- Arm Lumex CSS integra CPU C1, GPU Mali G1 y SME2 para llevar la IA al dispositivo con baja latencia y alta eficiencia.
- Los núcleos C1 escalan hasta 14 por SoC, con mejoras notables en IPC, cachés y un DSU que reduce consumo del sistema.
- Mali G1-Ultra duplica el ray tracing y acelera la inferencia de IA (+20%), con red interna y caché L2 ampliadas.
- SME2 multiplica el rendimiento de IA en CPU (hasta 3,7–5x) y se activa vía frameworks como PyTorch o ONNX Runtime.

La pregunta del millón es qué es exactamente Arm Lumex CSS y por qué todo el mundo en tecnología móvil y PC habla de ello. Hablamos de una plataforma “AI-first” que une nuevos clústeres de CPU, una GPU completamente renovada, un tejido de interconexión más eficiente y un paquete de software listo para producción, todo pensado para que la inteligencia artificial suceda directamente en el dispositivo.
En otras palabras, Lumex CSS no es solo una familia de chips ni un simple refrito de nombres: es el subsistema de cómputo de Arm para acelerar IA a escala, desde gamas asequibles hasta buques insignia, con mejores tiempos de salida al mercado y soporte profundo para desarrolladores. Y sí, trae novedades muy jugosas: nuevos núcleos C1, GPU Mali G1 con ray tracing de segunda generación y la extensión SME2 para multiplicar el rendimiento de IA en CPU.
Qué es Arm Lumex CSS y qué persigue

Arm Lumex CSS es el “Compute Subsystem” de nueva generación de Arm. Integra CPU, GPU, interconexión y físicas de 3 nm con una capa de software (drivers, bibliotecas y marcos de trabajo) lista para que los fabricantes diseñen SoC personalizados con gran rapidez. Su objetivo es claro: llevar experiencias de IA en tiempo real al dispositivo, reduciendo latencia, mejorando privacidad y ahorrando costes frente a la nube.
La clave diferencial está en que todo se ha diseñado con IA en mente: las CPU C1 pueden asumir cargas de IA pequeñas y medianas sin salir de la CPU gracias a SME2; la GPU Mali G1 acelera inferencia y duplica el ray tracing; y el tejido de interconexión reduce consumos y cuellos de botella en memoria para exprimir cada vatio.
Componentes principales de Lumex CSS
La plataforma se apoya en tres pilares: núcleos de CPU C1 Series, GPU Mali G1 Series y la extensión SME2 para IA en CPU. Todo ello, cosido por un sistema de interconexión y cachés SLC optimizados, y respaldado por diseños físicos listos para fabricar en 3 nm con enfoque multifundición.
Además, el ecosistema de software está integrado desde el primer día: Android 16, kernel Linux, motores de juego como Unity/Unreal, y marcos de IA como PyTorch (ExecuTorch), Google LiteRT, Alibaba MNN u ONNX Runtime, con Arm KleidiAI facilitando la aceleración SME2 sin tocar código.
CPU Arm C1 Series: arquitectura y variantes

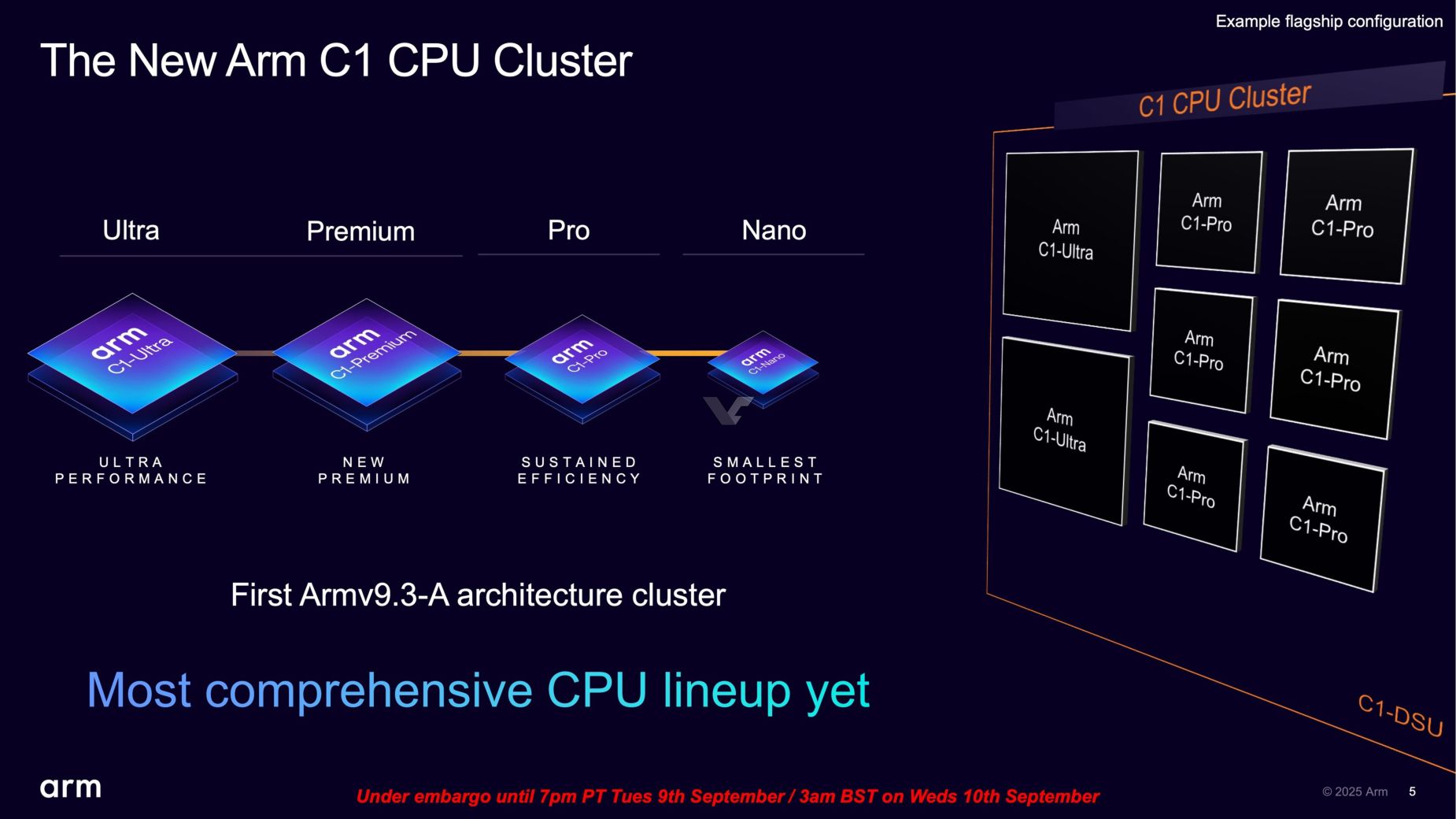
Los nuevos núcleos llegan con una nomenclatura más simple: C1-Ultra, C1-Premium, C1-Pro y C1-Nano, de mayor a menor rendimiento. Arm abandona así “Cortex” para ofrecer un esquema claro y escalable, con configuraciones mixtas en el mismo clúster y soporte de hasta 14 núcleos por SoC.
La familia C1 presume de ganancias de IPC de doble dígito, mejoras notables en predicción de saltos, ventanas de ejecución fuera de orden más grandes y anchos de banda de caché superiores, todo ello orientado a subir el rendimiento sostenido sin disparar el consumo.
- C1-Ultra: tope de gama, hasta un 25% más de rendimiento monohilo frente a la generación anterior y un salto de hasta el 45% en cargas multinúcleo en CPU con clúster C1.
- C1-Premium: orientado a alto rendimiento con menor área (aprox. 35% menos vs Ultra), pensado para gamas altas que busquen gran relación potencia/espacio.
- C1-Pro: equilibrio entre rendimiento y eficiencia, sucesor natural de A725/A78, con mejoras en torno al 11% por vatio y hasta un 16% más en juegos con el mismo consumo.
- C1-Nano: mínimo consumo y tamaño, con un 26% de mejor eficiencia frente a su predecesor, ideal para dispositivos muy compactos o de autonomía crítica.
Más allá de los nombres, Arm ha retocado el Front-End para aumentar el caudal de instrucciones y la precisión de las predicciones, y el Back-End para digerir ventanas de ejecución fuera de orden más amplias (en torno a 2.000 instrucciones), además de duplicar la L1 en C1-Ultra hasta 128 KB y mejorar su capacidad de lectura en un 33%.
Memoria, interconexión y clústeres hasta 14 núcleos
La plataforma añade soporte para LPDDR6 (manteniendo LPDDR5x hasta 9600 MT/s) y estrena un sistema de interconexión con caché compartida basado en celdas SLC que reduce latencias y consumo. El nuevo C1-DSU (DynamIQ Shared Unit) permite diseños con hasta 14 núcleos combinando distintas variantes C1, cada una con su papel en el equilibrio global.
El C1-DSU incorpora mejoras heredadas y afinadas respecto al DSU-120, incluyendo modos de ultra bajo consumo como “L3 Quick Nap” que minimizan el desperdicio energético al activar solo los bloques necesarios de la caché. En números, hablamos de reducciones típicas de consumo del sistema del 11% y del 7% en RAM.
SME2: la CPU gana músculo en IA
La extensión Scalable Matrix Extension 2 (SME2) es el corazón de la apuesta “AI-first” en CPU. En los C1-Ultra y C1-Premium es obligatoria, mientras que en C1-Pro y C1-Nano su integración queda a elección del fabricante, incluso con aceleradores externos gestionados por el DSU a los que pueden acceder todos los núcleos.
¿Qué aporta? Multiplica el rendimiento de IA en CPU sin los costes de mover datos a GPU/NPU, con melhorias medias de 3,7x y picos que superan 4–5x en tareas como reconocimiento de voz o generación de audio, recortando además consumo en torno al 27%.
A nivel técnico, SME2 añade nuevos tipos de datos y operaciones (predicados múltiples, multiplicaciones vectoriales, compresión 2b/4b, prefetch de rangos) y convive con SVE2 para vectorización clásica, lo que se traduce en más rendimiento por ciclo y menos energía gastada por inferencia.
La adopción llega arropada por el software: Android 16, Linux, Unity, Unreal, PyTorch/ExecuTorch, LiteRT, MNN u ONNX Runtime ya contemplan la aceleración, y casos reales como Alipay/Taobao validan su impacto en producción.
GPU Mali G1: Ultra, Premium y Pro
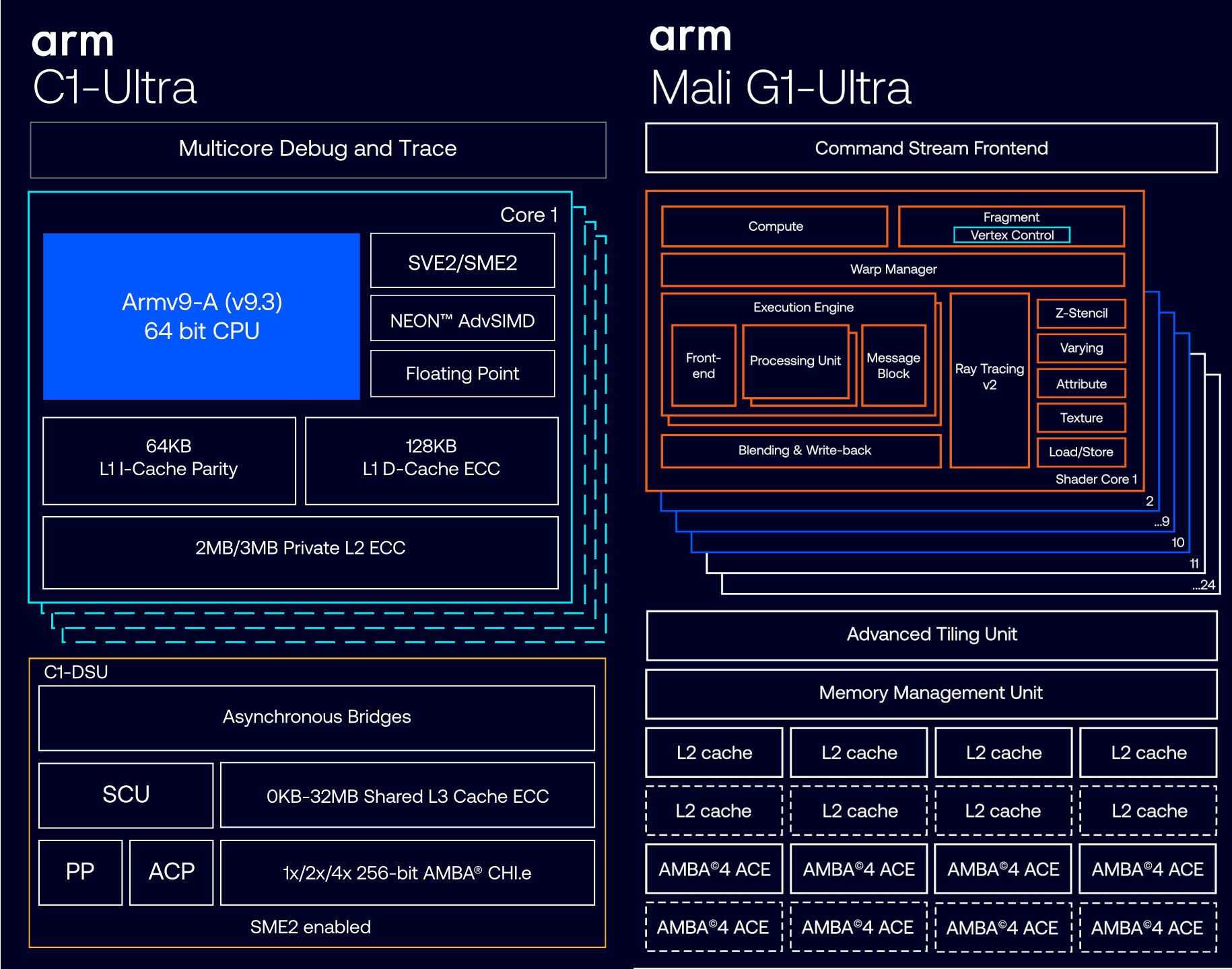
En lo gráfico, Arm simplifica la familia y pasa a Mali G1, sustituyendo la marca Immortalis por “Ultra” en la gama alta. Hay tres escalones: G1-Ultra, G1-Premium (sin RT) y G1-Pro, escalables en número de núcleos para ajustarse a cada SoC.
El titular se lo lleva Mali G1-Ultra: hasta 10+ núcleos con ray tracing de segunda generación (Arm Ray Tracing v2/RTUv2), aproximadamente el doble de rendimiento RT frente a la generación anterior, +20% de rendimiento bruto, +20% en inferencia de IA y un 9% menos de energía por fotograma.
- Mali G1-Ultra: 10 o más núcleos, RT integrado por núcleo, nueva tubería interna y más caché L2.
- Mali G1-Premium: 6–9 núcleos, idéntica base de arquitectura pero sin unidades RT para optimizar área y consumo.
- Mali G1-Pro: 1–5 núcleos, pensada para gamas contenidas, manteniendo mejoras de eficiencia y soporte IA.
En juegos actuales, Arm cita subidas de doble dígito, con títulos como Fortnite (+11%) y Genshin Impact (+17%), y mejoras superiores al 20% en benchs gráficos frente a la generación anterior, sufriendo menos estrangulamiento térmico por fotograma gracias al recorte energético.
Ray Tracing v2 y arquitectura interna
La segunda generación de ray tracing lleva una unidad RT por cada núcleo de la GPU, con capacidad de apagado selectivo cuando no hay trazado activo para ahorrar energía. El flujo de intersecciones se integra ahora en los Compute Shaders, reduciendo viajes de ida y vuelta y mejorando la latencia de la tubería.
La red interna de la GPU se ha duplicado, se han duplicado también las zonas de la caché L2 y se organiza la ejecución en doble pila de núcleos de sombreado, aumentando el ancho de banda efectivo y la escalabilidad del diseño.
Para IA, la GPU añade soporte específico a operaciones clave (como multiplicación FP16 de matrices), con saltos que superan el 20% en inferencia y picos de más del 100% en cargas concretas como ASR (reconocimiento del habla) o segmentación.
Interoperabilidad CPU–GPU–(NPU) para IA heterogénea
Lumex CSS no obliga a elegir entre CPU, GPU o NPU; más bien facilita que cada tarea corra donde más rinda por vatio. Arm ha optimizado la CPU para IA con SME2 y la GPU para cargas paralelas intensivas, dejando la NPU como acelerador externo opcional según el producto.
El resultado es un modelo heterogéneo donde las microtareas de IA (filtros on-the-fly, postprocesados, pequeñas inferencias) pueden resolverse en CPU sin costes de transferencia, mientras que redes más pesadas se redirigen a GPU o NPU cuando conviene.
Fabricación a 3 nm y diseños listos para producción
Lumex CSS llega con implementaciones físicas optimizadas para 3 nm y estrategia multifundición, acortando el “time-to-market” y permitiendo tanto diseños premium como variantes costo-eficientes con el mismo stack IP.
Además, Arm proporciona telemetría integrada en hardware y plataformas de referencia, lo que simplifica validación, control térmico y trazabilidad del rendimiento real en campo, algo clave para dispositivos móviles y portátiles ARM.
Beneficios prácticos: privacidad, latencia y coste
Al mover trabajo de IA de la nube al dispositivo, el usuario gana en tiempo de respuesta y seguridad: menos latencia y más privacidad, incluso sin conexión a internet, en funciones como traducción de voz en tiempo real, asistentes contextuales o fotografía computacional avanzada.
Para fabricantes y desarrolladores, el ahorro se nota en la factura de servicios y en la facilidad de despliegue: menos dependencia de servidores para determinadas funciones, y APIs/bibliotecas que habilitan SME2 y aceleración gráfica sin reescribir aplicaciones.
Experiencias y casos de uso que habilita Lumex
Con la CPU C1, GPU G1 y SME2, hay margen para nuevas experiencias en móvil y portátil para realidad virtual. Traducción de voz en tiempo real on-device, asistentes que entienden contexto y actúan proactivamente, edición de foto/vídeo con filtros inteligentes al vuelo o juegos con iluminación y reflejos más realistas son ejemplos directos.
En fotografía, la IA en el dispositivo aplica correcciones y mejoras creativas mientras disparas; en juegos, el ray tracing v2 y el pipeline gráfico nuevo elevan la fidelidad sin penalizar la batería; en productividad, la CPU con SME2 acelera resúmenes, transcripciones o clasificación semántica sin salir del equipo.
Ecosistema para desarrolladores: KleidiAI y frameworks
Arm ha integrado KleidiAI con los principales frameworks de IA (PyTorch ExecuTorch, Google LiteRT, Alibaba MNN, ONNX Runtime) para que SME2 se active de forma transparente en dispositivos Lumex. Así, los desarrolladores aprovechan la aceleración sin tocar el código de modelos.
También hay soporte de motores populares de creación de contenido interactivo: Unity y Unreal ya contemplan optimizaciones para la nueva GPU y para las rutas de IA, allanando el camino a títulos y apps que expriman G1 y C1 desde el primer día.
Rendimiento y eficiencia: cifras clave
En CPU, una configuración C1-Ultra puede entregar +25% en monohilo frente a su predecesor directo y escalar hasta +45% en cargas multinúcleo con el clúster C1 y el nuevo DSU, todo ello con mejoras de IPC y cachés más rápidas.
En C1-Pro, Arm habla de +11% por vatio y un 26% menos de energía al mismo rendimiento respecto a la generación anterior, además de +16% en gaming con idéntico consumo. C1-Nano, por su parte, recorta consumo un 26% y reduce tráfico L3–RAM un 21% de media (hasta 39% por carga).
En GPU, Mali G1-Ultra logra +20% de rendimiento general, +20% en inferencia IA, un 9% menos de energía por frame y hasta el doble de rendimiento en ray tracing, con mejoras palpables en juegos actuales.
Con SME2, tareas como ASR o generación de audio ven multiplicado su desempeño (4.7x y ~3x respectivamente en casos citados), manteniendo la flexibilidad de la CPU y evitando latencias de ida y vuelta a otros aceleradores cuando la carga lo permite.
Cómo se configura un SoC con C1-DSU y SME2
El C1-DSU permite mezclar núcleos para clústeres a medida: por ejemplo, 2× C1-Ultra + 6× C1-Pro con una o dos unidades SME2, o diseños más contenidos con C1-Pro y C1-Nano sin aceleradores externos. Todos los núcleos pueden acceder a los aceleradores SME2 si están presentes.
Esta flexibilidad facilita SoC orientados a IA local sin sacrificar eficiencia. La plataforma es escalable de verdad: puedes diseñar desde un wearable o un smartphone de gama media hasta un flagship o un portátil ARM con 14 núcleos, ajustando coste, área y consumo.
Mercado, adopción y competencia
Arm prevé un impacto enorme: más de 10.000 millones de TOPS desplegados en más de 3.000 millones de dispositivos en cinco años gracias a Lumex, y una adopción de SME/SME2 que podría superar los 30.000 millones de equipos para 2030.
Fabricantes de primer nivel ya han mostrado su interés: se esperan SoC comerciales basados en Lumex en la próxima hornada de smartphones premium y portátiles ARM, con casos confirmados en el ecosistema Android. Vivo ha avanzado planes para integrar un procesador basado en el subsistema Lumex en su próxima serie insignia.
La competencia, eso sí, aprieta: Apple en la gama alta de GPU, Qualcomm con Adreno 840 y Samsung con Xclipse 950 son rivales de altura, y rivales emergentes como CPU chinas también acechan el mercado. El enfoque de Arm para diferenciarse combina IA en CPU con SME2, un gran salto en ray tracing móvil y una ruta de fabricación de 3 nm lista para producción.
Por qué importa a usuarios y a la industria
Para el usuario final, Lumex se traduce en experiencias inmediatas y privadas: asistentes proactivos que entienden el contexto, traducciones fluidas sin red, edición multimedia con IA en tiempo real y juegos con efectos de iluminación avanzados sin martirizar la batería.
Para la industria, es un acortador de camino: CSS Lumex reduce la complejidad de diseñar, validar y fabricar SoC a 3 nm con alto rendimiento de IA, y ofrece un ecosistema de software listo para que las apps saquen partido desde el minuto uno.
Lumex CSS es la pieza que faltaba para hacer pervasiva la IA en el dispositivo: CPU C1 que aceleran IA con SME2 sin moverse de la caché, GPU G1 con RT v2 e inferencia más rápida, interconexión eficiente, 3 nm listo para producción y un entorno de desarrollo que reduce fricciones. La consecuencia práctica es clara: dispositivos más rápidos, más privados y con experiencias inteligentes que se sienten naturales, desde móviles asequibles hasta equipos de alto rendimiento.
