Seguro que si llevas unos años en el mundo de la informática habrás escuchado alguna vez sobre el FSB, sin embargo, también te habrás percatado de que actualmente ya no se escucha o emplea ese término. ¿Por qué? ¿Ha desaparecido? Pues aquí te resolvemos todas tus dudas…
¿Qué es el FSB?

El FSB (Front-Side Bus), también denominado bus frontal, es un tipo de bus de comunicación que se usaba en los sistemas basados en Intel entre 1990 y 2000. En el caso de AMD, se empleó el bus EV6, que cumplía la misma función y que muchos denominaban igual. Sin embargo, mientras el FSB era un desarrollo propio de Intel, el EV6 fue licenciado por DEC para que los Athlon de AMD pudieran usarlo, ya que es una tecnología de Digital Equipment Corp para sus Alpha.
Tanto en un caso como en el otro, este bus suele comunicarm o servir de interfaz, entre la CPU y el controlador de memoria RAM o northbridge. Además, dependiendo de la implementación, como algunos procesadores de Intel más antiguos, también tenían un bus trasero o BSD (Back-Side Bus), que servía para comunicar la memoria caché con la CPU. Este otro bus era más rápido que el FSB.
Historia del FSB
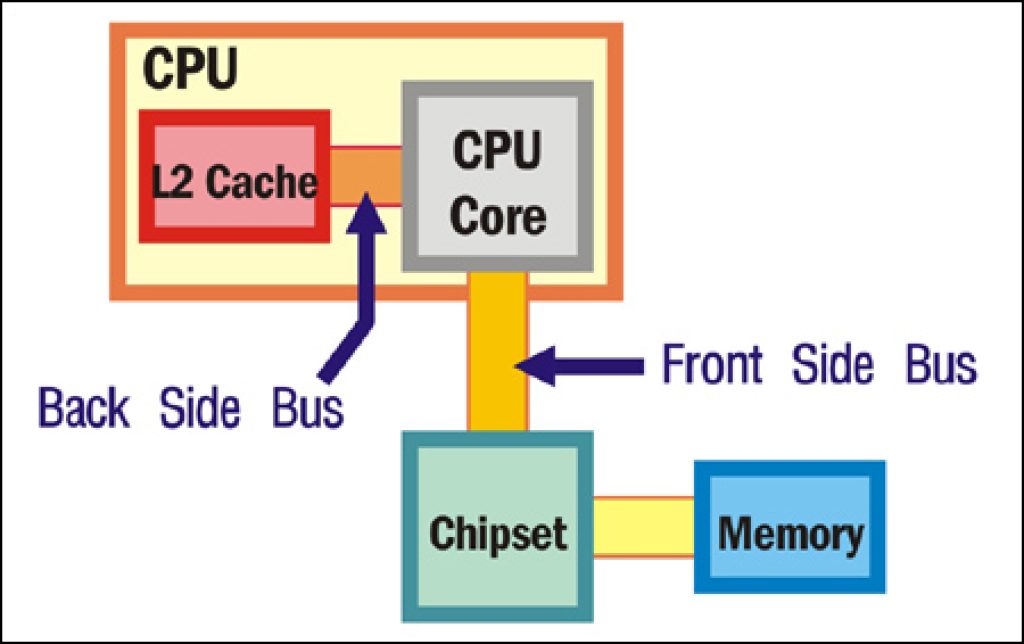
Intel presentó el FSB junto con su Pentium Pro y Pentium II, en la década de 1990. El término frontal se refiere a que es una interfaz externa al procesador, comunicando la CPU con la memoria RAM.
El FSB se usó en placas base para PC y también para servidores basados en los Intel Xeon de esta época. Pero no se empleaba en sistemas embebidos, con algunas excepciones.
Además, el FSB fue una mejora de rendimiento frente al bus del sistema único que se usaba en las décadas anteriores. Sin embargo, como sustituyó al bus del sistema, el FSB y EV6 eran denominados en ocasiones «bus de sistema».
El bus del sistema era un bus simple usado entre los años 70 y 80 para la comunicación de los diferentes componentes de un ordenador. Este bus tenía unas líneas denominadas bus de datos que llevaba datos, unas líneas denominadas bus de direcciones para transportar direcciones de memoria, y también otras líneas denominadas bus de control para enviar señales de control. Tanto la CPU, como la memoria RAM, como el sistema E/S estaban conectados a este bus, y así se producían las comunicaciones entre todos los elementos.
En el caso del FSB, generalmente conectaba también la CPU con el resto del hardware con ayuda del chipset, con el northbridge para enlazar con la memoria RAM y con la interfaz para gráficos, y con el southbridge para conectar con otros periféricos. Por esto, si se realizaba overclocking en la velocidad de reloj del FSB, también afectaba a otros buses o interfaces del sistema, que eran aceleradas (CPU, memoria RAM, bus AGP, bus PCI).
Para superar las limitaciones del FSB o EV6, AMD creó una iniciativa con nombre clave Torrenza (de la que derivarían tecnologías como HyperTransport). E Intel terminaría abriendo el FSB para ser usado por terceros.
Es cierto que el FSB tenía sus ventajas, como su gran flexibilidad y bajo coste de diseño, pero no podía escalar como se esperaba y generó cuellos de botella. No obstante, Intel siguió usándolo para sus Intel Atom, los Celeron, Pentium, Core 2 y Xeon hasta aproximadamente 2008, cuando le buscaría un sustituto.
Conforme la CPU se hacía cada vez más rápida, su potencial se veía lastrado por el FSB, porque no podía obtener instrucciones y datos tan rápidamente como necesitaba. Por eso comenzaron a surgir críticas, especialmente por parte de AMD, que catalogó el FSB como una tecnología antigua y lenta que limitaba el rendimiento.
Entonces AMD desarrollaría uno de los buses más poderosos de la época, el HyperTransport, usado para sus Athlon64 y Opteron, entre otros modelos de CPU. Intel se daría cuenta de su error y también trató de crear sus propios buses, como DMI y QPI que han estado usando sus procesadores hasta nuestros días. Y así es como finalmente moría el FSB…
¿Qué es el System bus o bus del sistema?
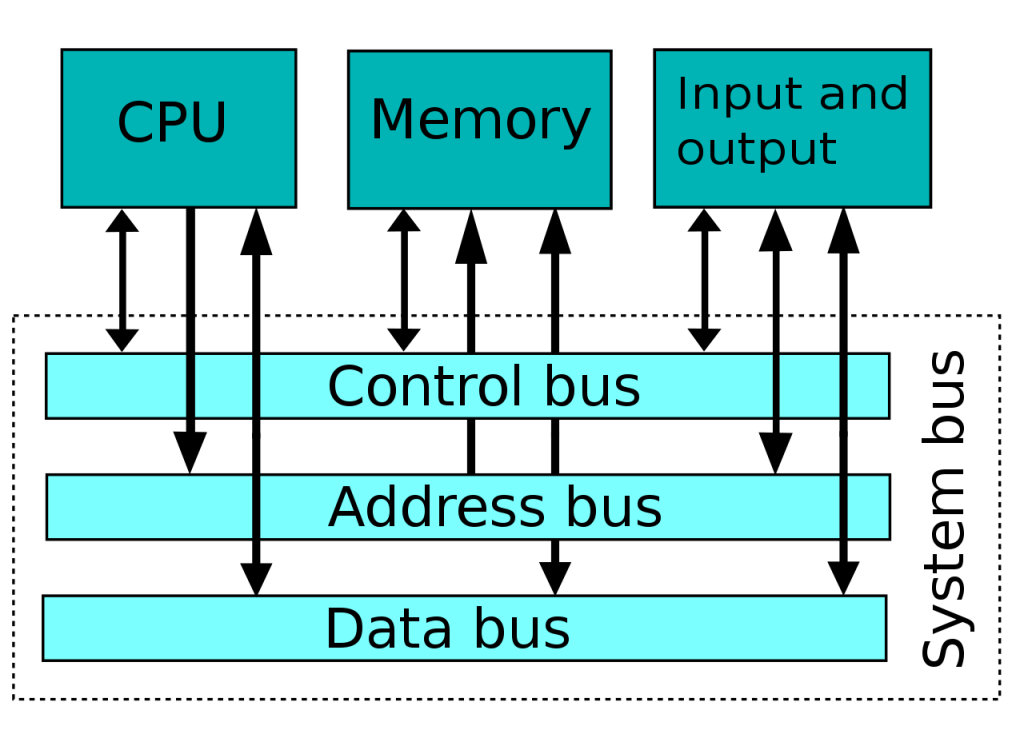
El bus de sistema o system bus, es un bus único que servía para conectar los componentes principales de un ordenador. Para ello, se dividía en tres buses fundamentales:
- Bus de datos: se componía de un ancho suficiente para poder transportar datos/instrucciones del procesador al que acompañaba. Es decir, si era un procesador de 16-bit, el ancho era de 16-bit para poder transportar entre la CPU y el resto del sistema los datos que manejaban los programas.
- Bus de direcciones: en este caso, es un bus para transportar solo direcciones de memoria, a las que se debía acceder, ya fuesen del espacio de la memoria RAM o del sistema de E/S para periféricos. Es decir, éste determinaba dónde debía enviarse o leerse el dato que sería transportado por el bus anterior.
- Bus de control: este otro estaba dedicado a determinar las operaciones que había que hacer. Este bus no hay que confundirlo con el bus de instrucciones, sino que lo que llevaba era una serie de líneas de control como las que indicaban si se tenía que leer o escribir en la memoria, etc.
¿Qué es DIB?
El término DIB (Dual Independent Bus) también está relacionado con todo esto, ya que fue un término empleado por Intel cuando sustituyó al bus del sistema por un FSB y un BSB. De ahí su nombre. Es decir, tenemos un bus externo para conectar con la memoria principal y el E/S, y un bus interno para conectar con la memoria caché L2. Así se implementó en el Pentium Pro de 1995.
Sin embargo, entre 2005 y 2006, Intel introdujo un chipset de la serie 8500 y 5000 donde la empresa también usó el término DIB, pero esta vez para referirse a dos buses frontales que duplicaban el ancho de banda del sistema, es decir, tenían dos FSB.
Esto no solo tenía ventajas, ya que para mantener la coherencia de la caché, se debía verificar el estado en el otro FSB, lo que al final reducía el ancho de banda disponible por estas comprobaciones. Pese a este problema, Intel siguió usando su idea de usar múltiples buses para el chipset 7300 de 2007. En este caso tenía cuatro FSB independientes a lo que Intel llamaría DHSI (Dedicated High Speed Interconnections).
Finalmente, un año más tarde, se daría cuenta de que AMD llevaba razón y el concepto de FSB estaba totalmente obsoleto.
¿Qué es HyperTransport?
HyperTransport o HTT (previamente conocido como Lighthing Data Transport), es una tecnología de interconexión desarrollada por AMD para sus Athlon64/Opteron en adelante. Este bus serviría como reemplazo del FSB/EV6 anterior, y se trataba de un punto de enlace bidireccional y que podía actuar tanto en serie como en paralelo, además de tener un gran ancho de banda y baja latencia.
Hubo gran confusión en la época con AMD HyperTransport y la tecnología Intel HT o HyperThreading. Muchos medios la describían como el equivalente de AMD para la tecnología SMT de Intel, pero nada más lejos de la realidad. Debido a estas confusiones, el consorcio siempre usó HyperTransport sin abreviar.
Se introdujo por primera vez en 2001, y AMD abrió esta tecnología, creando así HyperTransport Consortium, con miembros interesados en usar este bus como IBM, Apple, MIPS, Broadcom, Cisco, NVIDIA, PMC-Sierra, Sun Microsystem (ahora Oracle), Transmeta y muchos más, completando más de 50 miembros. Apple, por ejemplo, lo usó para sus Mac basados en la CPU Power Mac G5.
Para hacerte una idea de su potencial, el FSB de Intel más potente de todos, llegó a los 400 Mhz, esto significaba:
8 bytes/transfer × 400 MHz × 4 transferencias/ciclo = 12800 MB/s
En cambio, si tenemos en cuenta la versión HyperTransport 3.1, que usaba enlaces completos de 32-bit y utilizaba velocidades de 3.2 Ghz, tenemos que:
3.2 Ghz x 2 transferencias/ciclo x 32-bit/enlace = 25.6 GB/s por cada dirección (51.2 GB/s bidireccional)
| Versión de HTT | Año | Frecuencia máxima | Ancho de enlace máximo | Bidireccional (GB/s) | Unidireccional 16-bit (en GB/s) | Unidireccional 32-bit (en GB/s) |
|---|---|---|---|---|---|---|
| 1.0 | 2001 | 800 MHz | 32 bits | 12.8 | 3.2 | 6.4 |
| 1.1 | 2002 | 800 MHz | 32 bits | 12.8 | 3.2 | 6.4 |
| 2.0 | 2004 | 1,4 GHz | 32 bits | 22.4 | 5.6 | 11.2 |
| 3.0 | 2006 | 2,6 GHz | 32 bits | 41.6 | 10.4 | 20.8 |
| 3.1 | 2008 | 3,2 GHz | 32 bits | 51.2 | 12.8 | 25.6 |
Como puedes ver, esto es mucho más rápido que el anterior bus, lo cual supuso un gran avance para procesadores para PC, y también para servidores y HPC. De hecho, superó a la mayoría de estándares de la época. Y no solo eso, era un bus eficiente (compatible con los estados D y C de ACPI), agregó codificación, se basaba en paquete (conjunto de palabras de 32-bit), bidireccional para poder transferir en ambas direcciones a la vez, no necesitaba adaptadores para conectarse a los buses estándar (PCIe, AGP,…), con un solo chip adaptador puede funcionar con muchos microprocesadores, etc.
Aunque el objetivo inicial del HyperTransport era sustituir al FSB de Intel, y se empleó para el Opteron, Athlon64, Athlon64 X2, Turion64, Sempron, Phenom, Phenom II, y FX, pero finalmente también daría el paso a usarse para otros fines, ya que es bastante flexible y potente. Por ejemplo, se usaría también para enrutadores y conmutadores de red, para interconectar coprocesadores o FPGAs, etc.
Además, HyperTransport Consortium también lanzaría un conector que permitía a cualquier periférico basado en ranura que tuviera una conexión directa con el microprocesador mediante el bus HyperTransport. Esto se conocía como HTX o HyperTransport Xpansion. Esto sería usado para sistemas HPC por diveras empresas muy conocidas.
El éxito de HTT se puede apreciar en la enorme cantidad de productos que lo usaron, como los de AMD, pero también ATI y NVIDIA en aquella época para los chipsets, Broadcom (ServerWorks) y SiByte, para procesadores de red Cisco QuantumFlow, para proyectos de OpenCores, para IBM PowerPC 970, para las CPUs chinas Loongson, para las CPUs PMC-Sierra RM9000X2, para el Apple Power Mac G5, para los Transmeta Efficeon TM8000, para los chipsets de VIA serie K8, etc.
¿Qué es Infinity Fabric?
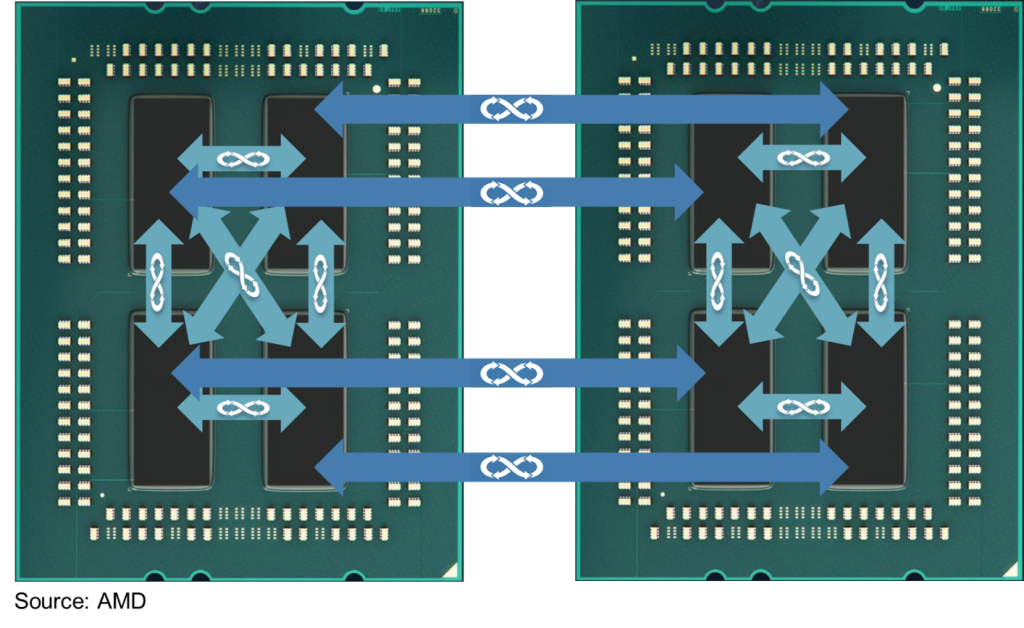

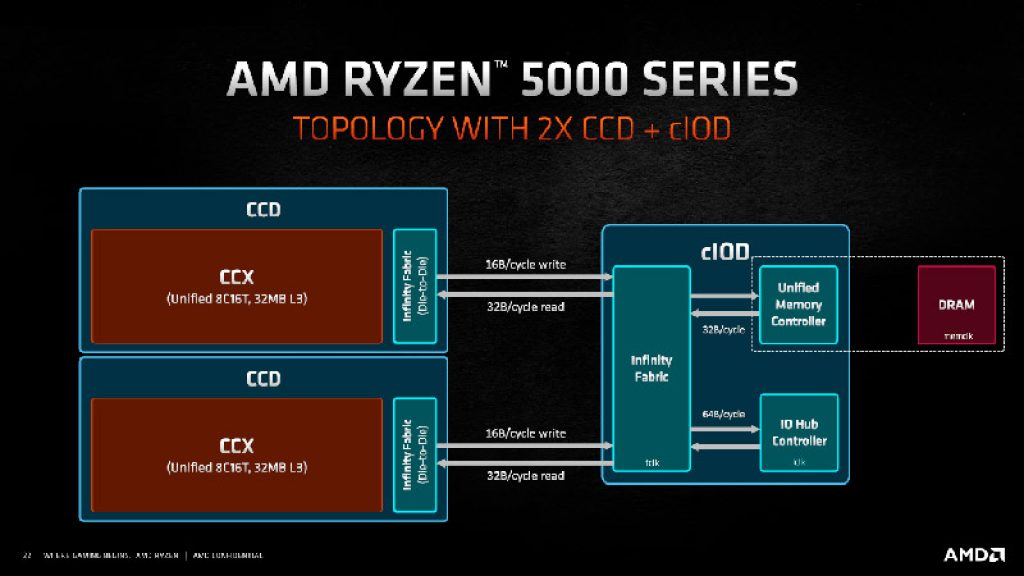
Otro uso que se le dio a HyperTransport fue para interconectar microprocesadores en sistemas MP o multiprocesador basados en NUMA. Para ello, HyperTransport empleó una extensión que podía mantener la coherencia de caché para los Opteron y Athlon64 FX con doble zócalo. Y de aquí evolucionaría a lo que hoy se denomina Infinity Fabric, empleado en los nuevos AMD Ryzen y EPYC.
Aunque Infinity Fabric parezca una tecnología totalmente nueva, no lo es. De hecho, no es más que un superconjunto de HyperTransport. Así que se puede decir que HyperTransport sigue viva en nuestros días. Y no solo para conectar entre unidades MP, también entre los propios núcleos de CPU o entre los CCD/CCX y el cIOD.
Infinity Fabric (IF) fue anunciado por AMD en 2016, para interconectar CPU y GPU en sus arquitecturas heterogéneas, es decir, para las APU de 2017. En este momento, la compañía aseguró que podría escalar IF desde 30 GB/s hasta los 512 GB/s, y se introdujeron términos como SDF para la frecuencia para las interconexiones de datos y la MEMCLK para la frecuencia de reloj de la memoria RAM, aunque ambas usaban la misma frecuencia para evitar la latencia causada por las diferencias de velocidad. Como resultado, usar un módulo RAM más rápido hace que también el bus sea más rápido, ya que se adapta a ello.
Por otro lado, en estos nuevos procesadores Zen y Zen+, se empleó un ancho de 32-bit como en HTT. Pero se realizan 8 transferencias por ciclo en vez de 2, y con paquetes de 128-bit. También había mejoras a nivel electrónico para mejorar la eficiencia energética. Además, más tarde, con la aparición de Zen 2 y Zen 3, se duplicó el ancho a 64-bit, y el bus IF usa una frecuencia de reloj separada, en proporciones 1:1 o 2:1 con respecto a la frecuencia de la memoria RAM. Esto fue debido a los problemas en Zen y Zen+ con las memorias RAM de alta velocidad que afectaban al IF, subiendo demasiado la frecuencia y perjudicando la estabilidad.
¿Qué es QPI?
Intel QPI (QuickPath Interconnect) es otro tipo de bus punto a punto desarrollado para competir con HyperTransport de AMD. Intel inicialmente se refería a él como CSI (Common System Interface) y los primeros desarrollos se denominaban YAP (Yet Another Protocol) y YAP+. Incialmente sería para los Xeon, Itanium y las CPUs para escritorio.
Intel lanzaría QPI en 2008 con su familia de procesadores Intel Core i7 de primera generación y los chipsets X58. Fue usado por los procesadores Nehalem, Tukwila (Itanium), y Sandy Bridge.
Al igual que HyperTransport, QuickPath asume que la CPU tiene el controlador de memoria integrado, por lo que en los sistemas multiprocesador se usará la arquitectura NUMA.
También hay que resaltar que QPI usa dos conexiones punto a punto de 20-bit, una para cada dirección, y puede manejar un total de 42 señales. Cada señal es un par diferencial, formando así un 84. En cuanto a la velocidad, puede llegar a los 6.4 GT/s por cada dirección, con un ancho de banda de 16 GB/s por dirección, lo que hace un total de 32 GB/s. Eso significa el doble de ancho de banda teórico de un FSB.
QPI solo tuvo una versión, la v1.0… y después de eso se pasaría a usar DMI.
Intel UPI
Tras el poco éxito de QPI, Intel trató de poner solución con un bus denominado UPI (Ultra Path Intereconnect), que pretendía sustituir al QPI para plataformas Intel Xeon Skylake-SP a partir de 2017. También era una conexión punto a punto, con baja latencia, mantiene la coherencia en sistemas MP, mejora la eficiencia de QPI, y puede conseguir velocidades de transferencia de hasta 10,4 GT/s. A esto hay que agregar que los procesadores compatibles usan dos o tres enlaces UPI en paralelo.
¿Qué es DMI?
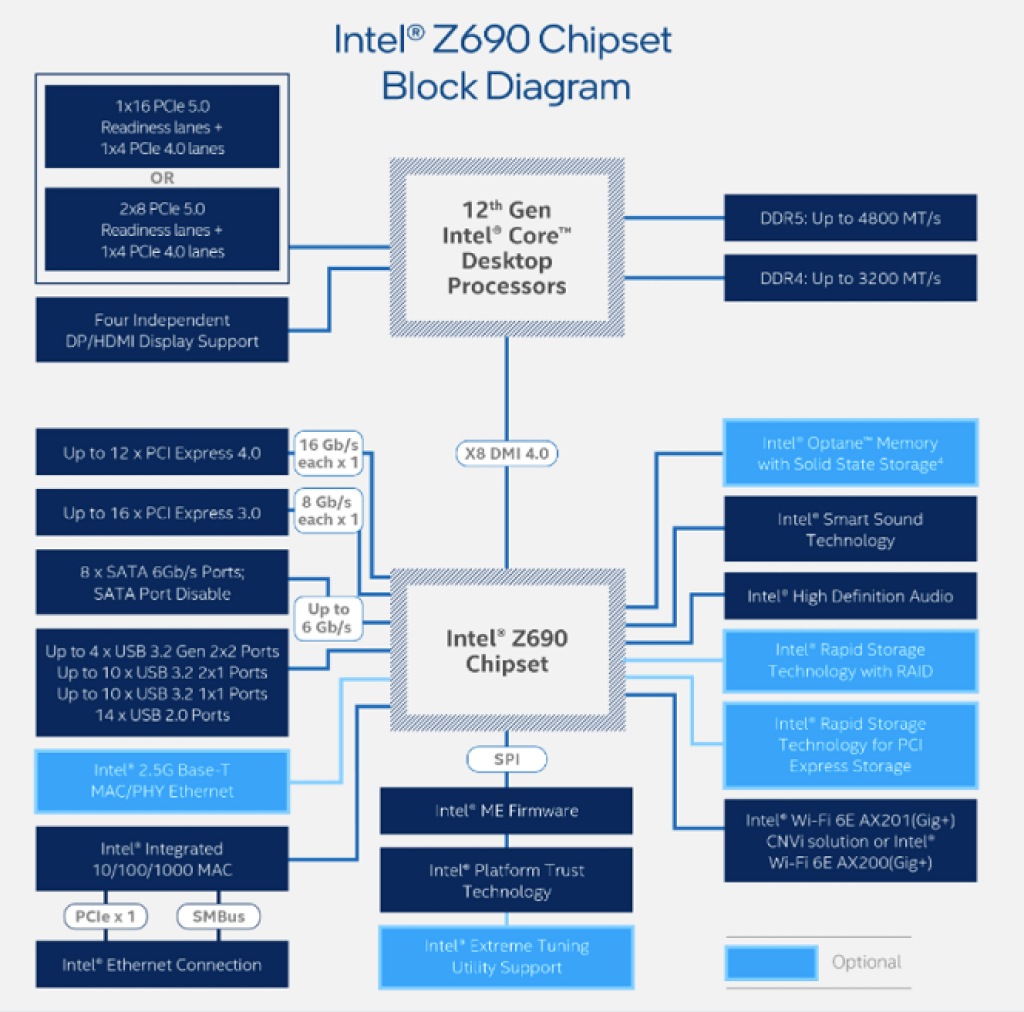
Intel DMI (Direct Media Interface) es un tipo de bus propietario de Intel que sirve para enlazar el northbridge y el southbridge de la placa base. Se usó por primera vez en el chipset 9xx y en el ICH6 lanzado en 2004. Anteriormente a esto, se había usado Intel Hub Architecture para realizar esta misma función, pero se sustituyó por este otro bus que también tuvo una interfaz similar denominada ESI (Enterprise Southbridge Interface) especialmente para servidores y HPC.
Además, cuando el northbridge fue absorbido por la CPU, entonces ahora se usa como sustituto del FSB, ya que interconecta CPU con el chipset.
Según la versión, este bus serie de Intel podía tener diferentes velocidades. Con 2 GT/s para la v1.0, 4 GT/s para la v2.0, 8 GT/s para la v3.0, y 16 GT/s para la v4.0 por carril. Por otro lado, hay que decir que comparte muchas características con PCI Express, al usar multiples carriles y señalización diferencial.
Mientras la DMI 1.0 original alcanzaba 1 GB/s de transferencia de datos, con enlaces de x2 o x4, la DMI 2.0 introducida en 2011 duplicaba hasta los 2 GB/s con x4 carriles para vincular la CPU de Intel y el PCH (Platform Controller Hub). Después llegaría la DMI 3.0 en 2015, con 3,93 GB/s, empleado en procesadores como Intel Skylake y sus variantes. En 2021 llegaría DMI 3.0 con x8 carriles para los chipset de la serie 500. Y este mismo año, en noviembre, se lanzó DMI 4.0 para los chipsets 600 Series y que duplica el ancho de banda del 3.0, y permite usar diferente número de carriles según el modelo del conjunto de chips.
¿Qué es Intel Mesh?

Intel Mesh Interconnect Architecture es otra nueva arquitectura de interconexión crada por Intel para sus sistemas multinúcleo. Este bus en forma de malla emplea una línea bidireccional escalable, síncrona y de un gran ancho de banda pensada para servidores y HPC.
Como sabrás, en 2000 Intel trató de usar la arquitectura de conexión en anillo para unir varios núcleos físicos de manera eficiente. Sin embargo, a medida que aumentaba el rendimiento de los núcleos en los modelos de gama alta, Intel necesitaba algo superior, ya que comenzaba a tener problemas de ancho de banda y latencia sobre 2010.
Por esto, Intel decidió usar una red de malla como bus para interconectar estas unidades. Y lo hizo basándose en sus proyectos experimentales previos como su CPU Polaris 80 de 2007, que era un manycore, y que finalmente derivaría en loss Intel Xeon Phi (Knights Landing). Además, los Intel Xeon Skylake de 2017 también tendrían una arqutiectura de malla que serviría de base. No obstante, la Intel Mesh fue empleada por primera vez para los Xeon Scalable, para Intel Core i7 y Core i9…para unir núcleos entre sí.
¿Qué es AMBA?
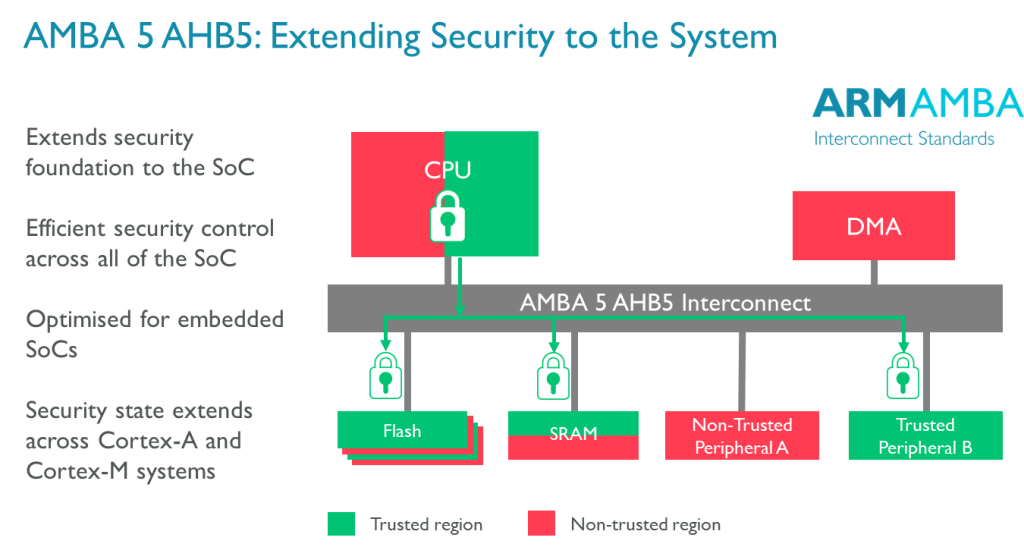
El bus del sistema puede incluso ser interno en un chip o circuito integrado en el caso de los SoC, como es el caso de AMBA, CoreConnect y Wishbone. En este apartado nos centraremos en AMBA (Advanced Microcontroller Bus Architecture) de ARM.
Esta especificación de bus para la interconexión entre los distintos bloques de un SoC es un estándar abierto y cuya marca registrada es propiedad de Arm. Se introdujo en 1996 y los primeros buses en emplear este estándar fueron ASB (Advanced System Bus) y APB (Advanced Peripheral Bus).
Más tarde, en 1999 llegaría AMBA 2, agrgando AHB (Advanced High-performance Bus) en esta segunda generación. En 2003 se introduciría AMBA 3, que incluyó AXI (Advanced eXtensible Interface) y ATB (Advanced Trace Bus) para agregar mayor rendiemiento en las interconexiones. En 2010 se introduciría la especificación AMBA 4, con una nueva extensión en 2011 para matener la coherencia. Y, finalmente, en 2013 llegaría AMBA 5 con CHI (Coherence Hub Interface) con una capa de transferencia de alta velocidad rediseñada y nuevas características para reducir la congestión. Este protocolo es el estándar de facto en las actuales arquitecturas y se puede usar sin necesidad de pagar regalías.
¿Qué es CoreConnect?
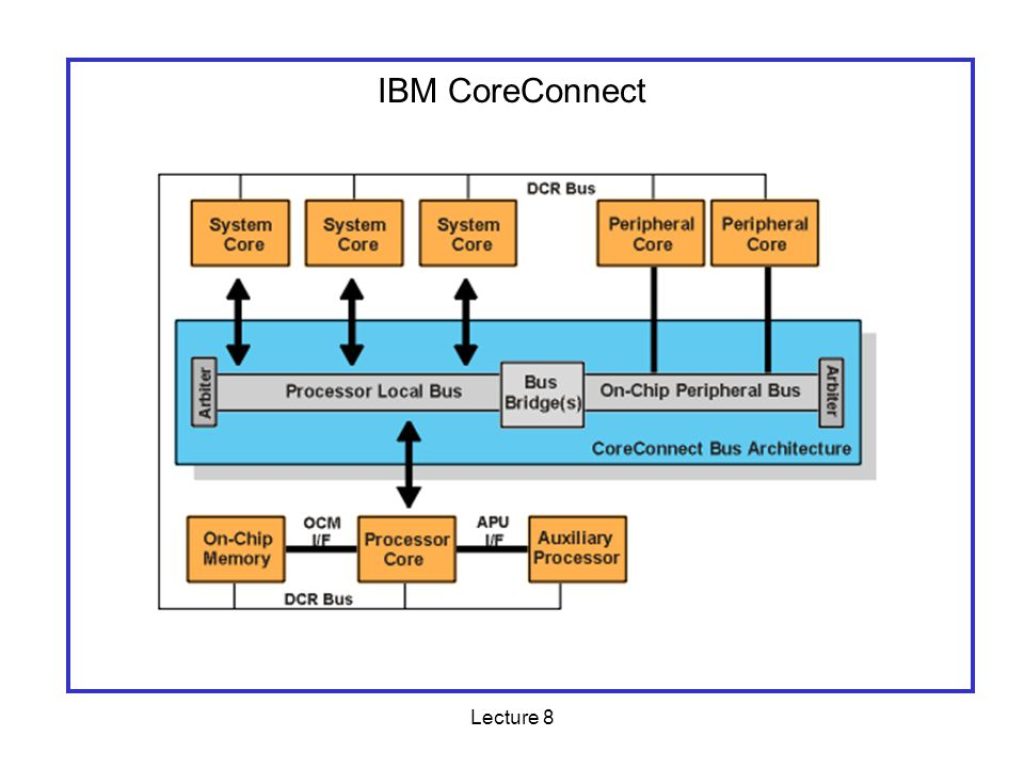
Por otro lado, CoreConnect también es un tipo de bus del sistema para microprocesadores IBM diseñado para SoC (estándar y personalizados), por lo que también puede ser usado para SoC no IBM.
CoreConnect incluye varios elementos en su arquitectura de interconexión, como:
- PLB (Processor Local Bus): los periféricos de alto rendimiento se conectarán a este bus de alto ancho de banda y baja latencia.
- OPB (On-chip Peripherical Bus): aquí se conectan los periféricos más lentos, para reducir el tráfico en el PLB.
- DCR (Device Control Register): es un registro para el control del bus.
- Y un puente de bus, incluso puede servir de puente con AMBA de la competencia, lo que permite reutilizar otros elementos de terceros.
El bus CoreConnect está a disposición de cualquier empresa, con herramientas de desarrollo, IP, etc., sin ningún tipo de regalías. Por eso, más de 1500 empresas lo han empleado para sus productos, como Nokia, Synopsys, Siemens, Lucent, Ericsson y Cadence. Por supuesto, también se usó en las CPUs IBM PowerPC 4×0 y en algunos dispositivos de Xilinx (ahora AMD).
¿Qué es Wishbone bus?
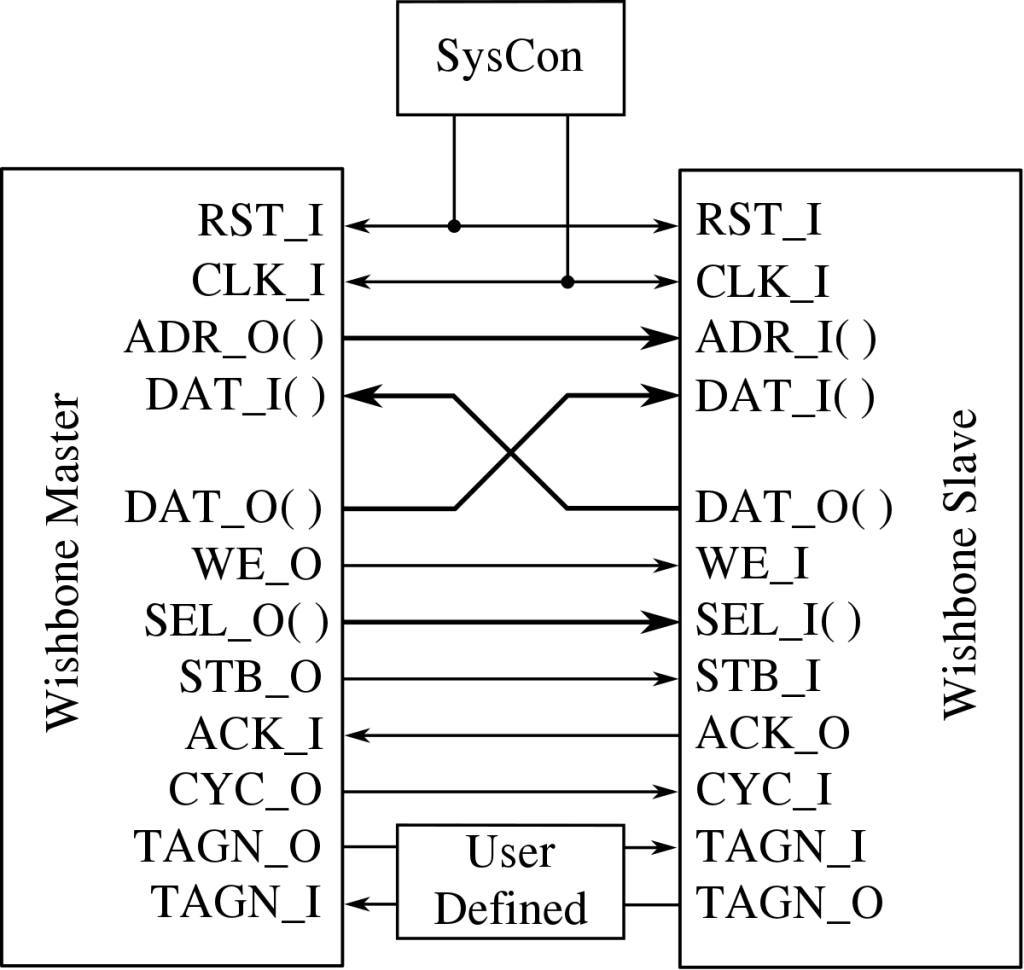
Para finalizar, también tenemos el bus Wishbone desarrollado por Silicore Corporation. Se trata de un hardware de código abierto destinado a comunicar varias partes de un circuito integrado entre sí. Es decir, como AMBA y CoreConnect, se emplea como bus del sistema dentro de un solo chip. Dado su caracter abierto, es empleado por muchos diseños de OpenCores/LibreCores.
Existe una versión simplificada derivada de la especificación Wishbone conocida como SBA o Simple Bus Architecture.
Wishbon es un bus paralelo, pensado como un bus lógico, sin especificar información eléctrica ni topología de bus. Está diseñado en términos de señales. Esto permite que los diseñadores puedan tener mayor flexibilidad o versatilidad cuando diseñen sus dispositivos usando VHDL, Verilog o cualquier otro lenguaje de descripción de hardware.
Por otro lado, Wishbone puede tener anchuras de 8, 16, 32 y 64-bit y todas las señales serán síncronas, con un solo reloj. Además, emplea un sistema Master/Slave para funcionar.
Los comentarios están cerrados.