
Hay que decir que se están investigando gran cantidad de tecnologías y soluciones para el almacenamiento de datos muy variadas, como es el caso de tecnologías biotecnológicas como sería el ADN para poder codificar y decodificar datos binarios usando como medio cadenas de ADN sintético. Algo que tiene un gran potencial, aunque actualmente aún tenga sus limitaciones debido a los costes y la inmadurez de la tecnología.
Introducción

Usar elementos biológicos para la computación no es algo nuevo, ya se han propuesto multitud de conceptos muy diversos. Un ejemplo de ello, y también relacionado con el almacenamiento de la información es el concepto de la sangre como memristor es una idea que ha surgido recientemente en la comunidad científica y todavía se encuentra en una fase temprana de investigación.
Un memristor es un dispositivo electrónico que tiene la capacidad de cambiar su resistencia eléctrica en función de la cantidad de carga eléctrica que ha pasado por él en el pasado. Se cree que la sangre puede tener propiedades similares, ya que los glóbulos rojos, que son las células que transportan oxígeno en el cuerpo, tienen una respuesta eléctrica única debido a su forma y composición química.
Un estudio de hace unos años demostró que la sangre puede comportarse como un dispositivo memristor, lo que sugiere que podría ser utilizado en la construcción de dispositivos electrónicos biocompatibles y en la medicina personalizada.
Sin embargo, aún hay mucho que aprender sobre la sangre como memristor y se necesitan más investigaciones para determinar cómo se puede aprovechar esta propiedad de la sangre de manera efectiva. Además, cualquier aplicación práctica de esta idea también tendría que abordar las preocupaciones de seguridad y éticas asociadas con la manipulación de la sangre humana y su uso en dispositivos médicos.
Más recientemente, también se han hecho otras investigaciones no menos sorprendentes, como es el uso de una especie concreta de hongo como base para fabricar sistemas computacionales y de almacenamiento de datos. Esto lo han conseguido científicos de la UCL (Unconventional Computing Laboratory) de la Universidad del Oeste de Inglaterra. Y es que se sabe que estos organismos vivos pueden enviar señales a través de su red biológica para comunicarse con el subsuelo para obtener información o incluso con otros organismos circundantes.
Y, lo que a nosotros nos interesa aquí, el ADN sintético como memoria o medio de almacenamiento de datos…
¿Qué es el ADN sintético?

El ADN sintético es un tipo de material genético creado en laboratorios mediante la síntesis química de nucleótidos individuales. Estos nucleótidos se unen para formar cadenas de ADN sintético, que pueden programarse para contener secuencias específicas de información genética.
El ADN sintético se ha utilizado para crear organismos sintéticos, como bacterias, que contienen genomas completamente sintéticos. También se utiliza en la investigación científica y en la biotecnología para producir proteínas y enzimas específicas, así como para estudiar el impacto de ciertas mutaciones genéticas en los organismos. Y, en este caso que nos toca, también para almacenar datos, como medio informático.
La capacidad de crear ADN sintético tiene el potencial de revolucionar muchos campos de estudio, ya que los científicos pueden diseñar y construir genomas y sistemas biológicos personalizados para usos específicos, como la producción de medicamentos y la eliminación de contaminantes del medio ambiente. Sin embargo, el uso de la tecnología del ADN sintético también plantea preocupaciones éticas y de seguridad, y se están estableciendo regulaciones para garantizar su uso seguro y responsable.
Codificación

Como debes saber, la codificación de información es el proceso de transformar datos o información en un formato específico para su almacenamiento, transmisión o procesamiento. Este proceso implica la asignación de códigos o símbolos a los datos para que puedan ser interpretados por un sistema de comunicación o una máquina.
Por ejemplo, la codificación de información se utiliza en la comunicación digital para convertir los datos en una secuencia de bits (unos y ceros) que se pueden transmitir a través de un canal de comunicación. Un proceso fundamental en la tecnología de la información y la comunicación, y es esencial para el procesamiento, almacenamiento y transmisión de grandes cantidades de datos. Hay muchos tipos diferentes de técnicas de codificación de información, y la elección de una técnica particular depende del tipo de datos que se estén codificando y del uso previsto de los datos codificados.
Existen múltiples formas de codificar información en el ADN, pero los más eficientes son aquellos que emplean el ADN de manera económica y evitan errores en el proceso. Si se busca almacenar la información en ADN durante un largo periodo de tiempo, como 1000 años, es conveniente que la secuencia sea claramente artificial y que su lectura sea fácilmente identificable.
Uno de los posibles métodos de codificación propuestos para texto es la de usar una traducción de cada letra correspondiente mediante una cadena o secuencia única de nucleótidos de ADN mediante una tabla de búsqueda. Por ejemplo, se podrían usar códigos como Huffman.
También se podrían codificar otros datos diferentes a texto en el ADN, como los datos binarios (base 2), e incluso también datos ternarios o en base 3. Es decir, bits y «trits» que también se puede convertir en nucleótidos mediante una tabla de búsqueda. No obstante, no siempre es tan sencillo, ya que habría que solucionar problemas como los homopolímeros, es decir, nucleóticos repetidos que puedan causar errores en la información almacenada. Por ejemplo, se podría usar métodos de «corrección de errores» o para evitar ciertas confusiones usando nucleóticos de sincronización entre los nucleóticos que contienen información codificada, para separarlos o aislarlos.
En definitiva, gracias a las cadenas de ADN sintéticas, se puede usar varios métodos de codificación para almacenar datos de múltiples sistemas. Por poner un ejemplo práctico, hay que decir que durante el verano de 2019, algunos científicos lograron almacenar 16 GB de texto de la Wikipedia en lengua inglesa en un ADN sintético. Y dos años más tarde, otro equipo de científicos también mostró resultados de su desarrollo al crear un escritor de ADN capaz de escribir datos con una velocidad 18 Mbps.
Cómo funciona
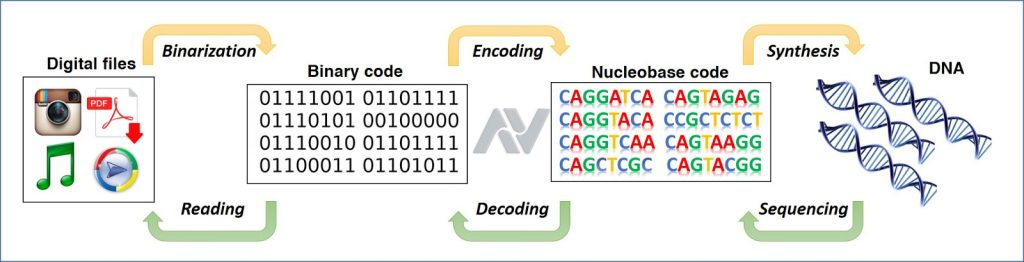
Tarjetas perforadas, cintas magnéticas, CDs, discos duros, unidades flash de estado sólido,… a lo largo de la historia hubo multitud de sistemas de almacenamiento de información. Ahora se investiga en el ADN que resolvería muchos problemas actuales.
A diferencia de otras unidades, que emplean magnetismo para almacenar los datos, o señales eléctricas, etc., en el caso del ADN se emplea moléculas o secuencias de ADN para almacenar la información. Cuando se codifica en base a nucleótidos de ADN, tenemos A, C, G y T.
En el Ácido DesoxirriboNucleico (ADN), tenemos una molécula orgánica compleja con información genética que está presente en todos los seres vivos y que determina el color de la piel, de sus ojos, la altura, y otras muchas características.
La espiral de ADN tiene tres pares múltiples y alternos de cuatro bases únicas:
- Adenina (A)
- Guanina (G)
- Citosina (C)
- Timina (T)
Los pares se agrupan como adenina-timina y guanina-citosina, es decir, A-T y G-C. En este tipo de sistemas se almacenará la información en permutaciones de tres bases de nucleóticos que se denominan codones.
Para poder almacenar datos en ADN se necesitan tres pasos básicos:
- Codificar los datos
- Sintetizar los datos y almacenarlos
- Decodificarlos
Por ejemplo, los datos binarios se puede traducir en códigos o codones de ADN mediante un algoritmo. Estos elementos pueden ser congelados, almacenarse en gotitas y otros elementos, e incluso en chips.
Sin embargo, por el momento, esto es una práctica compleja y cara, que necesita de bastante tiempo para la escritura y lectura con las prácticas actuales, además de suponer retos para codificar sin errores. Por eso, faltan muchos años para ver soluciones basadas en ADN en el mercado…
Capacidad
El ADN solucionaría multitud de problemas de almacenamiento actuales, puesto que si maduran estas tecnologías se podrían almacenar grandes cantidades de datos en muy poco espacio. Por ejemplo, se estima de en un gramo de ADN se podrían almacenar hasta 215 Petabytes. Eso quiere decir que en la milésima parte de un gramo de ADN se podría almacenar hasta 215 TB de información, mucho más que en el disco duro más avanzado de la actualidad. Además, un disco duro actual de 1 TB puede pesar unos 400 gramos y tiene un volumen mucho mayor.
Ventajas
Por supuesto, el ADN tiene grandes ventajas a la hora de almacenar información digital como puedes observar, y las más destacables son:
- Densidad de almacenamiento: el ADN puede almacenar información con una altísima densidad, lo cual sería fantástico para centros de datos, por ejemplo, que verían cómo el espacio necesario se reduciría de forma masiva.
- Durabilidad: también se estima que estos medios de almacenamiento pueden ser extremadamente duraderos, y poder almacenar la información de muchos años, como mínimo unos 500 años.
- Replicabilidad: podría resolver también el problema de la degradación o pérdida de datos que ahora se solventa mediante sistemas RAID o redundantes. Con el ADN se podría copiar la información de forma rápida.
Aplicaciones del ADN como método de almacenamiento de datos
Hay que destacar que esta tecnología de almacenamiento de datos en ADN puede tener varias aplicaciones prácticas interesantes, como:
Cyborg
Antes hemos comentado sobre el ADN sintético, pero, si esta tecnología madura, ¿imaginas el potencial que tendría para usarlo dentro de código genético de organismos vivos, como las personas. Podría hacer posible cyborgs de todo tipo, e incluso con fines médicos mediante la edición de genes con CRISPR para insertar secuencias de ADN artificial en el genoma celular.
Criptodivisas en ADN
Durante el foro Davos Bitcoin Challenge, parte del Foro Económico Mundial, Nick Goldman, el EBI (Instituto Europeo de Bioinformática) europeo, mostró tubos con ADN que contenían las claves privadas para poder obtener un bitcoin. De esta forma, se demostró poder secuenciar y codificar este tipo de información en ADN, lo que podría revolucionar el mundo de los pagos.
Bibliotecas en ADN
Imaginas tener una bliblioteca codificada en ADN? Pues deja de imaginar, unos investigadores de la Arch Mission Foundation, usó información para llevar información de una biblioteca lunar que se lanzó en un módulo de aterrizaje Bereshit. Y los investigadores aseguran que se podría leer incluso cuando hayan pasado miles de millones de años.
DoT
Además de IoT (Internet of Things) o Internet de las Cosas, también llega ahora la revolución del DoT (DNA of Things), es decir, el paradigma del ADN de las cosas promulgado por un equipo de investigadores de Israel y Suiza. La idea es codificar información en ADN para luego incrustar estas moléculas en objetos.
Almacenamiento a largo plazo
Por ejemplo, se podría usar ADN para poder almacenar datos de forma duradera y segura, ya que estas moléculas tienen una gran estabilidad química, que podría durar siglos e incluso milenios. Una gran ventaja, por ejemplo, para almacenar datos importantes como archivos gubernamentales, documentales históricos, archivos de museos, bibliotecas, copias de seguridad de Internet, etc.
Sistemas de almacenamiento de alta densidad
También se puede usar ADN para almacenamiento de alta densidad, por ejemplo para centros de datos, que ahorrarían mucho espacio. También podría ser positivo para futuros viajes espaciales con tripulación, donde se podría guardar toda la información que se quisiese en un pequeño tamaño, con tamaño reducido para no perjudicar a la nave.
Un poco de historia
La idea de usar ADN como medio de almacenar datos digitales se remonta a los años 1959, con el físico prestigioso Richard Feynman. Entonces, en una de sus obras, llegó a predecir esta tecnología. Sin embargo, no fue hasta mediados de los 60 cuando Mikhail Samoilovich Neiman, un físico soviético, publicó 3 artículos sobre la electrónica a nivel molecular en la que se proponían moléculas de ADN y ARN sintéticas para ello.
Los primeros usos del almacenamiento en ADN no llegaron hasta 1988, cuando el artista Joe Davis e investigadores de Harvard hicieron un experimento para almacenar una imagen del artista en una secuencia de ADN de una bacteria E.coli. La imagen era una runa germánica antigua que representaba la vida y la Tierra femenina. La codificación empleada era muy simple, con píxeles oscuros representados por unos y píxeles claros representados por ceros.
En 2007, la Universidad de Arizona, también usaría moléculas de ADN para almacenar información codificada que se podía leer. En 2011, George Church, Sri Kosuri y Yuan Gao llevaron otro experimento para codificar y almacenar un libro de 659 KB del que Church era coautor para meterlo dentro de un ADN usando adenina o citosina para los unos y guanina y timina para los ceros binarios. Sin embargo, tras examinar el ADN se encontraron 22 errores en él.
El mismo George Church, y otros colegas de la Universidad de Harvard, un año más tarde de aquel logro, también lograron incluir un código HTML con un libro de 53400 palabras, 11 imágenes en formato JPG, y un programa JavaScript.
Casi en paralelo, en Europa, el EBI (European Bioinformatic Institute) también presentó otro gran avance en este sentido al codificar, almacenar y recuperar más de 5 millones de bits de datos. En este caso, la recuperación de la información se pudo captar con una precisión de entre el 99,99% y el 100%, lo cual no resultó tan problemático como en el caso de los americanos, que encontraron bastantes errores.
Poco a poco la tecnología iba mejorando. No obstante, aún necesitaba más maduración, ya que la información almacenada en ese ADN se guardó repetida 4 veces para evitar errores., lo cual no es lo ideal. Además, los costes por MB estimado fueron de 12400 dólares, y unos 220$ para poder leer dichos datos, lo que es un precio totalmente desorbitado y que no se puede permitir si se necesita una solución factible basada en ADN.
DNACloud fue otro de los grandes desarrollos que aparecieron en 2013. Se trataba de un software creado por Manish K. Gupta y otro equipo de colaboradores. Se empleó un algoritmo propuesto por Goldman para mejorar la eficiencia de almacenamiento de memoria y poder codificar y decodificar los datos del ADN.
En 2015 llegarían otras investigaciones que certificaban la gran capacidad y estabilidad del ADN para almacenar datos a largo plazo. La investigación la hizo un equipo del ETH Zurich alemán. Además, este equipo usó redundancia de datos para mejorar la fiabilidad, usando codificación con corrección de errores Reed-Solomon, y encapsulando el ADN en esferas de vidrio de silice para hacerlas más duraderas.
Church, del que ya hemos hablado anteriormente, y Technicolor Research and Innovation, durante 2016 lograrían almacenar y recuperar 22 MB de secuencia de una película. Era el primer vídeo grabado en ADN, y se empleó formato MPEG para ello. Al tratar de recuperar la información se lograría obtener el vídeo completo sin errores. Texto, imágenes, código, vídeo,…todo estaba progresando.
Un año más tarde, Yaniv Erlich y Dina Zielinski, de la Universidad de Columbia y el Centro de Genoma de Nueva York respectivamente, publicaron un nuevo método con el que almacenar en alta densidad para almacenar 215 Petabytes de información por cada gramo de ADN, como ya adelanté anteriormente. Esta técnica alcanzaría un 85% del límite teórico de almacenamiento en ADN, aunque seguía siendo un problema para el uso de forma masiva o a gran escala, ya que costó 4500 dólares codificar y almacenar 1 MB de información y 1000$ leerlos.
Durante mediados de 2018, Microsoft junto con la Universidad de Washington, también demostraron el potencial de almacenamiento y recuperación del ADN con datos de 200 MB. A pesar de que no eran mucho, el objetivo era acelerar el tiempo de acceso a estos datos de forma aleatoria. Y, un año más tarde, ese mismo equipo anunciaría que había conseguido implementar un sistema automático de codificación y decodificación para ADN.
Eurecom y el Imperial College, también presentaron una investigación publicada en 2019 en el que demostraron la capacidad de almacenar datos estructurados en una secuencia de ADN sintético, lo cual podría ser de gran ayuda para el uso de bases de datos, además de demostrar que se podían realizar operaciones de procesamiento de datos similares a las de SQL mediante procesos químicos en el ADN.
El mismo año, TurboBeads Labs de Suiza y Mezzanine de Massive Attack, lograron codificar información del primer álbum almacenado en ADN sintético. También hubo otro grupo de científicos que lograrían almacenar 16 GB de la Wikipedia con texto en inglés en ADN, como he comentado anteriormente.
CATALOG lograría crear un escritor de ADN personalizado capaz de almacenar datos a una velocidad de 18 Mbps, un logro alcanzado en 2021. Un año más tarde de que se descubriera la forma de mellas enzimáticas y con posibilidad de registrar información y realizar los accesos bit a bit.
Se pensaba que en 2023 la tecnología de almacenamiento de ADN estaría suficientemente madura como para ser barata, pero lo cierto es que hemos llegado a este punto y no han habido grandes avances al respecto. Aún sigue quedando mucho por resolver y mejorar.
Conclusión
El almacenamiento de ADN podría solucionar muchos problemas, y aportar dispositivos de almacenamiento muy duraderos y con densidades de capacidad muy elevadas. Sin embargo, aún es una tecnología costosa, y que tiene problemas para realizar las lecturas y escrituras. Por tanto, aún queda mucho por mejorar…