- Ollama permite descargar y ejecutar modelos de IA en local en Windows, sin depender de la nube y con mayor privacidad.
- La herramienta se controla desde la terminal, donde puedes instalar, lanzar y gestionar modelos como Llama, DeepSeek, Gemma o Mistral.
- El rendimiento depende sobre todo de la RAM disponible y del tamaño del modelo, con recomendaciones de 8, 16 y 32 GB para 7B, 13B y 33B.
- Combinado con OpenWebUI, Ollama ofrece una experiencia de chat gráfica y avanzada para trabajar con modelos locales de forma cómoda.
La inteligencia artificial local está en plena ebullición y, si te apetece trastear con modelos tipo ChatGPT sin depender de la nube, Ollama se ha convertido en una de las opciones más interesantes para Windows. No necesitas crearte una cuenta, no tienes que pagar suscripciones y, además, todo lo que hagas se queda en tu PC, lejos de servidores externos.
En esta guía vas a aprender paso a paso cómo instalar Ollama en Windows, cómo poner en marcha tus primeros modelos (como Llama 3.2, DeepSeek o Gemma) y qué requisitos de hardware necesitas para que todo funcione fluido. También veremos algunos trucos básicos para manejarte con la línea de comandos y cómo complementar Ollama con una interfaz gráfica como OpenWebUI si no te apetece usar solo la terminal.
Qué es Ollama y por qué merece la pena usarlo en Windows
Ollama es una aplicación ligera y de código abierto que actúa como “motor” o backend para ejecutar modelos de lenguaje (LLM) directamente en tu ordenador. Está disponible para Windows, macOS y Linux, y su función es gestionar la descarga, ejecución y uso de modelos como Llama, Mistral, Phi, Qwen, Gemma, DeepSeek y muchos otros, todo de forma local.
En lugar de ir a la web de una empresa para chatear con su IA, con Ollama el modelo se instala en tu equipo y lo usas desde ahí. Eso implica que tus prompts, textos y datos no salen de tu máquina, lo que supone una mejora muy importante en privacidad y control frente a los servicios en la nube tradicionales.
Otra particularidad clave de Ollama es que funciona mediante la terminal. Es decir, no tiene una ventana gráfica propia en Windows: lo manejas desde PowerShell o el Símbolo del sistema. Tú escribes un comando para arrancar el modelo, esperas a que se descargue (la primera vez) y, a partir de ahí, te responde dentro de la propia consola, como si fuera un chat minimalista.
Usar modelos en local te da varias ventajas interesantes: por un lado, tus datos no se envían a terceros; por otro, puedes utilizar la IA aunque se caiga tu conexión a Internet; y, además, en muchos casos las respuestas son muy rápidas al no depender de llamadas a una API externa. Eso sí, a cambio necesitas un PC con cierta potencia y buena cantidad de RAM, sobre todo si quieres jugar con modelos grandes.
Instalar Ollama en Windows paso a paso
El proceso de instalación de Ollama en Windows es muy sencillo y no se diferencia demasiado de cualquier otro programa que tengas en tu equipo. No necesitas usar Git ni compilar nada raro: basta con descargar el instalador oficial y seguir el asistente.
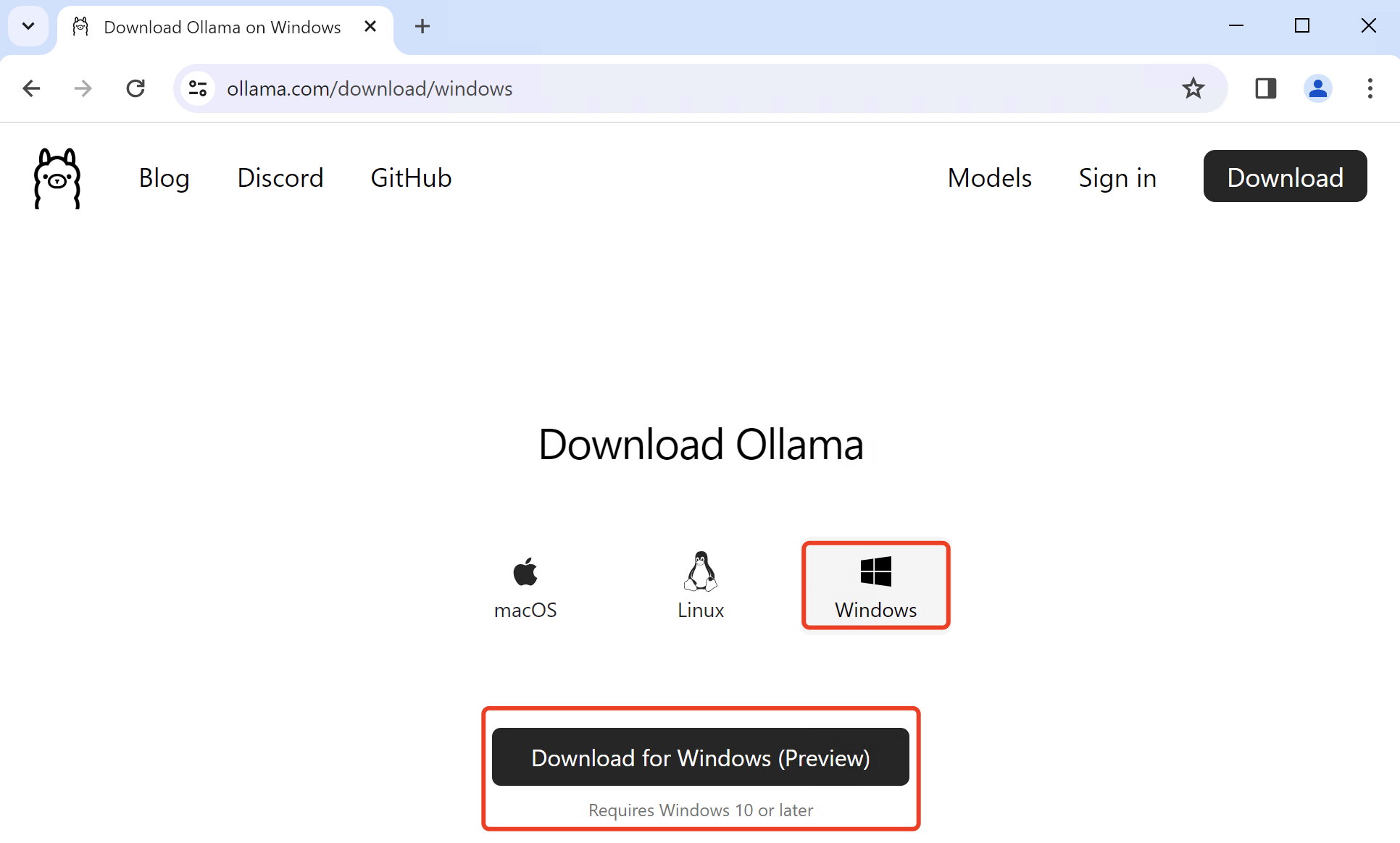
Lo primero es ir a la web oficial de Ollama, disponible en la dirección ollama.com. Una vez dentro verás un botón destacado con el texto Download. Haz clic ahí para ir a la página de descargas, donde se listan las versiones para los distintos sistemas operativos.
En esa página se te mostrará por defecto el sistema operativo que estás usando (en este caso, Windows), pero también puedes elegir manualmente macOS o Linux si los necesitas para otro equipo. Asegúrate de que seleccionas Windows y pulsa de nuevo en Download para iniciar la descarga del ejecutable.
Cuando el archivo .exe haya terminado de descargarse, haz doble clic sobre él para lanzar el instalador. El asistente es muy básico: verás una pantalla de bienvenida, después la ruta de instalación y, en la mayoría de casos, bastará con pulsar en Next o directamente en Install para que empiece a copiar los archivos.
Una vez finalice la instalación, Ollama quedará configurado como servicio en tu sistema y podrás invocarlo desde la terminal sin tener que tocar nada más. No esperes que se abra una ventana con interfaz gráfica, porque no funciona así: el siguiente paso será abrir PowerShell o el Símbolo del sistema para empezar a usarlo.
Primeros pasos: usar Ollama desde la línea de comandos
Aquí viene el pequeño “truco” de Ollama: todo se maneja desde la consola. Si nunca has usado mucho PowerShell o el Símbolo del sistema, no te preocupes, con un par de comandos básicos lo tendrás bajo control.
Abre PowerShell o el CMD en Windows. Puedes hacerlo buscando “PowerShell” o “Símbolo del sistema” en el menú de inicio. Cualquiera de los dos sirve: Ollama responde igual desde ambas terminales, así que usa la que te resulte más cómoda.
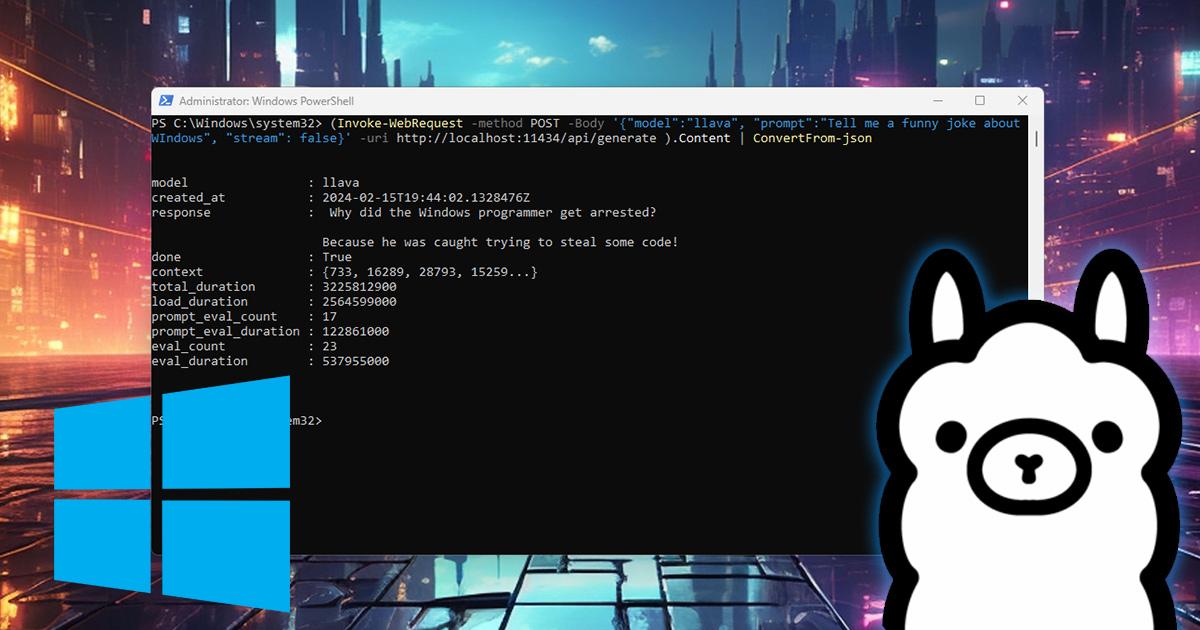
El siguiente paso es arrancar por primera vez un modelo. Un buen candidato para empezar es Llama 3.2 en una variante ligera, que tiene un tamaño manejable y te permite hacer pruebas sin saturar el PC. En la terminal, escribe un comando similar a este (ejemplo genérico):
ollama run llama3.2
La primera vez que ejecutes este comando, Ollama descargará el modelo desde sus servidores. Verás en pantalla un progreso de descarga y el tamaño aproximado del archivo; en el caso de ciertas variantes ligeras, puede rondar los 2 GB, mientras que versiones más grandes o de otros modelos pueden irse bastante más arriba.
Cuando termine la descarga, la terminal cambiará a un modo de chat. Normalmente verás un indicador como >>> que te avisa de que lo que escribas a partir de ese momento se le envía directamente al modelo de IA. Escribe una petición sencilla (por ejemplo, que salude, que te explique algo corto o que escriba una pequeña historia) y pulsa Intro para que empiece a generar la respuesta.
Durante toda la sesión, el modelo mantendrá el contexto de la conversación, de modo que podrás hacer preguntas de seguimiento sin repetirlo todo. Si le preguntas “¿Cómo es el verano en Barcelona?” y después escribes “¿Y en París?”, sabrá que sigues hablando del clima y comparará ambas ciudades, igual que harías con un chat en la web de ChatGPT.

Comandos útiles y gestión de modelos en Ollama
Ollama incluye varios comandos para ayudarte a administrar modelos y sesiones sin tener que pelearte con rutas de archivos o configuraciones avanzadas. Algunos se ejecutan dentro del propio chat del modelo y otros se lanzan directamente desde la terminal.
Dentro de una conversación interactiva con el modelo, puedes escribir /? para ver la lista de comandos disponibles. Se mostrarán atajos para gestionar el contexto, salir de la sesión o consultar información del modelo cargado en ese momento.
Por ejemplo, el comando /bye te permite cerrar la sesión actual y salir del modo de chat, volviendo al aviso normal de la terminal. Si quieres borrar el historial de la conversación y empezar desde cero sin abandonar el modelo, puedes usar /clear, que vacía el contexto que el modelo tiene en memoria.
Si quieres ver detalles técnicos del modelo que estás usando (como el nombre de la variante, tamaño aproximado o parámetros relevantes), el comando /show te mostrará esa información de forma resumida. Es una buena forma de confirmar qué estás ejecutando si tienes varias versiones descargadas.
Para gestionar modelos desde fuera de la sesión interactiva, Ollama dispone de comandos globales. Uno de los más útiles es ollama rm nombre_modelo, que sirve para eliminar un modelo que ya no necesites y así liberar espacio en disco. Simplemente sustituyes nombre_modelo por el identificador exacto (por ejemplo, llama3.2 o deepseek-r1:8b).
Además de Llama 3.2, en Ollama tienes disponibles muchos otros modelos: desde variantes especializadas en código hasta modelos de propósito general como DeepSeek, Mistral, Qwen, Phi, Gemma o Llava, entre otros. Todos ellos aparecen listados en la librería oficial de Ollama, donde también se indican sus tamaños, capacidades y versiones.
Instalar y lanzar modelos como DeepSeek, Gemma o Llama con Ollama
La instalación de modelos concretos en Ollama sigue siempre la misma filosofía: eliges el modelo que te interesa, copias el comando que te propone la web y lo pegas en tu terminal. La primera ejecución descarga el modelo; las siguientes, simplemente lo cargan en memoria.
Para ver el catálogo de modelos compatible con Ollama, visita la página oficial de búsqueda en ollama.com/search. Ahí verás una lista con modelos populares como DeepSeek, Llama, Phi, Mistral, Qwen, Llava, Gemma y otros. Cada entrada tiene su propia ficha con descripción, tamaños y versiones disponibles.
Cuando entras en la ficha de un modelo, puedes elegir la variante que se adapte mejor a tu hardware. Suelen aparecer versiones diferenciadas por el número de parámetros (por ejemplo, 8B, 14B, 27B, 70B, etc.). Cuantos más parámetros, más memoria y potencia de cálculo necesitarás, pero a cambio obtendrás respuestas más ricas y matizadas.
En la parte superior derecha de la ficha verás el comando exacto para lanzarlo con Ollama. Por ejemplo, para la versión de 8.000 millones de parámetros de DeepSeek R1, el comando típico sería algo como ollama run deepseek-r1:8b. Copia ese texto y pégalo en tu terminal de Windows, siempre después de haberte asegurado de que el servicio de Ollama está instalado y funcionando.
La primera vez que ejecutes ese comando, Ollama descargará el modelo y lo dejará listo. A partir de ahí, cada vez que vuelvas a lanzar el mismo comando ya no tendrá que bajarlo de nuevo, simplemente lo cargará y te meterá directamente en el modo de chat (aparecerá el famoso >>> para que escribas tus prompts).
Qué es exactamente un modelo y cómo elegir el más adecuado
Un modelo de lenguaje (LLM) es, en la práctica, el “cerebro” de la IA que estás usando. Se trata de una red neuronal gigantesca entrenada con enormes cantidades de texto para aprender a generar respuestas coherentes, escribir código, resumir documentos, traducir, razonar, etc.
Los modelos se diferencian, entre otras cosas, por su tamaño en parámetros. Los más pequeños (en torno a 1.000 millones de parámetros) son más fáciles de mover en PCs modestos, consumen menos memoria y suelen ser bastante rápidos, aunque a veces se notan algo más limitados en comprensión y calidad de respuesta.
En el otro extremo están los modelos grandes, con decenas de miles de millones de parámetros (por ejemplo, 27B, 33B o incluso 70B). Estos suelen ofrecer resultados mucho más sólidos, mejor razonamiento y textos más naturales, pero exigen mucha más RAM y un procesador o una GPU capaces de aguantar el tirón.
Llama 3.2 es un buen ejemplo de modelo equilibrado para empezar. Las variantes ligeras funcionan bien en muchos equipos relativamente recientes y ocupan unos pocos gigas, lo que las hace idóneas para experimentar sin volverse loco con los requisitos. Aun así, tienes a tu alcance otros modelos más potentes como Gemma2:27B, DeepSeek R1 en distintas versiones y modelos especialistas en programación o análisis.
La clave está en probar distintos tamaños y familias de modelos hasta encontrar el punto justo entre rendimiento y calidad para tu caso de uso y tu hardware. Si tu PC tiene 8 GB de RAM, será mejor optar por modelos pequeños; si dispones de 32 GB, podrás atreverte con variantes bastante más pesadas.
Rendimiento y requisitos de hardware para usar Ollama en Windows
Ollama en sí mismo no impone unos requisitos mínimos estrictos, porque actúa solo como intermediario entre tu equipo y los modelos. Sin embargo, cada modelo sí que tiene sus propias necesidades de memoria y potencia de cálculo para funcionar con cierta soltura.
Los desarrolladores de Ollama proporcionan unas recomendaciones orientativas muy útiles: disponer de al menos 8 GB de RAM libres para modelos de 7B parámetros, 16 GB para modelos de 13B y en torno a 32 GB para modelos de 33B. Por encima de esos tamaños, lo habitual es necesitar equipos de gama alta o estaciones de trabajo.
En pruebas reales con modelos como Llama 3.2 en portátiles modernos (por ejemplo, un Acer Swift Go 14 con procesador Snapdragon X Plus), el rendimiento ha sido más que aceptable. Mientras el modelo generaba un texto de unas mil palabras sobre temas complejos como la AGI, la CPU rondaba un 50 % de uso y la memoria RAM se mantenía en niveles razonables, sin que el sistema se volviera inestable.
Algo importante a tener en cuenta es que, en muchos casos, la NPU o motor de IA integrado no se utiliza cuando se ejecutan estos modelos a través de Ollama. El peso principal recae en la CPU (y, si está soportado y configurado, en la GPU). Esto significa que incluso equipos sin aceleradores de IA específicos pueden usar Ollama siempre que tengan suficiente RAM.
Si intentas cargar un modelo demasiado grande para la memoria de tu PC, como podría ser Gemma2:27B en un equipo con poca RAM disponible, lo más probable es que Ollama muestre un error avisando de que no ha sido posible ejecutar el modelo por falta de recursos. En ese caso toca bajar a una variante más pequeña o liberar memoria cerrando programas pesados.
Complemento perfecto: OpenWebUI como interfaz gráfica para Ollama
Aunque Ollama funciona de maravilla desde la terminal, a mucha gente le resulta más cómodo tener una interfaz web con ventanas de chat, soporte de Markdown, formato de código y demás florituras visuales. Ahí entra en juego OpenWebUI, un proyecto de código abierto que se integra con Ollama para ofrecer una experiencia muy similar a la de los chats de IA en navegador.
OpenWebUI es básicamente una interfaz gráfica para interactuar con tus modelos locales. Te permite escribir prompts en una ventana tipo chat, ver las respuestas con resaltado de código, usar LaTeX para fórmulas, gestionar parámetros del modelo de forma sencilla e incluso trabajar con funciones avanzadas como RAG (Recuperación Aumentada de Generación) para inyectar información externa.
La forma más habitual de desplegar OpenWebUI es mediante Docker. En Windows, esto suele implicar instalar primero Docker Desktop, que a su vez utiliza WSL (Windows Subsystem for Linux) como entorno. Una vez tienes Docker funcionando, lanzar OpenWebUI suele reducirse a ejecutar un comando docker run proporcionado por el propio proyecto.
La combinación típica es: Ollama como backend y OpenWebUI como frontend. Ollama corre en segundo plano gestionando los modelos, mientras que OpenWebUI ofrece la interfaz gráfica en tu navegador (normalmente a través de http://localhost:puerto). Desde ahí eliges el modelo, lanzas prompts, cambias parámetros y aprovechas todas las funciones de un entorno moderno.
Este enfoque es ideal si quieres algo más amigable que la línea de comandos o si vas a usar la IA con frecuencia para escribir, programar o estudiar. Puedes seguir tirando de terminal para tareas rápidas y recurrir a OpenWebUI cuando te apetezca un entorno más visual y organizado por conversaciones.
Ollama convierte tu PC con Windows en un laboratorio de IA local donde puedes probar modelos como Llama, DeepSeek, Phi, Qwen o Gemma sin depender de la nube, con total control sobre tus datos y sin necesidad de pagar suscripciones. Con un poco de práctica con la terminal y, si quieres, apoyándote en OpenWebUI para tener una interfaz cómoda, es fácil levantar en pocos minutos un entorno potente, privado y muy flexible para experimentar con modelos de lenguaje de última generación.