- Rubin CPX es una GPU para IA de contexto masivo con 30 PFLOPS NVFP4 y 128 GB GDDR7.
- NVL144 CPX alcanza 8 ExaFLOPS, 100 TB y 1,7 PB/s, 7,5× sobre GB300 NVL72.
- Dual Rack mantiene 8 ExaFLOPS y sube a 150 TB para contextos aún más largos.
- Pila de software con Dynamo, Nemotron y AI Enterprise para producción.

La apuesta de NVIDIA por la IA no es nueva, pero con Rubin CPX el listón sube varios peldaños: hablamos de una GPU pensada para ventanas de contexto masivas, 128 GB de GDDR7 y hasta 30 PFLOPS en NVFP4, además de integraciones de vídeo en el propio chip. Todo ello llega dentro de una estrategia de plataforma más amplia, con configuraciones de rack que empujan el rendimiento a cotas de exaescala y una pila de software completa para llevar la inferencia desagregada a producción.
En los últimos años, la compañía ha virado del gaming (sin abandonar su legado) a priorizar el hardware de IA. Tras el impulso de Blackwell para centros de datos en 2024 y el posterior lanzamiento de RTX 50 para consumo en 2025, ahora es el turno de Vera Rubin CPX, NVL144 CPX y la solución Rubin CPX Dual Rack, presentadas con el objetivo de acelerar modelos que trabajan con millones de tokens, desde generación de vídeo a asistentes de programación de gran escala.
Qué es Nvidia Rubin CPX y por qué ahora

Rubin CPX es una nueva clase de GPU CUDA orientada específicamente a la IA de contexto masivo, es decir, a modelos que deben razonar con enormes ventanas de información de manera simultánea. NVIDIA la define como una GPU diseñada para que los sistemas procesen y comprendan millones de tokens a la vez, algo clave para tareas como la ingeniería de software a gran escala o el análisis y generación de vídeo de formato largo.
Para lograrlo, la compañía introduce en el propio chip un conjunto de capacidades que antes quedaban repartidas: decodificadores y codificadores de vídeo integrados (NVDEC y NVENC) junto con hardware optimizado para inferencia con secuencias extensas. En números, Rubin CPX ofrece hasta 30 PetaFLOPS de cómputo en precisión NVFP4 y una memoria de 128 GB basada en GDDR7 con un enfoque de coste/eficiencia superior frente a HBM en este segmento.
Uno de los puntos más singulares es la aceleración de la atención: Rubin CPX proporciona una atención 3 veces más rápida respecto a la GB300 de Blackwell. Esto permite ampliar el contexto sin sufrir penalizaciones de velocidad, elevando el techo práctico para inferencias largas en despliegues reales.
Además, Rubin CPX encaja en un enfoque de infraestructura orientado a la inferencia desagregada. El pre-llenado de contexto (prefill) y la fase de generación se pueden dividir y optimizar por separado para aprovechar mejor el cómputo y la memoria. Esto resulta esencial cuando la aplicación maneja secuencias muy largas y cargas de trabajo mixtas entre comprensión y creación de contenido.
- Hasta 30 PFLOPS NVFP4 para inferencia eficiente a gran escala.
- 128 GB GDDR7 para cargas de contexto extendidas con mejor equilibrio coste/rendimiento.
- 4 NVENC + 4 NVDEC integrados, orientados a pipelines de vídeo de alta demanda.
- Atención 3× más rápida que GB300, facilitando ventanas de contexto más largas sin fricciones.
En palabras de Jensen Huang, la plataforma Vera Rubin abre una categoría de procesadores denominados CPX para impulsar un salto en computación de IA. Es una declaración de intenciones por parte de NVIDIA: así como RTX transformó los gráficos y la IA física, Rubin CPX apunta a dominar la IA con contexto masivo, con modelos que manejan conocimiento a escala de millones de tokens.
Arquitectura, memoria y rendimiento: NVFP4, GDDR7 y vídeo integrado

Rubin CPX utiliza un diseño de matriz monolítico cargado de recursos NVFP4, una precisión que maximiza el rendimiento y la eficiencia energética en inferencia moderna. Esta elección encaja con las necesidades de latencia y throughput en producción, permitiendo a los proveedores de servicios y empresas optimizar costes operativos.
La memoria es otro pilar clave: 128 GB de GDDR7. Frente a las soluciones centradas en HBM, NVIDIA posiciona esta elección como una alternativa muy competitiva en precio para cargas de trabajo de contexto extenso. El objetivo es claro: hacer viable un volumen de tokens gigantesco sin disparar el coste por servidor ni sacrificar ancho de banda.
En el terreno multimedia, Rubin CPX integra NVENC y NVDEC junto al propio motor de inferencia de contexto largo en un único chip. Esto permite pipelines donde la decodificación de vídeo, el pre-procesamiento y la inferencia conviven sin tener que saltar entre dispositivos ni saturar buses, algo vital para casos de uso como la búsqueda en vídeo a gran escala o el vídeo generativo.
Para dimensionar el reto, NVIDIA recuerda que una hora de contenido de vídeo puede consumir hasta un millón de tokens. Son cifras que empujan a la GPU tradicional al límite si no se combinan cómputo, memoria y video engines en armonía. De ahí la aproximación convergente de Rubin CPX, que se remata con optimizaciones específicas en la ruta de atención y en el manejo de secuencias extensas.
La compañía también subraya que Rubin CPX se ofrece en forma de tarjetas para integrar en servidores o equipos dedicados, además de formar parte de sistemas completos de rack. Esta flexibilidad facilita su adopción tanto en centros de datos nuevos como en entornos que quieran actualizar gradualmente su infraestructura.
Vera Rubin NVL144 CPX y Rubin CPX Dual Rack: 8 ExaFLOPS, memoria masiva y redes a la carta
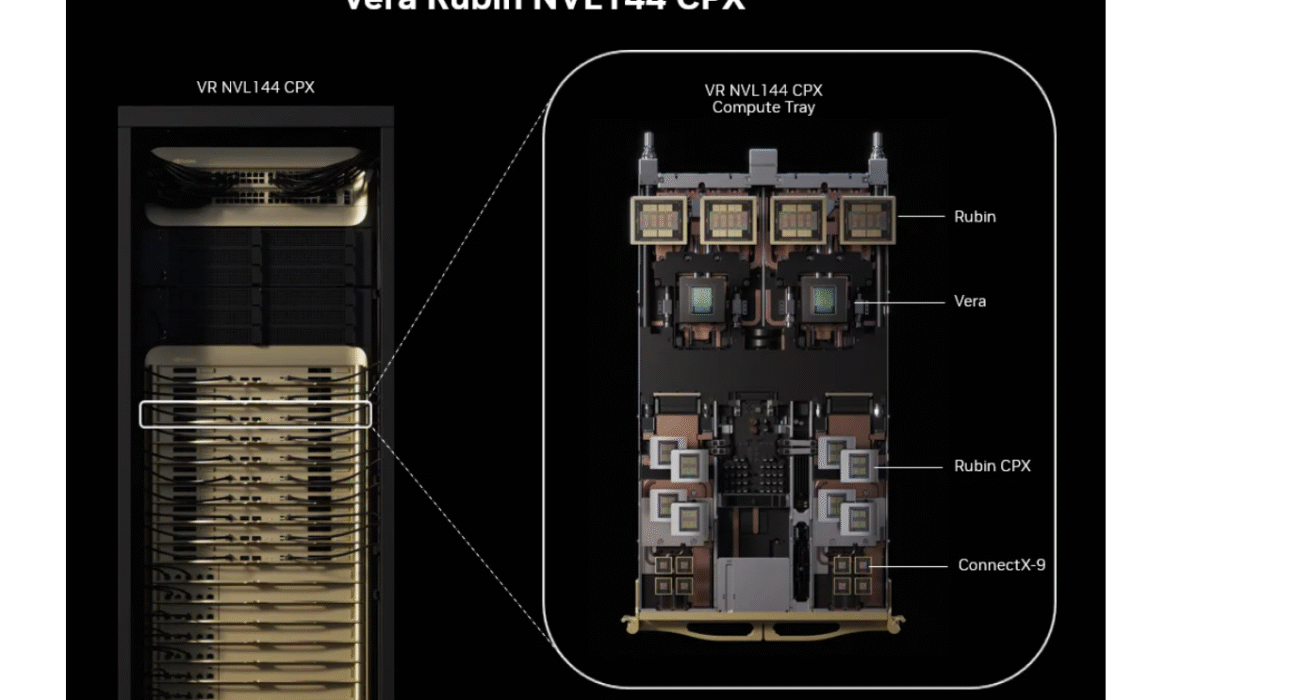
Más allá de la tarjeta individual, NVIDIA ha presentado Vera Rubin NVL144 CPX, un sistema de rack que combina dos módulos Vera Rubin para alcanzar la descomunal cifra de 8 ExaFLOPS NVFP4. Según la compañía, esto supone ser 7,5 veces más rápido que los sistemas GB300 NVL72 de la generación anterior en cargas de IA comparables.
El impacto no se queda en el cómputo: 100 TB de memoria ultrarrápida y un ancho de banda de 1,7 PB/s por rack, con un salto de aproximadamente 3× en velocidad frente a la iteración pasada. Este cóctel está pensado para despliegues que exijan contexto masivo y latencias ajustadas, manteniendo la escalabilidad de la plataforma.
Para quienes necesiten aún más densidad de memoria, aparece la Rubin CPX Dual Rack Solution, que combina un rack con Rubin CPX y otro con Vera Rubin NVL144. El resultado vuelve a marcar los 8 ExaFLOPS de potencia y el ancho de banda de 1,7 PB/s, pero eleva la memoria a 150 TB, un incremento que, según NVIDIA, cuadruplica lo visto en la generación previa.
En networking, la plataforma ofrece integración con NVIDIA Quantum-X800 InfiniBand o con NVIDIA Spectrum-X Ethernet, incluyendo tecnología Spectrum-XGS Ethernet y los NVIDIA ConnectX-9 SuperNICs. De este modo, cada despliegue puede alinearse con la pila de red preferida y mantener la eficiencia extremo a extremo en inferencia desagregada.
Estas configuraciones se enmarcan en la nueva plataforma NVIDIA Vera Rubin NVL144 CPX, donde las CPU NVIDIA Vera trabajan junto a las GPU Rubin. Además, NVIDIA contempla una bandeja de cómputo Rubin CPX para clientes que quieran reutilizar sistemas Vera Rubin 144, facilitando actualizaciones con el menor roce posible.
Como referencia de negocio, la compañía llega a cuantificar el retorno potencial: con Vera Rubin NVL144 CPX se podrían alcanzar 5.000 millones de dólares en ingresos por tokens por cada 100 millones invertidos, un mensaje nítido para organizaciones que pretenden monetizar IA generativa a gran escala con largas ventanas de contexto.
Casos de uso, ecosistema de software y adopción por la industria

Rubin CPX pretende transformar a los asistentes de programación desde simples generadores de fragmentos de código a sistemas que comprenden repositorios completos, detectan dependencias y optimizan proyectos complejos. El procesamiento de contexto largo es la base para pasar de respuestas puntuales a un razonamiento más holístico sobre bases de código grandes.
En vídeo, la historia es similar. Con decodificación, codificación y procesamiento de inferencia en el mismo chip, se habilitan pipelines para búsqueda de vídeo, análisis de escenas y generación de contenido cinematográfico con más fidelidad. El objetivo es combinar calidad y escala sin que el cuello de botella se desplace a la interconexión entre dispositivos.
NVIDIA ha señalado varios socios de referencia. Runway aprovechará la tecnología para potenciar la creación audiovisual y efectos visuales a una escala inédita. Cursor, con su editor de código con IA, ve en Rubin CPX un aliado para elevar la productividad del desarrollador con herramientas contextuales avanzadas. Magic, por su parte, trabaja en modelos fundacionales para agentes capaces de automatizar ingeniería de software de forma más amplia y fiable.
Todo esto se sustenta en el stack de software de la casa. NVIDIA Dynamo promete escalar la inferencia, aumentar el throughput y, al mismo tiempo, reducir latencias y costes de servicio. En la capa de modelos, la familia NVIDIA Nemotron aporta capacidades multimodales y razonamiento de vanguardia listas para agentes empresariales.
Para despliegues productivos, NVIDIA AI Enterprise ofrece un paquete con microservicios NIM, frameworks, librerías y herramientas para nubes, centros de datos y estaciones de trabajo aceleradas por NVIDIA. Este ecosistema se apoya en décadas de innovación con CUDA-X, una comunidad de más de 6 millones de desarrolladores y cerca de 6.000 aplicaciones CUDA que ya forman parte del catálogo.
En cuanto a calendarios, NVIDIA fija la llegada de Rubin CPX para finales de 2026. La ventana temporal encaja con una hoja de ruta en la que, en años previos, se priorizaron lanzamientos de IA para centros de datos (como Blackwell) y posteriormente se abordaron las gamas de consumo con RTX 50.
Hay otro punto operativo importante: Rubin CPX también se entregará en tarjetas para integrarse en servidores o equipos dedicados no necesariamente atados a un chasis completo de rack. Sumado al ecosistema MGX y a la compatibilidad con redes de alto rendimiento, permite escalar desde nodos discretos a racks completos según la fase del proyecto o el presupuesto.
En paralelo, NVIDIA plantea comparativas ambiciosas. Frente a GB300, Rubin CPX logra 3× en aceleración de atención, mientras que la referencia de rack NVL144 CPX escala hasta ser 7,5× más rápida que GB300 NVL72. En memoria y ancho de banda, los saltos hasta 100 TB y 1,7 PB/s por rack marcan un antes y un después para el prefill y la inferencia con corpora gigantes.
La narrativa de negocio refuerza el foco en monetización por tokens: la propia NVIDIA apunta a que, con NVL144 CPX, es posible capturar ingresos a escala multimillonaria en proyectos de IA generativa. Este énfasis conecta con la idea de que el máximo rendimiento por token es la métrica que importa cuando se sirven contextos largos al por mayor.
Si volvemos al vídeo, el dato de que una hora de contenido pueda implicar hasta un millón de tokens ayuda a entender por qué Rubin CPX combina engines de vídeo con cómputo NVFP4 y memoria GDDR7 de alta capacidad. En lugar de fragmentar el pipeline, la GPU concentra las piezas críticas para sostener calidad, latencia y coste.
Para ingeniería de software, el salto es cualitativo: con más contexto disponible y mejores tiempos de respuesta, los asistentes dejan de “olvidar” partes del sistema y pasan a razonar con vistas de proyecto completas. Esto tiene un impacto directo en refactorizaciones, auditorías de seguridad, control de dependencias y generación de documentación técnica más coherente.
El enfoque de inferencia desagregada encaja especialmente bien en estos dominios. Separar el pre-llenado del contexto de la fase de generación permite dimensionar la infraestructura de forma granular y aprovechar diferentes perfiles de cómputo y memoria, lo que reduce cuellos de botella y mejora la utilización del hardware.
Por último, la compatibilidad de la plataforma con Quantum-X800 InfiniBand y Spectrum-X Ethernet (junto con Spectrum-XGS y las ConnectX-9 SuperNICs) permite que cada organización ajuste la red a su realidad operativa, sea un entorno con baja latencia extrema o uno que priorice flexibilidad y coste.
Mirando el conjunto, Rubin CPX se presenta como una pieza diseñada a conciencia para servir IA de contexto masivo: cómputo NVFP4 de alta densidad, memoria GDDR7 amplia, aceleración de atención, engines de vídeo en chip y una plataforma de rack que dispara el rendimiento a exaescala con 100–150 TB de memoria rápida y 1,7 PB/s de ancho de banda por rack. Su llegada prevista a finales de 2026 apunta a marcar el ritmo de la próxima gran etapa de la infraestructura de IA.
