistemas modernos, el SMT aprovecha eficazmente la concurrencia con un aumento mínimo en la potencia dinámica. Es decir, incluso cuando las mejoras de rendimiento son mínimas, los ahorros de consumo de energía pueden ser significativos.
En la mayoría de los casos actuales, el SMT se emplea para ocultar la latencia de la memoria, aumentar la eficiencia y mejorar el rendimiento de los cálculos en función de la cantidad de hardware utilizado.
¿Qué es HyperThreading o HT?
Con esto hay mucha confusión, pero Intel HT o HyperThreading no es más que una marca comercial para designar a la implementación de SMT que ha hecho Intel para sus procesadores. Es decir, se puede decir que HT es el SMT de Intel. En cambio, otros como IBM, AMD, etc., no han patentado ninguna marca para designarlo, simplemente lo han implementado y se denomina con el término genérico: SMT.
Pero no te lleves a confusión. HT es lo mismo… Además, en una época hubo también algunas confusiones en cuanto a Intel HyperThreading o HT y AMD HyperTransport, alegando algunos que era lo mismo. Y la verdad es que no lo es, mientras Intel HT es SMT, AMD HyperTransport es una tecnología de bus. No tienen nada que ver…
¿Qué es el Speculative Multithreading o TLS?
La Thread Level Speculation (TLS), también conocida como Speculative Multithreading o paralelización especulativa, es una técnica que permite ejecutar especulativamente una sección de código que se espera que se ejecute en paralelo en un subproceso independiente en el futuro. Este subproceso especulativo puede hacer suposiciones sobre los valores de las variables de entrada. Si estas suposiciones resultan ser incorrectas, las partes del subproceso especulativo que dependen de estas variables de entrada deben descartarse y anularse. Si las suposiciones son correctas, el programa puede completarse más rápidamente, siempre y cuando el subproceso se haya programado eficientemente.
TLS extrae hilos del código secuencial y los ejecuta especulativamente en paralelo con un subproceso seguro. El subproceso especulativo puede descartarse o volver a ejecutarse si las suposiciones sobre el estado de entrada resultan ser inválidas. Es una técnica de paralelización dinámica, lo que significa que se descubre el paralelismo en tiempo de ejecución, que las técnicas de paralelización estática en tiempo de compilación pueden no aprovechar debido a la falta de garantías de independencia de subprocesos en el momento de la compilación. Para que esta técnica logre su objetivo de reducir el tiempo de ejecución global, debe haber recursos de CPU disponibles que puedan ejecutarse eficientemente en paralelo con el subproceso principal seguro.
TLS asume de manera optimista que cierta parte del código, generalmente bucles, se puede ejecutar de forma segura en paralelo. Para lograrlo, divide el espacio de iteración en fragmentos que se ejecutan en paralelo por diferentes subprocesos. Un monitor de hardware o software garantiza que se mantenga la semántica secuencial, es decir, que la ejecución progrese como si el bucle se estuviera ejecutando secuencialmente. Si se produce una violación de dependencia, el marco especulativo puede optar por detener toda la ejecución paralela y reiniciarla, detener y reiniciar los subprocesos ofensivos y todos sus sucesores para que reciban los datos correctos, o detener exclusivamente el subproceso infractor y sus sucesores que hayan consumido datos incorrectos.
¿Qué es CMT?
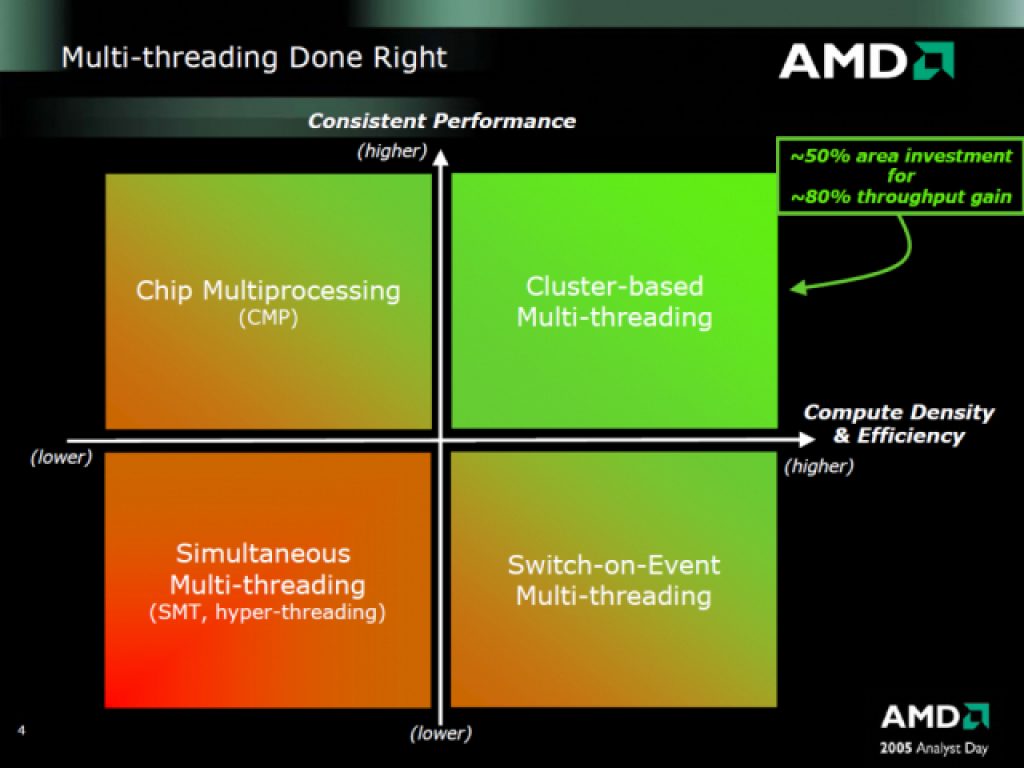
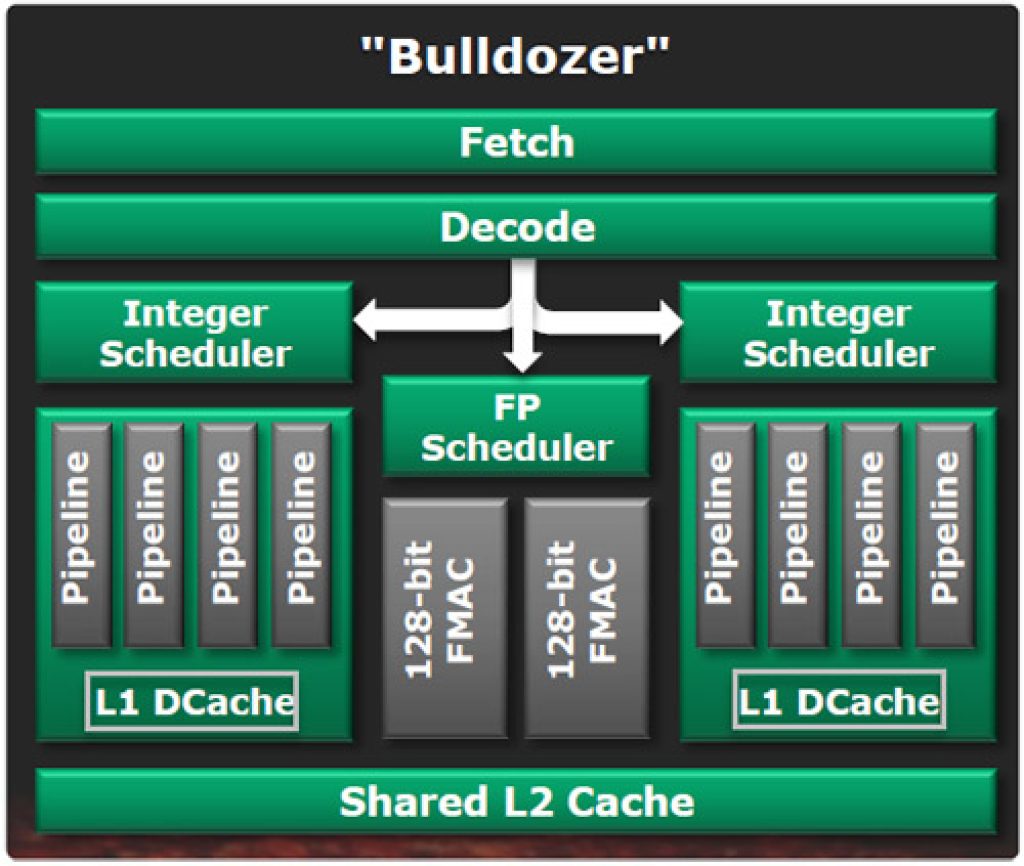
AMD usó una técnica conocida como Clustered Multithreading (CMT), donde algunas partes del procesador son compartidas entre dos hilos o threads, mientras que otras partes son exclusivas de cada hilo. Esta aproximación a SMT no convencional se remonta al UltraSPARC T1 de Sun Microsystems en 2005. En términos de complejidad y funcionalidad del hardware, un módulo CMT es equivalente a un procesador de doble núcleo en cuanto a capacidad de cálculo de enteros, y a un procesador de un solo núcleo o de doble núcleo deshabilitado en términos de capacidad computacional de punto flotante. Y en su momento hubo controversia, ya que muchos denunciaron el hecho de que realmente no eran dos núcleos lo que AMD les estaba vendiendo en su día con Bulldozer, sino un solo núcleo entero.
CMT es, de cierta manera, una filosofía de diseño más simple pero similar a SMT. Ambos diseños buscan utilizar eficientemente las unidades de ejecución. En ambos métodos, cuando dos subprocesos compiten por las mismas canalizaciones de ejecución, puede haber una pérdida de rendimiento en uno o más de los subprocesos. Debido a los núcleos enteros dedicados, los módulos de la familia Bulldozer funcionaron aproximadamente como un procesador de doble núcleo y doble subproceso en secciones de código que eran completamente enteras o una combinación de cálculos enteros y de punto flotante. Sin embargo, debido al uso de SMT en las canalizaciones de punto flotante compartidas, el módulo funcionaría de manera similar a un procesador SMT de un solo núcleo y doble subproceso (SMT2) para un par de subprocesos que estén saturados con instrucciones de punto flotante. Estas comparaciones suponen que el procesador tiene un núcleo de ejecución igualmente amplio y capaz en cuanto a números enteros y punto flotante, respectivamente.
Tanto CMT como SMT alcanzan su máxima eficiencia al ejecutar código entero y de punto flotante en un par de hilos. CMT mantiene su eficiencia máxima cuando trabaja con un par de subprocesos que consisten en código entero, mientras que bajo SMT, uno o ambos subprocesos pueden tener un rendimiento inferior debido a la competencia por las unidades de ejecución de enteros. La desventaja de CMT es que puede haber un mayor número de unidades de ejecución de enteros inactivas cuando se ejecuta un solo subproceso. En el caso de un solo subproceso, CMT se limita a utilizar como máximo la mitad de las unidades de ejecución de enteros en su módulo, mientras que SMT no impone tal limitación. Teóricamente, un núcleo SMT grande con circuitos enteros tan amplios y rápidos como dos núcleos CMT podría tener hasta el doble de rendimiento en un solo hilo en un momento dado. Sin embargo, en general, utilizando el código completo, la regla de Pollack estima un factor de aceleración de √2, lo que equivale a un aumento de rendimiento del 40%.
Cómo se cambia de contexto o hilo
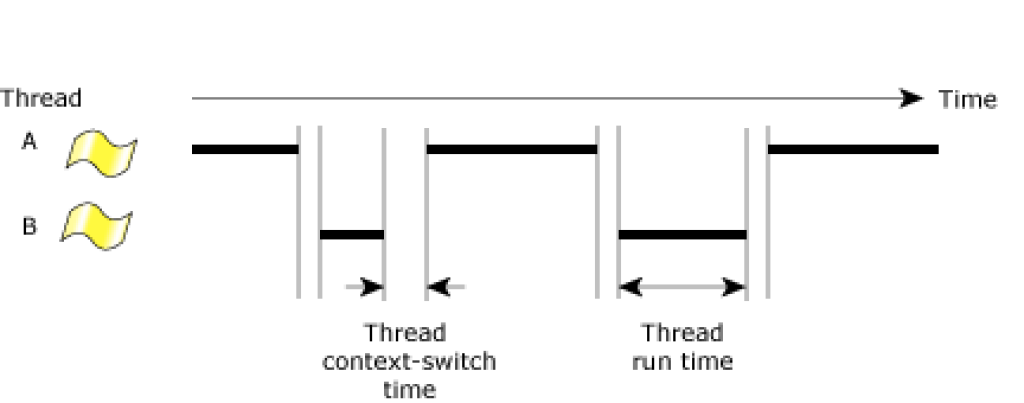
Para finalizar, vamos a ver cómo se podría cambiar de hilo o de thread, es decir, realizar un cambio de contexto a nivel de hilos:
A nivel de CPU
Un procesador cambia de contexto entre hilos cuando así lo indica el sistema operativo. El sistema operativo determina cuándo realizar el cambio de contexto en función de diversos factores, como la prioridad de los hilos y la disponibilidad de recursos de procesamiento. Por ejemplo, si un hilo de alta prioridad está listo para ejecutarse mientras el procesador está ejecutando actualmente un hilo de baja prioridad, el sistema operativo puede decidir realizar un cambio de contexto y pasar al hilo de alta prioridad. Esto permite que el procesador aproveche mejor su tiempo de procesamiento y garantiza que las tareas importantes se les otorgue prioridad sobre las menos importantes.
¿Sabías que para memorar la latencia puedes desactivar desde el BIOS/UEFI la tecnología SMT? Sí, cuando estás desactivada mejora la latencia, aunque también se perderá rendimiento cuando nos referimos a procesamiento paralelo de hilos…
Algunas personas se preguntan cuánto puede tardar en hacer ese cambio de contexto de hilos la CPU, pero no hay una respuesta numérica para tu pregunta, ya que hay demasiados factores involucrados. Para obtener una respuesta numérica, tendrías que definir una configuración específica de hardware y software, y luego realizar mediciones cuidadosas. A continuación, enumero lo necesario para el cambio de contexto, aunque la lista no es totalmente completa, pero te puedes hacer una buena idea de lo que ocurre:
- Cambio en el planificador de tareas en el sistema operativo (o en una aplicación independiente dentro de un sistema embebido).
- Limpieza de la TLB (Translation Lookaside Buffer), si corresponde.
- En qué medida se comparte la memoria caché de la CPU entre múltiples tareas.
- El tamaño de la memoria caché de la CPU, el número de niveles de caché, la velocidad de cada nivel de caché y el estado actual de la caché.
- Si se está cambiando entre dos hilos dentro del mismo procesador o hilos que forman parte de dos procesos diferentes.
- Si el cambio de contexto se realiza principalmente mediante software o mediante hardware:
- Cuánto soporte de cambio de contexto proporciona el procesador.
- Si el sistema operativo (o la aplicación en un sistema embebido) utiliza el soporte de hardware para el cambio de contexto.
- La combinación de qué registros se guardan automáticamente mediante hardware y cuáles deben guardarse mediante software.
- Si el software puede seleccionar qué registros deben guardarse selectivamente (en lugar de guardar todos).
- La velocidad del reloj de la CPU, que puede verse afectada por el control de temperatura, mecanismos temporales de «impulso», etc.
- La velocidad de la RAM.
- Si ocurre o no un fallo de página para llevar el código del hilo al que se cambia a la RAM. En ese punto, entran en juego la velocidad del bus de E/S, el controlador de almacenamiento y el dispositivo de almacenamiento.
- Cómo se desencadena el cambio de contexto (por ejemplo, mediante una interrupción, una excepción, una instrucción de llamada o salto, etc.).
A nivel de sistema operativo
Un cambio de contexto de hilo o thread a nivel del sistema operativo ocurre cuando el procesador suspende la ejecución de un hilo y pasa el control a otro hilo en ejecución. Este cambio se produce debido a eventos como la planificación del procesador, una interrupción del hardware, una llamada al sistema o la finalización de un hilo.
El proceso de cambio de contexto generalmente sigue los siguientes pasos:
- Guardar el contexto actual: el sistema operativo guarda el estado actual del hilo que está siendo ejecutado, incluyendo los registros del procesador, el contador de programa y otros datos relevantes. Esta información se almacena en la estructura de control del hilo o en la pila del kernel.
- Selección del siguiente hilo: selecciona el siguiente hilo que será ejecutado. La elección puede basarse en diferentes políticas de planificación, como prioridad, tiempo de espera, algoritmos de colas, entre otros.
- Restaurar el contexto del siguiente hilo: el SO recupera el contexto del hilo seleccionado previamente. Esto implica restaurar los registros del procesador, el contador de programa y otros datos necesarios para que el hilo pueda continuar su ejecución.
- Cambio de ejecución: finalmente transfiere el control al hilo seleccionado, permitiéndole continuar su ejecución desde el punto en el que fue suspendido.
Es importante destacar que el cambio de contexto es una operación costosa en términos de rendimiento, ya que implica la transferencia y almacenamiento de información del hilo. Por lo tanto, los sistemas operativos buscan optimizar esta operación para minimizar su impacto en el rendimiento general del sistema.