- NVLink aporta cientos de GB/s por GPU y latencias muy bajas, superando a PCIe en multi-GPU.
- NVSwitch escala la malla y habilita redes NVLink (DGX/SuperPOD) con decenas de TB/s agregados.
- NVLink 4.0 en H100 alcanza hasta 900 GB/s por GPU; A100 llega a 600 GB/s.
- Despliegue correcto: compatibilidad, puente, BIOS 4G, drivers, nvidia-smi y NCCL/NVSHMEM.

Si te interesa exprimir equipos con varias GPU o montar infraestructuras de IA, seguramente te suene NVLink. Esta interconexión de alta velocidad de NVIDIA nació para eliminar cuellos de botella entre procesadores gráficos y, en algunos casos, entre CPU y GPU, llevando el rendimiento multi-GPU muy por encima de lo que permite PCI Express.
Más allá del marketing, NVLink aporta pros tangibles: ancho de banda brutal, latencia ultrabaja, escalabilidad real con NVSwitch y opciones de memoria compartida que aceleran IA, HPC y análisis de datos. En las siguientes líneas desgranamos qué es, cómo funciona, cómo ha evolucionado, en qué hardware se integra (A100/H100, DGX y SuperPOD), qué diferencias tiene frente a PCIe/SLI, y cómo montarlo bien en tu servidor.
¿Qué es NVIDIA NVLink y por qué importa?
NVLink es una interconexión serie propietaria de alta velocidad creada por NVIDIA para comunicar GPU entre sí y, en determinadas plataformas, con CPU compatibles. Frente al esquema clásico en el que todo viaja por el bus PCIe, NVLink ofrece enlaces punto a punto con mucho más ancho de banda y menor latencia. El resultado: varias GPU pueden comportarse como un equipo cohesionado en cargas que exigen enormes transferencias de datos (deep learning, simulación científica, analítica avanzada), reduciendo tiempos de cómputo y mejorando la eficiencia.
En el segmento profesional, NVLink es la columna vertebral de sistemas como NVIDIA DGX, HGX y los clústeres SuperPOD; en el pasado también llegó al entorno GeForce para reemplazar SLI en configuraciones concretas. Desde su primera iteración, NVLink ha ido evolucionando en velocidad, eficiencia y funciones de memoria, hasta alcanzar con la generación 4.0 cifras de cientos de GB/s por GPU con topologías escalables gracias a NVSwitch.
NVLink frente a PCIe y SLI: ancho de banda, latencia y memoria
Comparado con PCI Express, NVLink proporciona enlaces dedicados que evitan el cuello de botella del bus general. PCIe 4.0 x16 ronda un máximo teórico de 64 GB/s, mientras que las implementaciones modernas de NVLink por GPU superan ampliamente esas cifras (por ejemplo, H100 alcanza hasta 900 GB/s bidireccionales por GPU con NVLink 4.0). La latencia también se reduce de forma notable, lo que se nota especialmente en sincronizaciones frecuentes entre múltiples GPU.
Frente a SLI (pensado para renderizado multi-GPU en juegos), NVLink introduce un enfoque más robusto y profesional para el intercambio de datos. En su paso por GeForce, NVLink ofreció ventajas como framebuffer compartido y posibilidad de sumar VRAM entre dos tarjetas en determinados escenarios, algo que SLI no aportaba de forma generalizada. Eso sí, el soporte en juegos fue limitado y NVIDIA trató NVLink como característica “premium” en Turing: por ejemplo, RTX 2070 prescindía del conector, mientras RTX 2080/2080 Ti sí lo incluían.
Para habilitarlo en esas tarjetas hacía falta un puente físico. El puente NVLink pasó de costar cientos de dólares en su etapa profesional a rondar los 80–90 € en la tienda de NVIDIA cuando llegó a GeForce, manteniéndose como solución orientada a usuarios avanzados y entornos que realmente aprovechasen su ancho de banda.
Evolución de NVLink: de 1.0 a 4.0
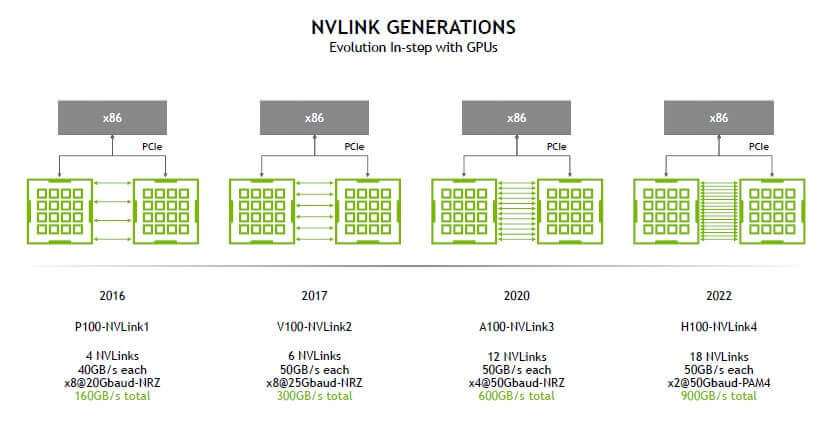
NVLink ha crecido a nivel de velocidad por enlace, número de sublinks y soporte de memoria a lo largo de cuatro generaciones. NVLink 1.0 debutó con Tesla P100 (2016), alcanzando en torno a 160 GB/s agregados por GPU (suma de ida y vuelta) mediante 4 sublinks, cada uno con 8+8 líneas a 20 GT/s. También se implementó en plataformas CPU como IBM POWER8+, facilitando CPU–GPU y GPU–GPU de alta velocidad.
Con NVLink 2.0 (Volta V100 y POWER9), los enlaces subieron a 25 GT/s y el número de sublinks por GPU aumentó (hasta 6 en V100), lo que se tradujo en 300 GB/s agregados (150 GB/s por dirección) por GPU. Además, se introdujo coherencia de caché en arquitecturas compatibles, reduciendo copias innecesarias y sobrecarga de CPU.
En NVLink 3.0 (Ampere A100) se consolidó la malla multi-GPU con NVSwitch de segunda generación y se mejoró la eficiencia de protocolo. Cada A100 puede alcanzar 600 GB/s agregados por GPU (300 GB/s por dirección) con 12 enlaces, reforzando la escalabilidad en nodos DGX A100 con 8 GPU y 6 chips NVSwitch.
La actual NVLink 4.0 (Hopper H100) da un salto físico relevante: adopta SerDes a 112G PAM4. Cada enlace NVLink 4.0 está formado por dos lanes de 112G, entregando cerca de 25 GB/s unidireccionales por enlace (50 GB/s bidireccionales). Con 18 enlaces por H100, el agregado alcanza hasta 900 GB/s bidireccionales por GPU, elevando drásticamente el techo de comunicación interna de la máquina; su evolución hacia NVLink 5 en Blackwell se puede leer en NVLink 5 en Blackwell.
Cómo funciona NVLink: enlaces, sublinks y coherencia
NVLink establece conexiones punto a punto serie que se agregan en grupos (enlaces/subenlaces) para suministrar un ancho de banda efectivo muy superior al PCIe tradicional. En las primeras generaciones, cada sublink combinaba 8+8 líneas (ida y vuelta) a 20/25 GT/s; en generaciones recientes el diseño se refina con line coding moderno (NRZ/PAM4) para aumentar la tasa por línea manteniendo fiabilidad y eficiencia energética.
El protocolo está pensado para la comunicación directa GPU a GPU y para integrarse con el ecosistema CUDA/NCCL. Soporta memoria compartida y modelos de coherencia que, junto con NVSHMEM u otras librerías, permiten que varias GPU vean direcciones de memoria de forma unificada, reduciendo copias y facilitando paralelismo a gran escala.
En topologías de varias GPU, NVLink puede organizarse en mallas o conectarse a través de NVSwitch, que actúa como fabric de muy alto ancho de banda. Todo ello contribuye a bajar la latencia de sincronización entre dispositivos y a sostener tasas de transferencia elevadas incluso cuando el número de GPU crece en el chasis.
NVSwitch: el tejido que escala NVLink
NVSwitch es el componente que permite llevar la comunicación de NVLink más allá de enlaces punto a punto. Un chip NVSwitch interconecta decenas de enlaces NVLink con una malla totalmente conectada, de gran ancho de banda y baja latencia, de modo que cualquier GPU pueda hablar con cualquier otra sin pasar por la CPU.
La tercera generación, NVSwitch3 (para H100), está fabricada en proceso TSMC 4N y alberga aproximadamente 25,1 mil millones de transistores en una matriz de ~294 mm². Incorpora 64 puertos NVLink 4.0, cada uno con dos lanes que entregan alrededor de 200 Gbps unidireccionales por puerto, sumando 12,8 Tbps por dirección (3,2 TB/s bidireccionales) por chip. Incluye motor SHARP (reducción y agregación jerárquica escalable) acelerado por hardware, con una ALU capaz de alrededor de 400 GFLOPS FP32 para operaciones de reducción in-switch, además de telemetría, particionado lógico de la red y FEC para robustez.
NVSwitch3 puede acoplarse a redes externas (400GbE o InfiniBand NDR) mediante PHY específicos, y se integra en sistemas DGX/HGX como backplane de GPU. Combinado con módulos ópticos OSFP NVLink y conmutadores externos NVLink, permite construir telas NVLink a escala de rack y de clúster.
Integración en NVIDIA A100 y H100
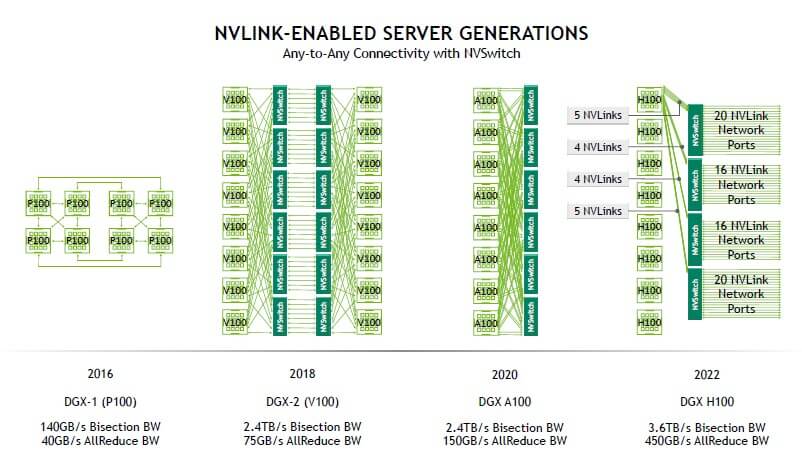
En NVIDIA A100 (Ampere), cada GPU dispone de 12 enlaces NVLink 3.0 que suman hasta 600 GB/s agregados, clave para entrenamientos de IA y simulaciones con 8 GPU a través de NVSwitch2. Esta generación popularizó configuraciones DGX A100 con 6 chips NVSwitch internos para una conectividad all-to-all eficiente.
Con NVIDIA H100 (Hopper), NVLink 4.0 eleva aún más el listón: 18 enlaces por GPU y hasta 900 GB/s bidireccionales. Además, Hopper ofrece MIG más flexible (instancias de GPU) y se apoya en NVSwitch3 para sostener el tráfico inter-GPU a alta velocidad. A nivel de red externa, el conmutador NVLink en formato 1U integra dos NVSwitch3 para exponer hasta 32 puertos OSFP; con 128 interfaces NVLink 4.0 lógicas puede superar decenas de Tbps agregados, sirviendo de troncal para interconectar múltiples servidores GPU con enlaces ópticos de alta capacidad.
Estas mejoras se combinan con coherencia de caché, ECC y mecanismos de tolerancia a fallos, esenciales en entornos críticos (IA, investigación científica, finanzas, sanidad) donde integridad y disponibilidad son tan importantes como el rendimiento.
Red NVLink (fabric) y DGX H100 SuperPOD
Con los conmutadores NVLink externos, es posible construir una red NVLink dedicada para GPU, independiente de IP/Ethernet, diseñada para ofrecer el máximo ancho de banda y mínima latencia entre aceleradores. Cada servidor mantiene su espacio de direcciones y la red gestiona la conectividad, aislamiento y seguridad entre GPU de distintos nodos, estableciendo rutas automáticamente a través de las API de NVIDIA.
En un DGX H100 SuperPOD típico (32 servidores, 256 GPU H100), la red NVLink alcanza aproximadamente 57,6 TB/s de ancho de banda bidireccional entre las 256 GPU. Internamente, cada DGX H100 integra 8 GPU, 4 NVSwitch3 y 18 enlaces NVLink 4.0 por GPU organizados en grupos (5/4/4/5) hacia los conmutadores internos; el diseño prioriza el tráfico local y administra una convergencia 2:1 hacia los conmutadores externos para equilibrar complejidad y coste.
Para la salida a red del servidor, los DGX H100 montan 8 puertos ConnectX-7 y dos DPU BlueField-3 para funciones de red/seguridad/almacenamiento, con soporte PCIe Gen5. Esto permite enlazar NVLink Fabric con redes Ethernet/InfiniBand, escalar a varios POD y orquestar trabajos masivos de IA con topologías tipo árbol grueso cuando se usa InfiniBand.
En pruebas de referencia de bisección all-to-all, la capacidad de NVLink 4.0/NVSwitch3 multiplica el ancho de banda efectivo frente a configuraciones previas basadas en IB, y NCCL muestra anchos de banda estables tanto dentro del servidor como entre nodos cuando se optimiza la ruta NVLink.
Casos de uso y beneficios prácticos
IA y aprendizaje automático: NVLink acelera el entrenamiento distribuido al permitir sincronizaciones y all-reduce más rápidas entre GPU, reduciendo el tiempo por época y mejorando la escalabilidad. En sistemas DGX/HGX con NVSwitch, las GPU comparten datos con latencias sub-microsegundo, clave para modelos con millones de parámetros y lotes grandes.
HPC y simulación científica: en física, genómica o clima, el cuello de botella suele ser mover datos entre GPU. NVLink y NVSwitch elevan el ancho de banda inter-GPU (por ejemplo, 300 GB/s por dirección en A100; hasta 900 GB/s agregados en H100), mejorando la eficiencia en problemas con gran comunicación intra-nodo.
Analítica de datos y bases de datos aceleradas: el acceso a memoria compartida y la coherencia reducen copias y pasos intermedios, acelerando consultas y transformaciones en bases de datos GPU-resident y motores de análisis en tiempo real.
Ejemplos reales: instituciones como el NCAR han impulsado la velocidad y precisión de sus modelos de predicción meteorológica; en genómica, empresas como WuXi NextCODE han recortado tiempos de análisis con pipelines acelerados por NVLink; y laboratorios de IA como OpenAI han adoptado infraestructuras multi-GPU para entrenar redes de gran escala con comunicaciones GPU–GPU optimizadas.
Guía rápida: desplegar NVLink en tu servidor
Antes de empezar, confirma requisitos. Verifica compatibilidad de tu chasis, placa base, CPUs y, sobre todo, de tus GPU con NVLink/NVSwitch según las matrices de NVIDIA y del fabricante del servidor.
- Puentes NVLink: en configuraciones de dos GPU compatibles (p. ej., algunas generaciones profesionales o Turing de gama alta), instala el puente físico correcto y encájalo firmemente. Asegúrate de elegir el modelo que casa con el espaciado y la serie de GPU.
- BIOS/UEFI: activa opciones como Above 4G Decoding y ajusta recursos de PCIe si procede. En servidores modernos orientados a GPU suele venir preconfigurado, pero conviene revisarlo.
- Controladores: instala los últimos drivers NVIDIA y, en su caso, CUDA/NCCL actualizados. Sin los controladores adecuados NVLink no se habilita ni se aprovecha su ruta preferente.
- Verificación: en Linux, usa nvidia-smi nvlink -s para consultar estado, topología y velocidades de enlace. Comprueba que todos los enlaces aparecen activos y sin errores de corrección (ECC/FEC).
- Software: ajusta frameworks (PyTorch, TensorFlow) para usar NCCL y las rutas de alta velocidad. En aplicaciones propias, apóyate en NCCL/NVSHMEM y diseña los algoritmos para minimizar sincronizaciones y maximizar transferencia por NVLink.
NVLink 4.0, NVLink-C2C y NVLink Fusion: lo último
La cuarta generación de NVLink aporta más ancho de banda por enlace, más enlaces por GPU y mejor integridad de señal. En entornos DGX H100, esto se traduce en menos congestión, más escalabilidad y mayor eficiencia energética por GB transferido frente a generaciones previas.
En el plano de empaquetado, NVLink-C2C (chip a chip) promete hasta 25 veces mejor eficiencia energética y hasta 90 veces mejor eficiencia de área frente a un PHY PCIe Gen5 en chips NVIDIA, escalando desde PCB hasta MCM o interposer/wafer-level. Es la vía para unir CPU y GPU de forma estrecha (como con Grace o con procesadores Rubin CPX) y para diseños semipersonalizados de socios.
NVIDIA también ha anunciado NVLink Fusion, un programa que abre la puerta a que procesadores de terceros (CPUs y ASICs) se integren en el ecosistema NVLink, ampliando el alcance de la tecnología en centros de datos y permitiendo arquitecturas de IA más heterogéneas.
NVLink vs tecnologías tradicionales: datos clave
Frente a PCIe, NVLink ofrece ancho de banda agregado muy superior, menor latencia y una arquitectura que escala con NVSwitch. PCIe sigue siendo universal y suficiente para muchos casos, pero cuando los modelos y conjuntos de datos crecen, la diferencia entre 64 GB/s (PCIe 4.0 x16) y cientos de GB/s por GPU con NVLink marca el rendimiento final del sistema.
Además, NVLink y NVSwitch incorporan corrección de errores, telemetría, y opciones de seguridad (p. ej., particionado de la red NVLink) acordes con las exigencias de entornos HPC/IA empresariales, donde confiabilidad y disponibilidad son críticas.
