- NVFP4 combina E2M1 con escalado dual (FP8 por microbloques y FP32 por tensor) para reducir un 88% el error de cuantización.
- En Blackwell, FP4 logra hasta 20 PFLOPS por GPU y 3× más rendimiento que FP8 en casos reales, con caídas mínimas de precisión.
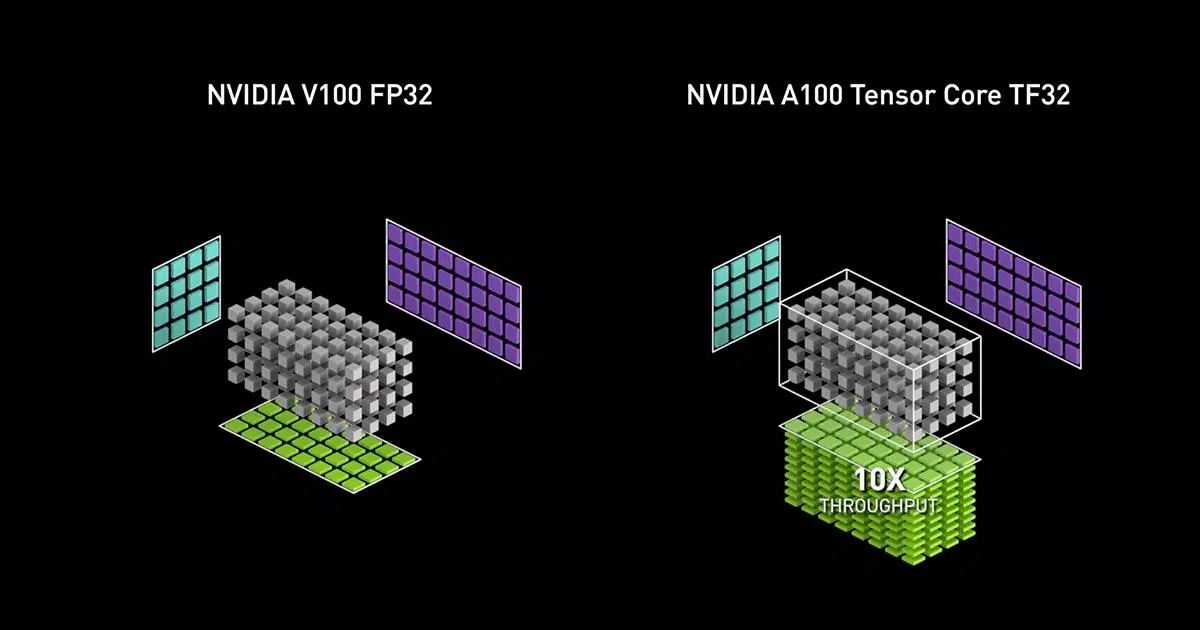
- La memoria se desploma (hasta 8×), la energía por token cae hasta 50× y los costes de inferencia bajan cerca del 90%.
- El ecosistema ya soporta FP4 (TensorRT, vLLM, HF) y la infraestructura avanza con NVLink 5, refrigeración líquida y racks de 120 kW.
La conversación en torno a los formatos de precisión en IA se ha acelerado con la llegada de NVFP4, y no es para menos: reducir bits sin perder calidad cambia radicalmente la economía de la inferencia. En esta guía vas a encontrar qué es NVFP4, en qué se diferencia de FP8 y BF16, y por qué los grandes (y no tan grandes) ya lo están adoptando, desde data centers a PCs de sobremesa.
Más allá del bombo del marketing, hay datos sólidos: energía por token recortada hasta 50 veces, caudales de tokens por segundo que baten récords, y memoria que se desploma a una fracción sin aniquilar la precisión. Aun así, conviene separar titulares de realidad práctica, porque el impacto depende del hardware, del escalado numérico y de cómo se cuantiza y optimiza cada modelo.
Qué es NVFP4 y en qué mejora a FP8 y BF16
NVFP4 es la propuesta de NVIDIA para una precisión ultrabaja pensada para la inferencia de IA. Representa números con E2M1 (1 bit de signo, 2 de exponente y 1 de mantisa) y añade un ingrediente clave: escalado en dos niveles que reduce drásticamente el error de cuantización frente a aproximaciones más simples.
Ese esquema a dos niveles combina un factor de escala FP8 E4M3 aplicado a microbloques de 16 valores con un escalado global por tensor en FP32. Gracias a esa combinación, se logra un 88% menos de error que soluciones de potencia de dos más básicas como MXFP4, reforzando la estabilidad numérica con tan pocos bits.
En contraste, FP8 (E4M3 o E5M2) ya recorta bastante coste frente a FP16/BF16, pero NVFP4 va un paso más allá disminuyendo aún más memoria y energía. BF16 mantiene un rango dinámico parecido a FP32 con menos bits en la mantisa, ideal para entrenamiento y entornos donde la estabilidad de gradientes manda, pero para la inferencia masiva el 4-bit bien escalado está marcando diferencias.
La consecuencia práctica: en cargas de trabajo bien adaptadas, NVFP4 mantiene una precisión muy cercana a formatos superiores, pero con saltos de velocidad y eficiencia memorables. Todo depende de cuantización, calibración y del soporte nativo del hardware.

Arquitectura Blackwell: el músculo detrás de NVFP4
La llegada de Blackwell ha sido el catalizador para que NVFP4 despegue. La GPU B200 integra 208.000 millones de transistores en un diseño de doble chip, unidos a través de una interfaz NV-HBI de 10 TB/s que se presenta transparente al software, garantizando un comportamiento unificado.
Los Tensor Cores de quinta generación soportan NVFP4 de forma nativa con escalado acelerado por hardware, alcanzando hasta 20 PetaFLOPS en FP4. La arquitectura incorpora además memoria tensorial próxima a las unidades de cómputo (TMEM), limitando el coste energético del movimiento de datos y elevando el rendimiento sostenido.
Para consumo, la serie GeForce RTX 50 hereda funciones FP4 con cifras de hasta 4.000 TOPS de IA y acelera la generación de imágenes (por ejemplo, FLUX) hasta 3,9 veces frente a FP8 en escenarios específicos, demostrando que la inferencia a 4 bits no es solo cosa de centros de datos.
En el extremo de mayor escala, Blackwell Ultra (B300/GB300) eleva el listón con 288 GB de HBM3E y 1,5× más rendimiento que B200, llegando en configuraciones NVL72 a rozar 1,1 exaFLOPS por sistema en FP4 denso. Esto sienta la base para servir modelos de cientos de miles de millones de parámetros con menos máquinas.
Métricas: más tokens, menos vatios y memoria bajo control
Los datos de producción y benchmarks pintan un cuadro consistente. En DeepSeek-R1 671B, el salto a FP4 en B200 triplica el rendimiento respecto a FP8 en H200, con sistemas DGX B200 que superan los 30.000 tokens/s. La precisión apenas se resiente: MMLU baja del 90,8% al 90,7% al cuantizar de FP8 a FP4.
En memoria, los números son demoledores. Un LLM como Llama 3.1 405B pasa de 140 GB en FP32 a 17,5 GB en FP4, una reducción de 8× que permite servir modelos masivos en menos GPU. En generación de imágenes, una configuración FLUX puede caer de 51,4 GB en FP16 a 9,9 GB en FP4 con mínima merma visual y adaptándose a VRAM modesta.
MLPerf v5.0 respalda el movimiento: el throughput medio de Llama 2 70B se dobló respecto al año anterior y los mejores resultados mejoraron 3,3×. En energía, el token
de H100 a 10 J desciende a 0,4 J en B200 y a 0,2 J en B300, es decir, hasta 50× más eficiencia. Traducido a negocio, hay desplomes cercanos al 90% en costes de inferencia a lo largo de 2024-2025.
En el extremo de usuario, los modelos de imagen y texto con NVFP4 aprovechan más tokens por dólar, con informes de hasta un 40% de mejora respecto a alternativas, algo que combina bien con la menor huella de memoria y la facilidad de servir modelos de gran tamaño.
Adopción: clouds, empresas y casos reales
Los proveedores de nube lideran la adopción de FP4. Lambda Labs ofrece clusters HGX B200 con FP4 en despliegues 1-Click, y CoreWeave registra 800 tokens/s en Llama 3.1 405B con GPU GB200. No todo es NVIDIA: Meta, OpenAI y Microsoft usan AMD Instinct MI300X en inferencia y MI350 llegará con soporte FP4 nativo.
En banca, JPMorgan evalúa FP4 para riesgo y análisis alternativos; en sanidad se han visto +30% de velocidad con -50% de memoria, y en manufactura se habilitan decisiones en tiempo real en dispositivos con recursos limitados, abriendo puertas donde antes no había margen.
El software acompaña el paso. TensorRT Model Optimizer aporta flujos de cuantización FP4 completos; marcos como vLLM integran soporte temprano para NVFP4; y Hugging Face alberga checkpoints FP4 precuantizados (DeepSeek-R1, Llama 3.1, FLUX) para acelerar puestas en producción.
Para equipos con menos cómputo, hay vías sin QAT usando SVDQuant con precisión cercana a entrenamiento cuantizado; si se busca exactitud máxima, el QAT en FP4 conserva o incluso mejora frente a BF16 en familias como Nemotron 4, siempre que se afine bien el proceso.
Infraestructura: potencia, refrigeración y nuevas normas del CPD
La precisión ultrabaja exige redibujar el centro de datos. Un sistema GB200 NVL72 consume 120 kW por rack para 72 GPU, por encima de la capacidad de la mayoría de CPD existentes. Aun así, un NVL72 sustituye nueve HGX H100 y requiere un 83% menos de energía para el mismo cálculo efectivo.
Con TDP de ~1.000 W por GPU, la refrigeración líquida directa al chip no es opcional. Placas frías en todos los puntos calientes permiten usar refrigerante a 45 ºC y torres de refrigeración, evitando chillers costosos. Soluciones como Supermicro DLC-2 llegan a 96 B200 por rack y hasta 250 kW de capacidad térmica.
En software de base, hacen falta controladores CUDA actualizados, TensorRT-LLM con soporte FP4 y herramientas especializadas de cuantización. La postcuantización con Model Optimizer acelera la salida a producción, mientras que el entrenamiento con cuantización maximiza la retención de calidad.
Mirando a medio plazo, proliferarán CPD preparados para racks de 50-120 kW, con soluciones de refrigeración y gestión energética de nueva generación. La madurez del software seguirá mejorando con integraciones fluidas y pipelines de cuantización automatizados.
Redes y escalabilidad: NVLink 5, switches y fotónica
El tejido de interconexión es la otra mitad del rendimiento. La 5ª generación de NVLink dobla el ancho de banda y permite unir hasta 576 GPU. Cada enlace efectivo ofrece ~50 GB/s por dirección; con 18 enlaces por GPU, el ancho de banda agregado alcanza ~1,8 TB/s, más de 14× que PCIe Gen5.
El conmutador NVIDIA NVLink aporta hasta 130 TB/s por dominio NVL72, fundamental para paralelismo a escala de modelo. Además, el soporte del protocolo SHARP para reducciones jerárquicas acelera precisiones como FP8 en operaciones colectivas críticas.
NVIDIA está empujando también en redes con Quantum-X800 InfiniBand y Spectrum-X800 Ethernet, con familias de switches que van desde 128 a 512 puertos de 800G, además de opciones de 200G con alta densidad, y refrigeración líquida integrada para sostener el rendimiento.
Con NVIDIA Photonics, los motores ópticos integrados en el paquete del ASIC del switch reemplazan transceptores conectables tradicionales, promoviendo hasta 3,5× de eficiencia, 10× más resiliencia y despliegues 1,3× más rápidos, allanando el camino a centros de datos ópticos de alta densidad.
Ecosistema de software y plataformas: Dynamo, AI‑Q, Mission Control, NIM y OVX
Para exprimir Blackwell, NVIDIA ha presentado varias piezas clave. Dynamo es una plataforma de inferencia de código abierto pensada para escalar una sola consulta entre GPU a través de NVLink, con mejoras de hasta 30× en cargas con razonamiento intenso como DeepSeek R1 y doblando throughput en Hopper sin cambiar hardware.
AI‑Q (más AgentIQ) propone un marco multiagente abierto que integra datos empresariales, herramientas externas y otros agentes, facilitando sistemas compuestos capaces de razonar sobre texto, imagen y vídeo, con integraciones en frameworks como CrewAI, LangGraph o Azure AI Agent Service.
En la capa operativa, Mission Control automatiza la orquestación end‑to‑end de centros‑de‑datos de IA, con conmutación fluida entre entrenamiento e inferencia, 5× más utilización y recuperación de trabajos 10× más rápida. Además, Base Command Manager pasa a estar disponible sin coste para hasta ocho aceleradores por sistema.
La pila NVIDIA NIM suma microservicios de IA generativa listos para empresa. Por su parte, los sistemas OVX están orientados a IA generativa y gráficos intensivos, acompañados de un programa de validación de almacenamiento con DDN, Dell PowerScale, NetApp, Pure Storage o WEKA para garantizar throughput y escalado en producción.
Productos para profesionales: RTX Pro Blackwell, DGX Station y DGX Spark
La nueva familia RTX Pro Blackwell actualiza la línea profesional con hasta 96 GB de memoria en la Pro 6000 y hasta 4.000 TOPS de IA, núcleos RT de 4ª gen y Tensor de 5ª gen con FP4. En Server Edition, añade vGPU y MIG para partir una GPU en varias instancias aisladas.
En casos reales, se han reportado 5× en trazado de rayos frente a RTX A6000 (Foster + Partners), hasta 2× en reconstrucción médica (GE HealthCare), mejoras notables en RV (Rivian) y productividad 3× con LLM (SoftServe). Pixar destaca que un 3,3% de sus tomas de producción ya caben en 70 GB de una sola GPU.
DGX Station se actualiza con GB300 Grace Blackwell Ultra, 784 GB de memoria unificada y hasta 20 PFLOPS en IA FP4, más conectividad de 800 Gb/s con ConnectX-8. Para desarrolladores y estudiantes, DGX Spark con chip GB10 y 128 GB de memoria unificada ofrece ~1.000 TOPS de IA y SmartNIC ConnectX‑7, abaratando la entrada al ecosistema.
Exaescala en un rack y superpods a medida
El sistema DGX GB200 NVL72 duplica de 32 a 72 GPU y eleva la memoria desde ~19,5 TB a ~30 TB. En cómputo, el salto es espectacular: de 127 PF a 1,4 EF en FP4 (~11×), y de 127 PF a 720 PF en FP8 (~5,6×), todo en un chasis completamente refrigerado por agua.
Más arriba, el DGX SuperPOD con 8 sistemas GB200 NVL72 suma 11,5 exaFLOPS FP4 y 36 SuperChips GB200 por sistema, con mejoras de hasta 30× frente a H100 en inferencia de LLM grandes, diseñado como “fábrica de IA” preparada para modelos del orden del billón de parámetros.
En plataforma Grace‑Blackwell, el GB200 enlaza dos B200 con una CPU Grace compartida vía C2C, y escala hasta 576 GPU a 1,8 TB/s mediante NVLink 5, ensamblando entornos masivamente paralelos adecuados para las cargas de IA más exigentes.
Cuantización moderna: conservar la inteligencia a 4 bits
El éxito de FP4 viene de combinar hardware y software. El escalado dual de NVIDIA se ajusta a la distribución de valores por tensor y el motor Transformer analiza más de 1.000 operaciones para optimizar escalas dinámicamente, permitiendo que modelos como DeepSeek‑R1 alcancen 98,1% de precisión en FP4 y, en algunos tests, superen la línea base FP8.
En postentrenamiento, SmoothQuant y AWQ han hecho posible meter modelos del tamaño de Falcon 180B en una sola GPU. Si necesitas preservar al máximo, el QAT emulando FP4 durante fine‑tuning ayuda a adaptar distribuciones de pesos. Familias como Nemotron 4 muestran FP4 sin pérdidas mediante QAT, a la altura o por encima de BF16.
Para casos complicados, la gestión de valores atípicos evita colapsos de activación, y las estrategias de precisión mixta elevan bits en operaciones críticas. El resultado: FP4 es viable en arquitecturas densas y también en Mixture of Experts, con una precisión que no sacrifica producción.
Hoja de ruta y disponibilidad
Mirando adelante, la generación Vera Rubin apunta a 50 PFLOPS FP4 densos por GPU, con ConnectX‑9, NVLink‑6 y memoria HBM4 (+1,6× de ancho de banda). La interconexión CPU‑GPU también subirá hasta ~1,8 TB/s, y Rubin Ultra doblará de nuevo el listón hasta 100 PFLOPS FP4 y 1 TB de HBM4e.
En el lado de AMD, la arquitectura CDNA 4 impulsa Matrix Cores con soporte para FP4 y FP6, doblando rendimiento frente a la generación anterior y añadiendo sparsity para acelerar aún más, algo especialmente interesante en modelos Mixture of Experts.
La limitación más inmediata no es técnica sino de suministro de hardware: gran parte de la producción B200/B300 de 2025 está comprometida con hyperscalers. Aun así, el impacto en coste por token y eficiencia energética está provocando una democratización real, acercando capacidades de vanguardia a organizaciones pequeñas gracias a los saltos en memoria y cómputo por vatio.
